不开玩笑,Hadoop集群容量还可以这样扩展
说起Hadoop
它的大名在IT圈已是

让用户可以在不了解
分布式底层细节的情况下
开发分布式程序
同时还能充分利用集群的威力
进行高速运算和存储
就好比蚂蚁赛大象

但另一方面
越来越多客户
不断缩短Hadoop节点的购买周期
原因就是存储空间不足!
而如果按容量需求购买大量服务器
则会有大量计算资源被浪费

因此,面对突如其来的海量数据,我们是沿用原有的横向扩展node方式还是纵向扩展存储呢?如果采用存储纵向扩展方式,那该如何连接?用什么存储?是否会带来管理复杂度?是否会影响性能?架构如何搭建?
Hadoop分布式架构+存储
不是开玩笑!
听到Hadoop分布式架构+存储这一概念,相信会有很多人质疑这种架构,也会有人认为小编不懂Hadoop,没有互联网基因。哈哈,不管了,提起Hadoop横向扩展的全分布式架构,几乎90%以上的用户应该都是横向对等的扩展node(即服务器),很少有人会在Hadoop架构下联想存储的使用方法。
其实小编最初也是一样的想法,Hadoop用什么存储?用什么存储看起来都不完美,原谅我对机房的布局有强迫症,不喜欢那种不对称的布局。但随着Hadoop客户的不断壮大,他们面临的现实需求却在不断地敲打着我。

虽然很多客户对Hadoop架构下使用存储抱有抵触的思想,但也有不少客户在尝试,逐步认识到Hadoop架构下使用一些特定存储并没有破坏Hadoop的全分布式结构,也没有改变Hadoop对磁盘的管理。只是我们在不断横向扩展节点的同时,适时的也可以关注一下存储磁盘的纵向扩展。

Hadoop的出现,也让软件定义存储的使用达到了一个前所未有的高度,在一些互联网类的企业里,少则十几个节点,多则几千个节点的Hadoop集群拔地而起,应用场景越来越丰富,数据量也带来了几何倍数的增长。

从开头的话题我们知道,面对海量数据,如果继续沿用横向扩展node方式扩展,必然会造成浪费,因此本文就来分享一些客户在Hadoop环境下使用JBOD存储,从而减低整体成本的使用方法。
JBOD(Justa bunch of disk)俗称硬盘扩展柜。也就是说,这套存储并没有控制器单元,也没有配置CPU/内存等部件,也没有对磁盘的RAID管理,它非常简单,也非常经典。正因为JBOD本身不配置任何逻辑管理,将全部磁盘管理都交由Hadoop,所以JBOD能和Hadoop完美融合。
下面,我们就来介绍JBOD是如何让Hadoop集群变得更经济、更环保。

一波三折的扩展磁盘方式
首先,Hadoop中除了应用的组件之外,主要有两种node是我们经常关注的,一个是Master node,一个是Data node,如下图所示,客户的Master node继续沿用R640/R630的1U服务器节点,Data node沿用戴尔易安信R740/R730服务器。通过Edge node与Client端(Hadoop Component Client)进行通讯。
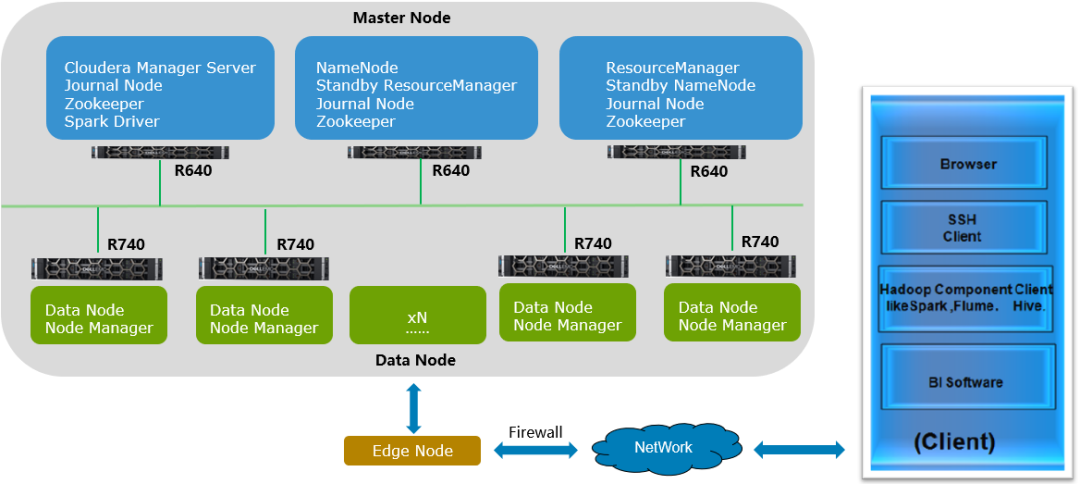
随着业务不断的发展,Hadoop集群也需要不断的扩展,此时细心的客户运维人员发现,最近几次的节点扩展都是因为磁盘容量不够造成的,其实节点内的CPU/内存占用率并不高。所以能否有一种只扩展磁盘的简单方式呢?
▐ 开始总会走一些弯路。我们推荐了带有控制器的智能存储设备,想用智能存储的功能替代Hadoop的管理,结果使用效果不好。
Hadoop想全控磁盘,而智能存储对磁盘又有自己的理解,所以造成两种结果,要么是将一部分业务分拆出来,单独用存储提供数据服务;要么是将智能存储放在Hadoop架构使用,很多高级功能又不能发挥作用。
▐ 于是我们换第二种方案,用低端的带有控制器的存储设备,通过FC/iSCSI方式将磁盘映射给Data node使用。
结果在测试过程中,发现条带化后的磁盘,在Hadoop架构下,反而降低了性能,同时HDFS(Hadoop的文件系统)所提供的节点间数据复制技术已满足数据备份需求,无需使用RAID的冗余机制。因此这种方案也被否定。
这样看来,只有最简单的JBOD可以再次尝试一下,这是一个不带任何逻辑管理的磁盘组,他没有带控制器存储的RAID条带技术。尽管RAID条带化技术(RAID 0)被广泛用户提升性能,但是其速度仍然比用在HDFS里的JBOD配置慢。
JBOD在所有磁盘之间循环调度HDFS块。RAID 0的读写操作受限于磁盘阵列中最慢盘片的速度,而JBOD的磁盘操作均独立,因而平均读写速度高于最慢盘片的读写速度。需要强调的是,各个磁盘的性能在实际使用中总存在相当大的差异,即使对于相同型号的磁盘。在一个测试(Gridmix)中,JBOD比RAID 0 快10%;在另一测试(HDFS写吞吐量)中,JBOD比RAID 0 快30%。

