在最新的 MLPerf 基准测试结果中,英伟达新出的 A100 GPU 打破了八项 AI 性能纪录,谷歌的 4096 块 TPU V3 将 VERT 的训练时间缩短到了 23 秒。华为昇腾 910 这次也跑了个分。

在距离推出不到一个月的时间里,内置超过 2000 块英伟达 A100 GPU 的全新 DGX SuperPOD 服务器就在各项针对大规模计算性能的 MLPerf 基准测试中取得了优异成绩。在今天官方发布的 MLPerf 第三批 AI 训练芯片测试结果中,英伟达 A100 Tensor Core GPU 在全部八项基准测试中展现了最快性能。在实现总体最快的大规模解决方案方面,利用 HDR InfiniBand 实现多个 DGX A100 系统互联的服务器集群 DGX SuperPOD 系统也同样创造了业内最优性能。行业基准测试组织 MLPerf 于 2018 年 5 月由谷歌、百度、英特尔、AMD、哈佛和斯坦福大学共同发起,目前已成为机器学习领域芯片性能的重要参考标准。此次结果已是英伟达在 MLPerf 训练测试中连续第三次展现了最强性能。早在 2018 年 12 月,英伟达就曾在 MLPerf 训练基准测试中创下了六项纪录,次年 7 月英伟达再次创下八项纪录。最新版的 MLPerf 基准测试包含 8 个领域的 8 项测试,分别为目标检测(light-weight、heavy-weight)、翻译(recurrent、non-recurrent)、NLP、推荐系统、强化学习,参与测试的模型包括 SSD、Mask R-CNN、NMT、BERT 等。MLPerf 在强化学习测试中使用了 Mini-go 和全尺寸 19×19 围棋棋盘。该测试是本轮最复杂的测试,内容涵盖从游戏到训练的多项操作。
在最新的测试中,英伟达送交的服务器配置和测试结果使用了最新一代的安培(Ampere)架构,以及目前较为流行的 Volta 架构 V100 芯片。
