手把手教你用 Python 绘制酷炫的桑基图!




桑基两个字取自“发明”者的名字
属于流程图的一种,核心在于展示数据的流转
主要由节点、边和流量三要素构成,边越宽代表流量越大
遵循守恒定律,无论怎么流动,开端和末端数据总是一致的
文字太苍白,下面我们用Python来绘制一个具体的实例。




from pyecharts.charts import Sankeyfrom pyecharts import options as optspic = (Sankey().add('', #图例名称nodes, #传入节点数据linkes, #传入边和流量数据#设置透明度、弯曲度、颜色linestyle_opt=opts.LineStyleOpts(opacity = 0.3, curve = 0.5, color = "source"),#标签显示位置label_opts=opts.LabelOpts(position="right"),#节点之前的距离node_gap = 30,).set_global_opts(title_opts=opts.TitleOpts(title = '熬夜原因桑基图')))pic.render('test.html')

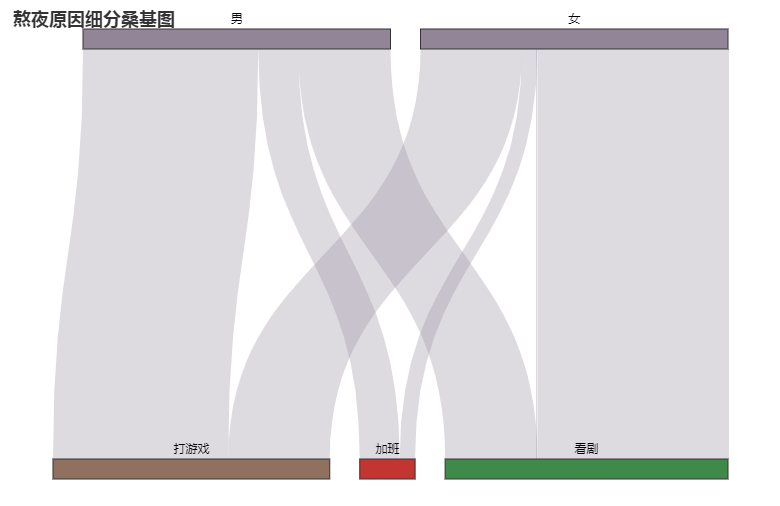
pic = (Sankey().add('',nodes,linkes,linestyle_opt=opts.LineStyleOpts(opacity = 0.3, curve = 0.5, color = "source"),label_opts=opts.LabelOpts(position="top"),node_gap = 30,orient="vertical", #更改的是这里).set_global_opts(title_opts=opts.TitleOpts(title = '熬夜原因细分桑基图')))pic.render('test2.html')




pic = (Sankey().add('',nodes,linkes,linestyle_opt=opts.LineStyleOpts(opacity = 0.3, curve = 0.5, color = 'source'),label_opts=opts.LabelOpts(position = 'top'),node_gap = 30,).set_global_opts(title_opts=opts.TitleOpts(title = '客户购买路径流转图')))pic.render('test3.html')

出于试错成本的考量,大部分客户第一次购买的是小规格狗粮。 第一次购买小规格狗粮的客户,流失(第二次未购买)情况严重,且再次购买客户,更倾向于继续选择小规格狗粮尝试,而不是信任性的购买大规格狗粮。 第一次购买大规格狗粮的客户,留存下来的客户已经建立起对品牌的信任感,再次购买大部分选择了大规格狗粮。 购买狗粮的客户第二次复购鲜有尝试玩具的,而第一次购买玩具的客户,也并未建立起对品牌狗粮的兴趣。

☞Spark3.0发布了,代码拉过来,打个包,跑起来!| 附源码编译

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 习近平引领网信事业高质量发展 4902817
- 2 中国人民解放军信息支援部队成立 4958128
- 3 伊朗总统发声未提及伊斯法罕爆炸 4802432
- 4 一季度农业农村经济“开门稳” 4758843
- 5 大熊猫吃笋整出了扛炮筒的架势 4686248
- 6 女孩被男同学开黄腔 妈妈巧妙处理 4506037
- 7 五一调休考虑过单休的人吗 4442777
- 8 杨幂美甲事件引争议 4305876
- 9 广西白沙大道一大楼倒塌系谣言 4213439
- 10 王婆说媒现场男子与女主播起冲突 4132859