Python分析101位《创造营2020》小姐姐,谁才是你心中的颜值担当?


来源 | CDA 数据分析师
责编 | Carol
Show me data,用数据说话。
今天我们聊一聊《创造营2020》各个小姐姐,点击下方视频,先睹为快:
最近可以追的综艺真是太多了,特别是女团选秀节目。之前我们刚聊过《青春有你2》,现在隔壁鹅厂的《创造营2020》又火热开播了。除了数不清的漂亮小姐姐,导师团除了黄子韬、鹿晗,最新一期中吴亦凡更是作为特约教练登场,“归国三子”一下子就引爆了话题度。


《创造营2020》到底好看吗?
那么,《创造营2020》到底好看吗?先让我们看到豆瓣,目前已经有25129人打分,分数为6.6分。

对比起隔壁的《青你2》5.2分,创造营还略胜一筹,不过刚更新3期,还可以在观望一下。

总体评分分布

具体看到总体评分分布,其中11.8%的人给了5星,19.6%的人给了4星,其中打1星的最多占到39.8%。
其中给出1分2分算评分较差的,4分5分算比较好的推荐分数。我们分布看到这两部分评分的词云图。
在评分较低的观众看来,主要的吐槽点有关于"赛制"、"导师"、"剪辑"方面。直接表达"不好看"、"劝退"、"吊打"的评论也有不少。

在给出分数较高,推荐的观众看来,《创造营2020》的亮点在于"选手小姐姐"、"导师阵容"、"话题"。鹅厂的"财大气粗"、"燃烧的经费"也令人印象深刻。其次也有认为比《青你2》要更好看的。