英伟达表示,在评测结果中,自己是唯一一家在所有测试中均采用市售商用产品的公司。其他厂家大多数提交使用的要么是预览类别(Preview,其所用产品预计几个月后才会面市),要么使用的是仍在研究中的产品。今年 5 月在 GTC 大会上正式发布的 A100 是首款基于安培架构的处理器,它不仅打破了 GPU 性能纪录,其进入市场的速度也比以往任何英伟达 GPU 更快。A100 在发布之初用于 NVIDIA 的第三代 DGX 系统,正式发布仅六周后就正式登陆谷歌云服务系统。目前,AWS、百度云、微软 Azure 和腾讯云等全球云提供商,以及戴尔、惠普、浪潮和超微等数十家主要服务器制造商,均已推出基于 A100 的云服务或服务器产品。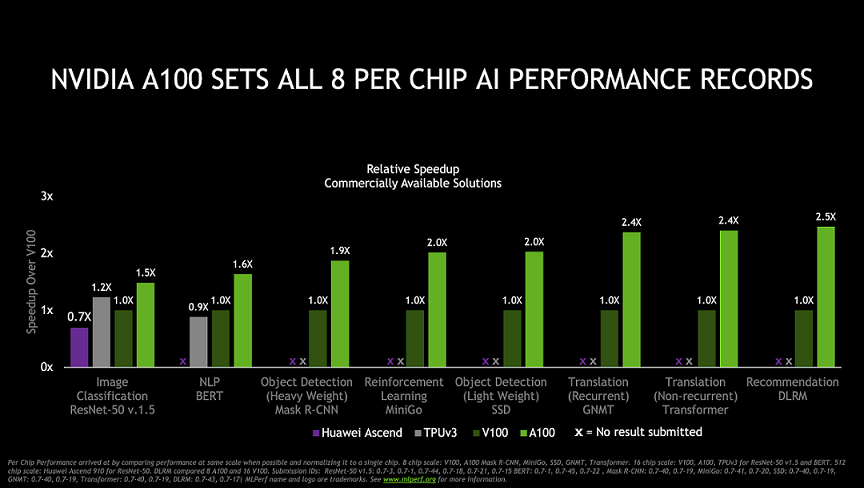
英伟达 A100 在 MLPerf 单卡性能名列前茅的全部八项测试,最新的 MLPerf 榜单中还有华为昇腾 910 的成绩。
英伟达 GPU 性能的提升不仅来自硬件。测试结果显示,相较于首轮 MLPerf 训练测试中使用的基于 V100 GPU 的系统,如今的 DGX A100 系统能够以相同的吞吐率,实现高达 4 倍的性能提升。同时,得益于最新的软件优化,基于 NVIDIA V100 的 DGX-1 系统亦可实现高达 2 倍的性能提升。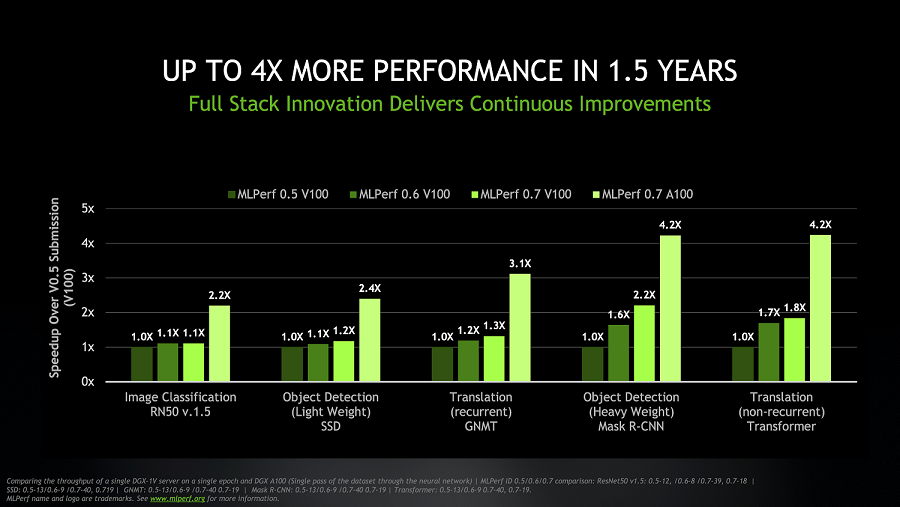
在最新的 MLPerf 测试结果中,谷歌的 TPU 加速器也获得了很好的成绩:在预览和测试组别中,TPU 集群打破了 8 项测试纪录中的 6 项,4096 块并联的 TPU v3 可以实现高达 430 PFLOPs 的峰值算力,训练 ResNet-50、BERT、Transformer、SSD 等模型都可以在 33 秒内完成。
程序员大神,谷歌 AI 负责人 Jeff Dean 说道:「我们需要更大的基准测试,因为现在训练 ResNet-50、BERT、Transformer、SSD 这种模型只需要不到 30 秒了。」

谷歌在本次 MLPerf 训练中使用的超级计算机比在之前比赛中创下三项记录的 Cloud TPU v3 Pod 大三倍。该系统包括 4096 个 TPU v3 芯片和数百台 CPU 主机,峰值性能超过 430 PFLOPs。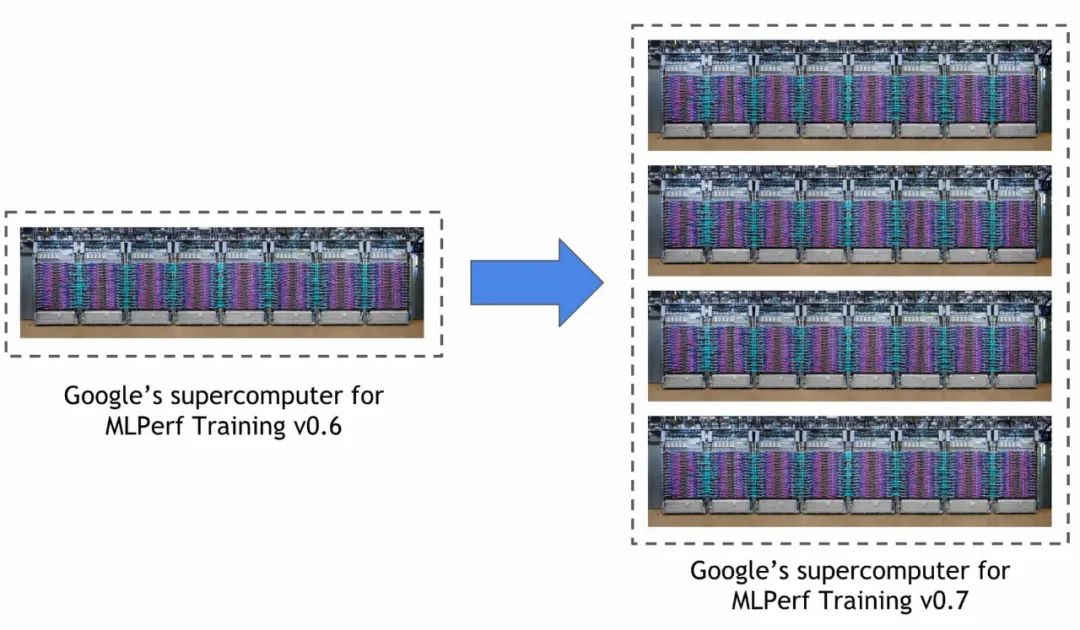
