Python, C++和Java代码互翻,Facebook开发首个自监督神经编译器


译者 | 刘畅
出品 | AI科技大本营(ID:rgznai100)
将早期的编程语言(例如COBOL)的代码库迁移到现在的编程语言(例如Java或C++)是一项艰巨的任务,它需要源语言和目标语言方面的专业知识。COBOL如今仍在全球大型的系统中广泛使用,因此公司,政府和其他组织通常必须选择是手动翻译其代码库还是尽力维护使用这个可追溯到1950年代的程序代码。
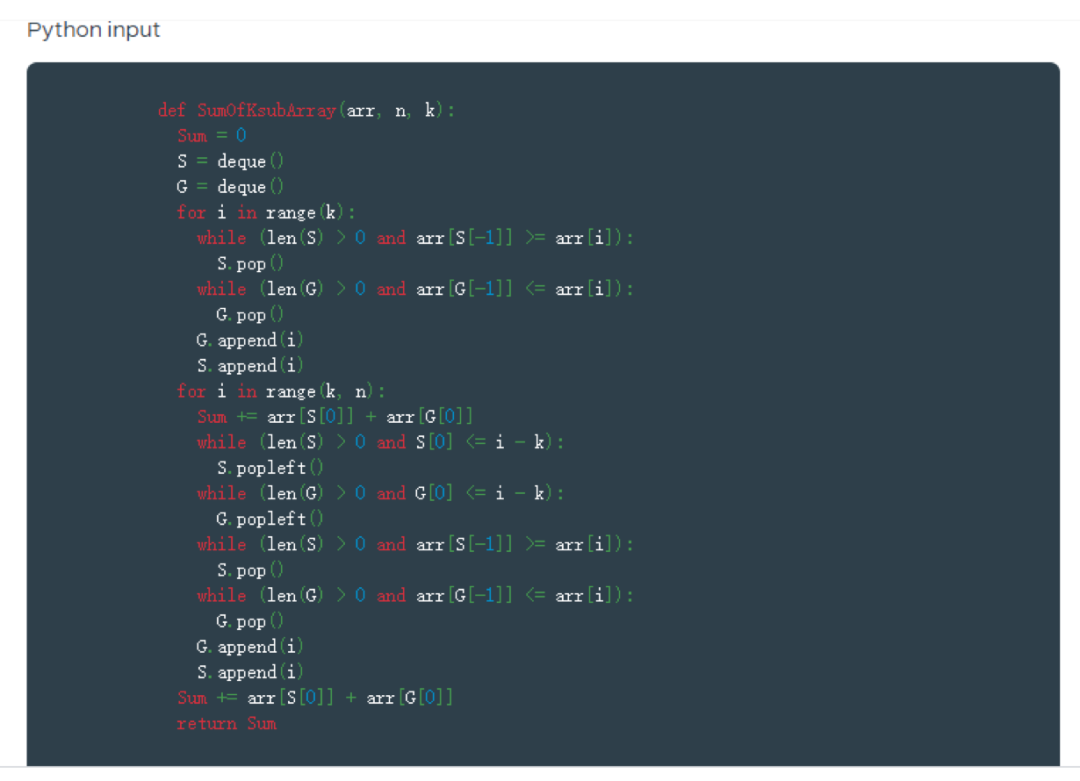
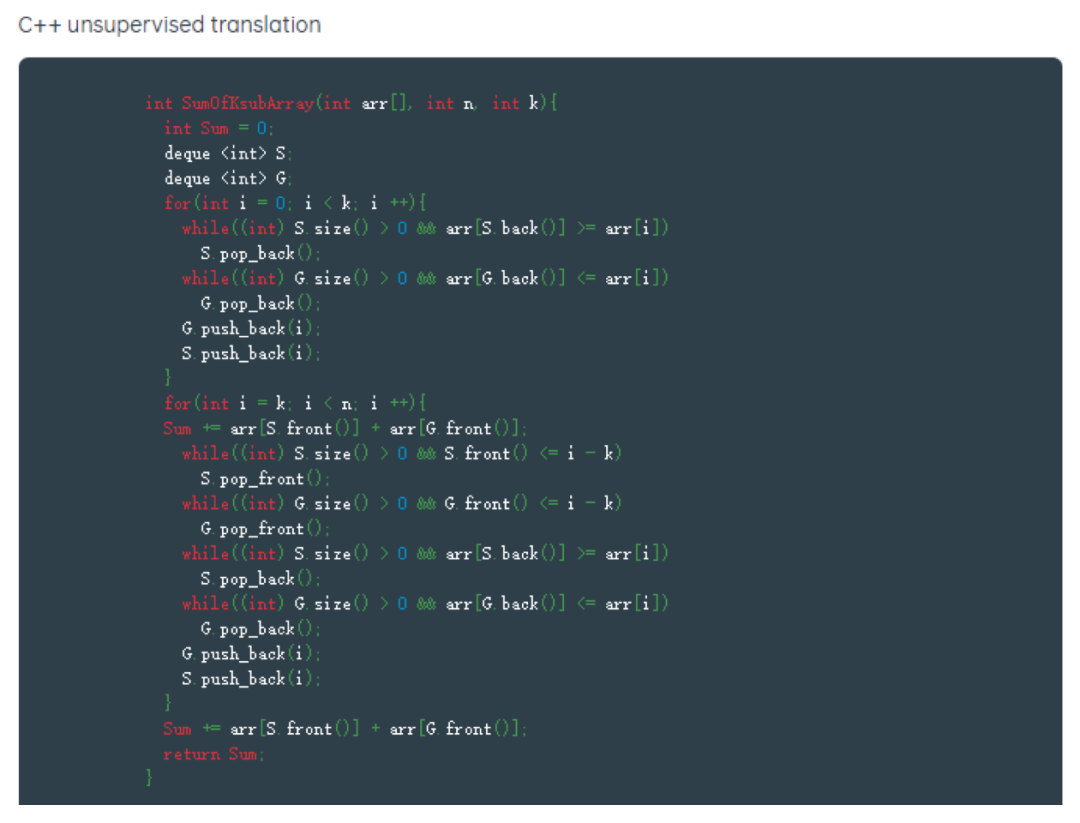
FaceBook公司开发了一个工具TransCoder,这是一个完全自我监督的神经编译器系统,它可以使代码迁移变得更加轻松和高效。本文的方法是第一个能够将代码从一种编程语言转换为另一种编程语言而无需并行数据进行训练的AI系统。本文已经证明TransCoder可以成功地在C++,Java和Python 3之间进行翻译功能。
TransCoder的性能优于开源的代码和基于商业规则的翻译程序。在本文的评估中,该模型正确地将90%以上的Java函数转换为C++,将74.8%的C++函数转换为Java,并将68.7%的函数从Java转换为Python。相比之下,市售工具只能正确地将61.0%的功能从C++转换为Java,而开源的翻译器仅能准确地将38.3%的Java函数转换为C++。