数据获取
数据预处理:数据合并和字段提取
数据可视化分析
从腾讯的官方助力网站,来获取选手的姓名和照片信息
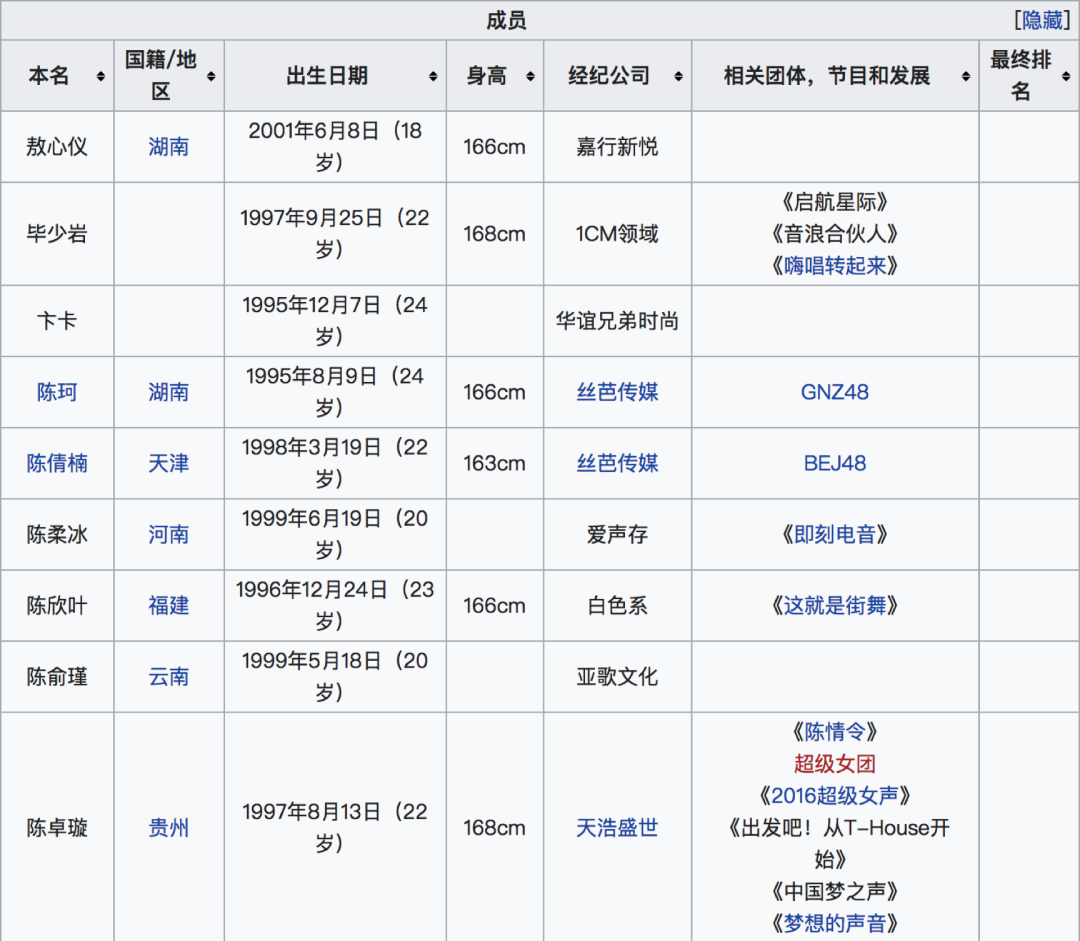
从维基百科获取选手的籍贯、年龄、身高、所在经济公司信息
调用百度智能云的AI人脸识别接口,输入选手照片,获取选手颜值等信息。
获取腾讯撑腰榜数据
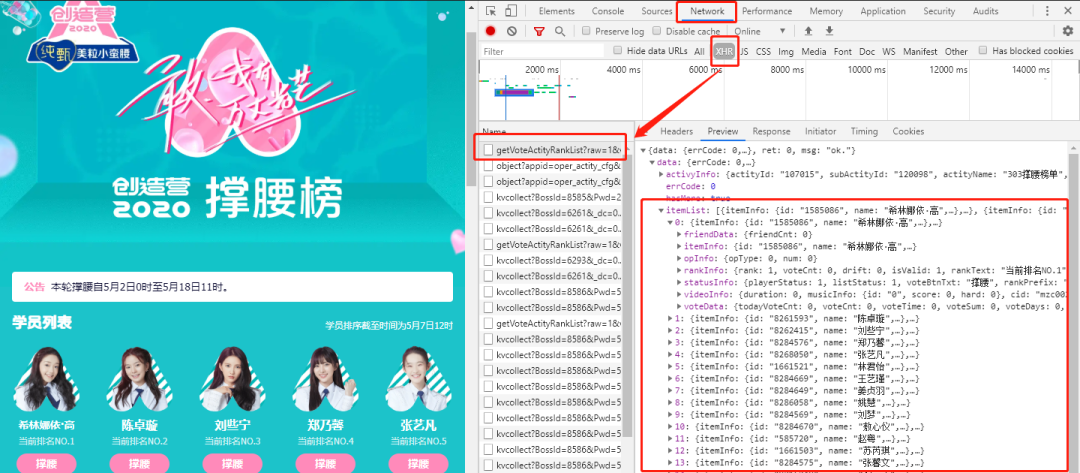
# 导入库
import pandas as pd
import requests
import json
def get_tx_actors():
"""
功能:获取创造营2020撑腰榜数据。
"""
# 获取URL
url = 'https://zbaccess.video.qq.com/fcgi/getVoteActityRankList?raw=1&vappid=51902973&vsecret=14816bd3d3bb7c03d6fd123b47541a77d0c7ff859fb85f21&actityId=107015&pageSize=101&vplatform=3&listFlag=0&pageContext=&ver=1&_t=1589598410618&_=1589598410619'
# 添加headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
# 发起请求
response = requests.get(url, headers=headers)
# 解析数据
json_data = json.loads(response.text)
# 提取选手信息
player_infos = json_data['data']['itemList']
# 提取详细信息
names = [i['itemInfo'].get('name') for i in player_infos]
rank_num = [i['rankInfo'].get('rank') for i in player_infos]
images = [i['itemInfo']['mapData'].get('poster_pic') for i in player_infos]
# 保存信息
df = pd.DataFrame({
'names': names,
'rank_num': rank_num,
'images': images
})
return df
df1.head()

