无监督学习?Yann LeCun说:或许应该叫它预测性学习

新智元报道
新智元报道
来源:danrose
编辑:白峰
【新智元导读】随着机器学习的不断发展,无监督学习在近年来备受关注。Yann LeCun提出赋予无监督学习新的名字——预测性学习。

监督学习、无监督学习和强化学习:机器学习的三驾马车
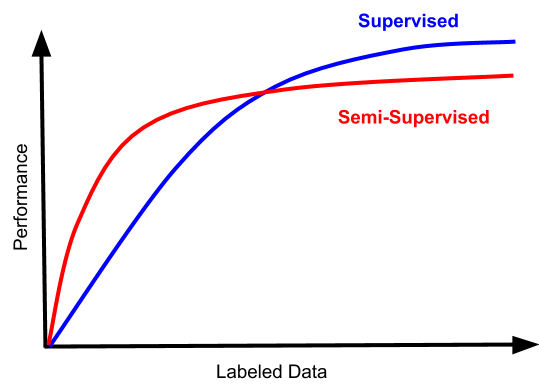
昂贵且复杂的数据标记让监督学习变得困难

无监督学习(预测性学习)正在登上历史舞台
正如Yann LeCun所说,无监督学习是「填补空白」。填补空白不仅仅是将相似的事物归类,填补空白就像是想象。 在训练预测学习模型时,目的是了解当前的世界。

「预测性学习」可能会改变我们的未来


关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/



![swaggaws_猜猜我最喜欢哪一张[哈欠]](https://imgs.knowsafe.com:8087/img/aideep/2021/9/4/edaa29ff291d4270c558f95e48b94f5e.jpg?w=250)

![唐曼真的热到想去广州避暑[泪][泪][泪] 2杭州 ](https://imgs.knowsafe.com:8087/img/aideep/2022/7/25/dc319a6bf831ed5ec48365bc68931e36.jpg?w=250)
 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 跟着总书记写好中国绿色新答卷 4940006
- 2 张核子首度回应张珊珊身份 4936647
- 3 除了调休 我们的假期还能怎么休 4846796
- 4 “美丽经济”助推乡村蝶变 4770766
- 5 35人花600多万全款买商铺烂尾7年 4652487
- 6 小店销售假舒肤佳被诉 法院:不用赔 4514346
- 7 婴儿独自爬出客厅猫咪警觉守护 4432043
- 8 男子打死火烈鸟获刑五年 4330396
- 9 楼房倒塌人像饺子往下掉?假的 4211297
- 10 美对华发起301调查 商务部回应 4106796