好了,既然JBOD本身性能不差,那么接口会不会慢呢?
接口当然是4通道的12Gb SAS,转换一下单位,每个接口可以达到6GB/s左右的速率,要知道每一块7200转的机械磁盘实际读写速率基本上在100MB/s左右。而一个84盘位的JBOD可以提供6个12Gb SAS接口,理论上可以同时连接6个Data node进行数据访问,并发带宽理论上可以达到36GB/s的接口速率。(实际不可能用到这么大带宽,毕竟后端的磁盘数量是有限的,所以瓶颈不在接口)。
性能看来不是问题,那么Data node上要做什么改变呢?
是否需要很复杂的驱动程序?是否会影响Data node上的组件运行?答案其实很简单,只需要在Data node上安装最常用的12Gb SAS卡即可,Linux操作系统下,其驱动也是极其轻量的安装程序,并不会对上层的组件有任何影响。
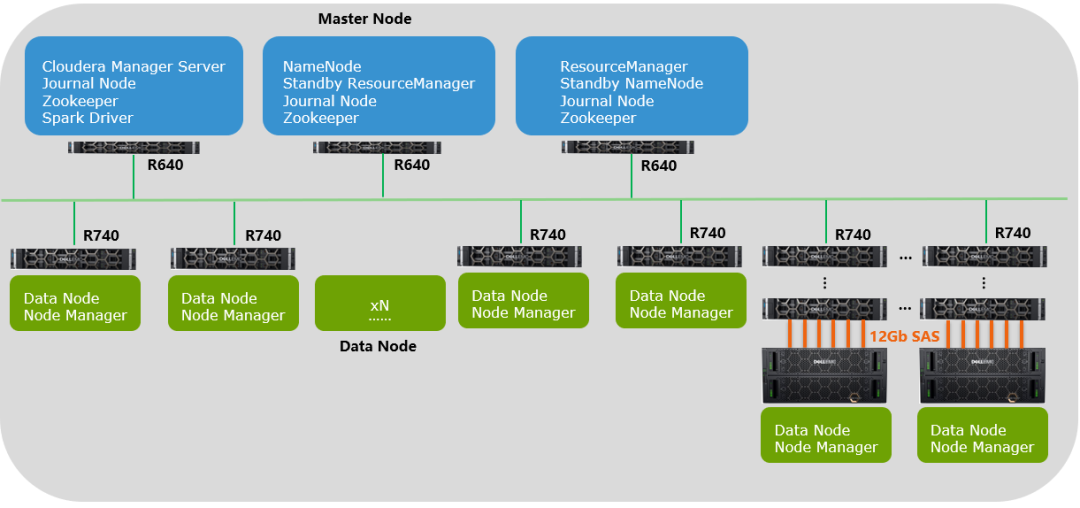
于是,就有了上图。在一个10PB+的Hadoop集群中,已然发现了JBOD的身影,通过JBOD的引入,极大降低了Data node的扩展,从而让机柜空间降低了65%,功耗降低了37%,总体成本降低了35%!对客户来说,这可都是真金白银的成本节省啊。

最后,来介绍一下戴尔易安信的JBOD家族吧
目前,戴尔易安信PowerVault存储系列有MD1400、MD1420和ME484三款JBOD扩展机柜选项,可与第13代和第14代PowerEdge服务器配合使用,借助丰富的盘柜选项、硬盘类型和操作系统选项帮助用户实现轻松扩展,并以灵活的设计方案满足用户的特定需求。同时节省在空间、电力和冷却方面的支出。
扩展Hadoop集群容量,这里还有经济又实用的方式!

动手指“盘”它
进入戴尔易安信解决方案中心

点击“阅读原文”
了解更多数字化转型解决方案
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 企业网D1net
企业网D1net
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 跟着总书记写好中国绿色新答卷 4919631
- 2 反对调休的声音,不能装作听不到 4904859
- 3 华为Pura70系列约一分钟售罄 4838311
- 4 “美丽经济”助推乡村蝶变 4723709
- 5 老人在成都居家4个月燃气费1.5万 4630742
- 6 中国2月减持美债227亿美元 4564256
- 7 华为Pura 70系列开售 4467587
- 8 1岁半男童独自过马路遭校车碾压身亡 4338907
- 9 楼房倒塌人像饺子往下掉?假的 4203872
- 10 中国在纽约接收美国返还38件文物 4161633