获取维基百科数据
df2.head()

调用百度AI接口获取颜值数据
def get_file_content(file_path):
"""
功能:使用base64转换路径编码
"""
with open(file_path, 'rb') as fp:
content = base64.b64encode(fp.read())
return content.decode('utf-8')
def get_face_score(file_path):
"""
功能:调用api,实现一个百度的颜值分析器
"""
# 调用函数,获取image_code
image_code = get_file_content(file_path=file_path)
# 请求base_url
request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
# 表单数据
params = {
'image':'{}'.format(image_code),
'image_type': 'BASE64',
'face_field': 'age,gender,beauty'
}
# 调用函数,获取token
my_access_token = "官网获取的个人的token信息"
# 获取access_token
access_token = my_access_token
# 构建请求URL
request_url = request_url + "?access_token=" + access_token
# 请求头
headers = {'content-type': 'json'}
# 发起请求
response = requests.post(request_url, data=params, headers=headers)
if response:
print(response.json())
age = response.json()['result']['face_list'][0]['age']
gender = response.json()['result']['face_list'][0]['gender']['type']
gender_prob = response.json()['result']['face_list'][0]['gender']['probability']
beauty = response.json()['result']['face_list'][0]['beauty']
all_results = [age, gender, gender_prob, beauty]
return all_results
df3.head()

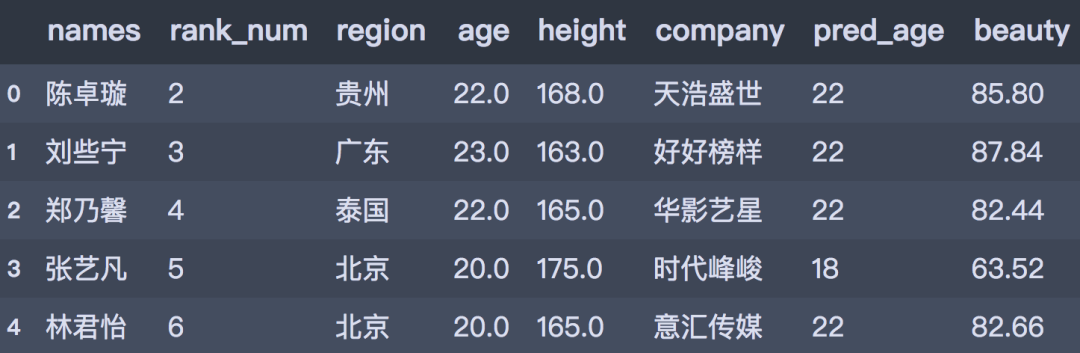
df.head()
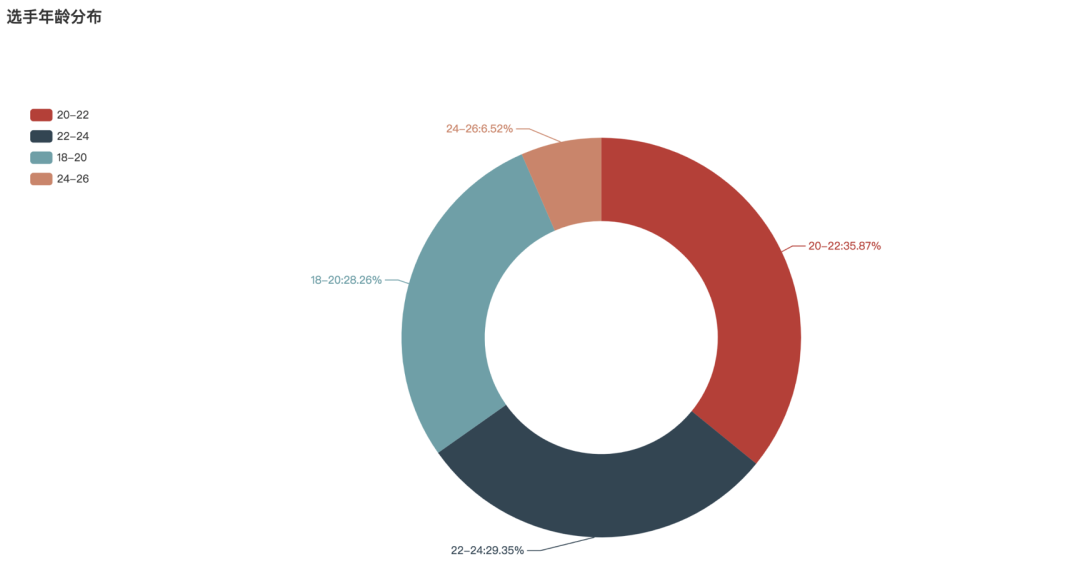
选手的年龄分布
# 分箱
age_bins = [18,20,22,24,26]
age_labels = ['18-20', '20-22', '22-24', '24-26']
age_cut = pd.cut(df.age, bins=age_bins, labels=age_labels)
age_cut = age_cut.value_counts()
# 产生数据对
data_pair = [list(z) for z in zip(age_cut.index.tolist(), age_cut.values.tolist())]
# 绘制饼图
# {a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add('', data_pair=data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='选手年龄分布'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.render()