在 4096 块 TPU 的加持下,谷歌的超级计算机可以在 33 秒内训练 ResNet-50、BERT、Transformer、SSD 等模型。在使用 TensorFlow 框架时,该计算机甚至可以将 BERT 的训练时间缩短到 23 秒。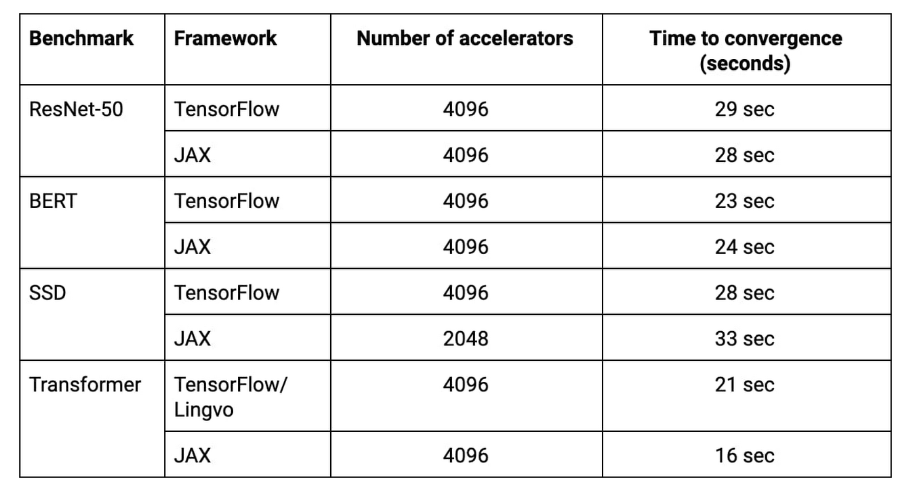
在谷歌最新的 ML 超级计算机上,上述所有模型的训练都可以在 33 秒内完成。
谷歌还在最新的博客中透露了一些关于第四代 TPU 的信息。新一代 TPU 的矩阵乘法 TFLOPs 是上一代的两倍还多,内存带宽显著提高,还采用了新的互连技术。与 TPU v3 相比,TPU V4 在芯片数量类似情况下的表现平均提高了 1.7 倍。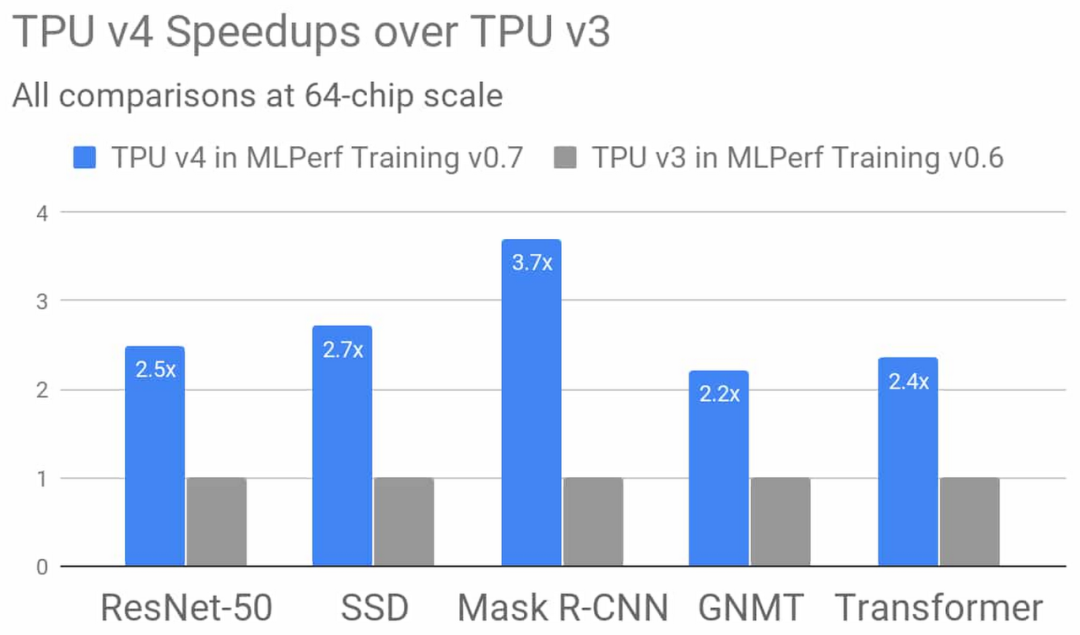
最后,一些从业者也对深度学习框架在模型训练速度上的贡献表示感叹。
看起来,TensorFlow 2.0 的速度比 PyTorch 要快,谷歌最近开源的 TensorFlow 简化库 JAX 则效率更高。在工业应用上,我们对于框架的选择看来也要出现变化?
https://cloud.google.com/blog/products/ai-machine-learning/google-breaks-ai-performance-records-in-mlperf-with-worlds-fastest-training-supercomputerhttps://blogs.nvidia.com/blog/2020/07/29/mlperf-training-benchmark-records/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+nvidiablog+%28The+NVIDIA+Blog%29https://mlperf.org/training-results-0-7Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