自我监督训练对于在编程语言之间进行翻译特别重要。传统的有监督学习方法依赖于大规模的并行数据集进行训练,但是对于COBOL到C++或C++到Python来说,这些数据根本不存在。TransCoder只依赖于仅用一种编程语言编写的源代码,而不需要源代码和目标语言中的相同代码示例。它不需要编程语言方面的专业知识,并且可以很容易地将TransCoder的方法推广到其他编程语言中。本文还创建了专门为此领域设计的新的评估指标。
TransCoder对于将遗留代码库更新为现代编程语言可能很有用,现代编程语言通常更高效且易于维护。它还展示了一个神经机器翻译技术应用的新领域。与Facebook AI以前使用神经网络解决高级数学方程式的工作一样,本文认为NMT可以帮助完成通常与翻译或模式识别任务无关的其他任务。





推荐阅读
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 奋力谱写西部大开发新篇章 4953090
- 2 贪官靳东受贿100万现金藏床底 4961099
- 3 女子体验荷兰200元一晚的民宿 4809852
- 4 星火成炬|宇宙级别的浪漫 4706827
- 5 国企干部沉迷当“榜一大哥” 4697923
- 6 唐家三少宣布停更 4530139
- 7 金价下跌影响黄金回收市场 4413829
- 8 上海独居老人沉迷拾荒 废品只囤不卖 4378037
- 9 学生跳楼并给教师留信?谣言 4261280
- 10 点读机女孩高君雨全网被禁 4159089