# 产生数据
x1_line2 = df.names.values.tolist()
y1_line2 = df.age.values.tolist()
y2_line2 = df.pred_age.values.tolist()
# 绘制折线图
line2 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))
line2.add_xaxis(x1_line2)
line2.add_yaxis('真实年龄', y1_line2)
line2.add_yaxis('预测年龄', y2_line2)
line2.set_global_opts(title_opts=opts.TitleOpts('选手的真实年龄和百度AI预测对比'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate='30')),
yaxis_opts=opts.AxisOpts(min_=15, max_=30),
)
line2.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
line2.render()
选手的身高分布
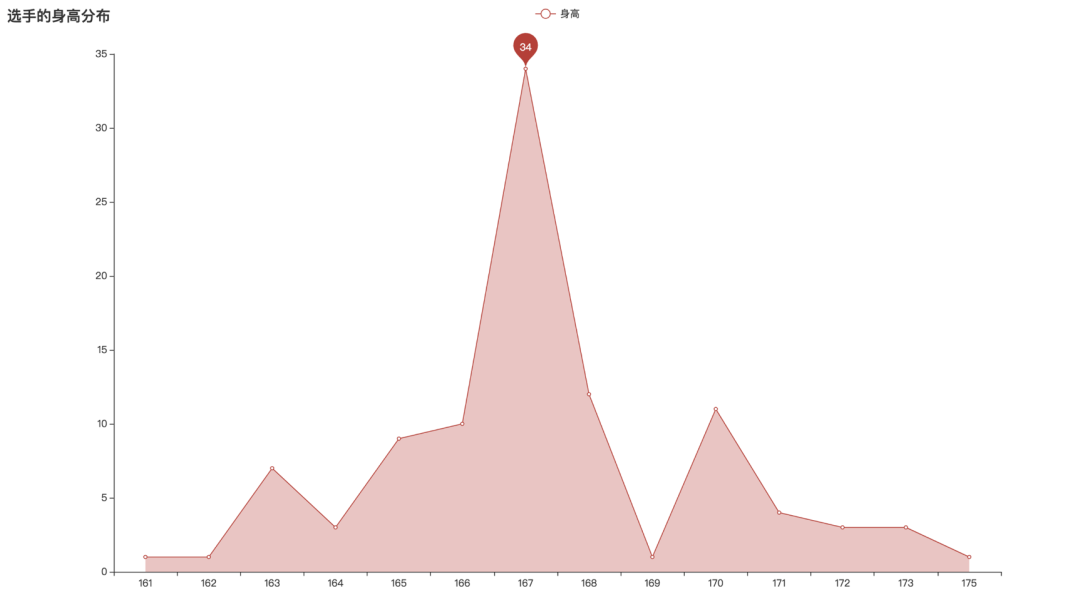
选手籍贯分布

city_num = df.region.value_counts()
# 数据对
data_pair2 = [list(z) for z in zip(city_num.index.tolist(), city_num.values.tolist())]
# 绘制地图
map1 = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))
map1.add('', data_pair2, maptype='china')
map1.set_global_opts(title_opts=opts.TitleOpts(title='选手的籍贯分布'),
visualmap_opts=opts.VisualMapOpts(max_=9))
map1.render()
选手所在经济公司分布
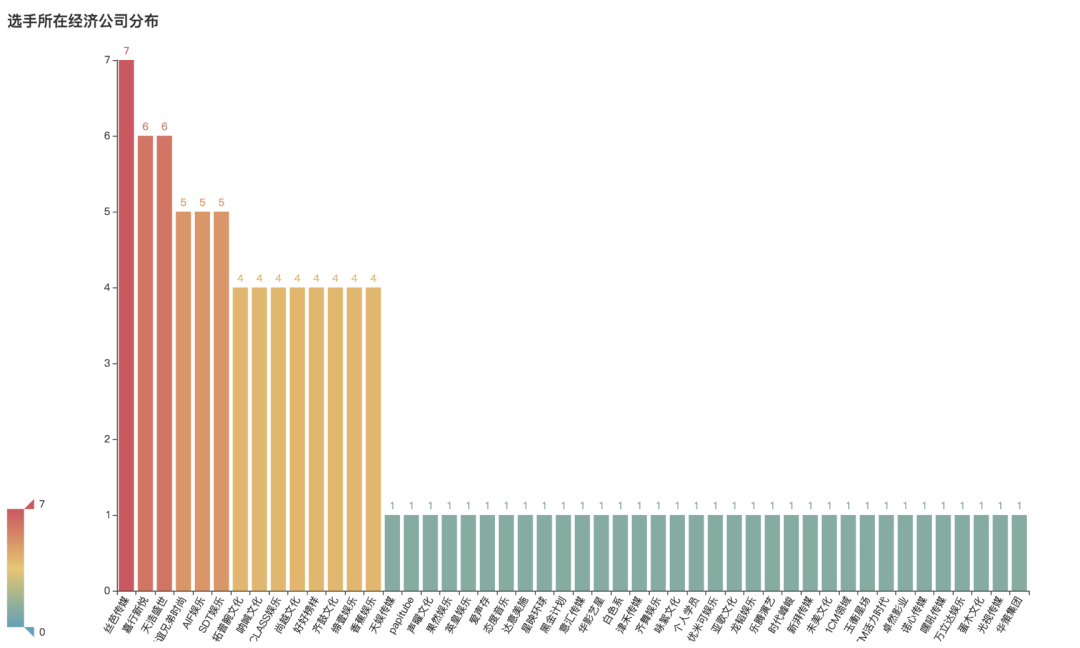
company_num = df.company.value_counts(ascending=False)
# 柱形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(company_num.index.tolist())
bar1.add_yaxis('', company_num.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='选手所在经济公司分布'),
visualmap_opts=opts.VisualMapOpts(max_=7),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate='60')),
)
bar1.render()
选手的颜值分布




推荐阅读

你点的每个“在看”,我都认真当成了AI
你点的每个“在看”,我都认真当成了AI
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 一图全解总体国家安全观 4930389
- 2 福建一地一夜间出现巨幅蜘蛛网 4956611
- 3 河南三蹦子已卖爆20多国 4844476
- 4 带你看春日大地景观 4726407
- 5 女子在海南开沙滩车翻车遇难 4665407
- 6 逃犯伪装寺庙住持潜逃23年 4578144
- 7 长沙迎大暴雨 早八点犹如傍晚 4445611
- 8 男子豪掷70万练功券送女友买房 4394512
- 9 洗牙会让牙齿松动?假的 4240915
- 10 悉尼袭击事件被定性恐怖主义 4138449