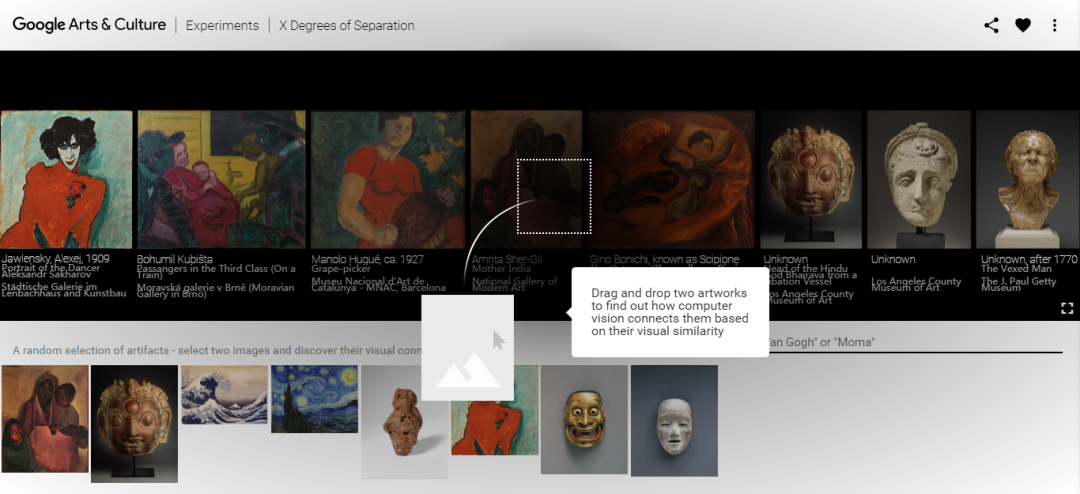
艺术,作为时间与空间的沉淀,经常被视为一场带领现代人类回到过去一窥究竟的旅行,也是允许人们暂时逃避当下的载具。绘画宝库无穷无尽,因此来自不同时间或空间的艺术品之间的联系常常会被忽略。即使是最有知识的艺术评论家,也无法阅览跨越数千年时间的数百万幅画作,并在主题、基调和视觉风格上找到意想不到的相似之处。为了简化此过程,麻省理工学院计算机科学与人工智能实验室(CSAIL)和微软的一组研究人员创建了一种算法,以发现大都会艺术博物馆(the Met)与阿姆斯特丹国立博物馆馆藏绘画之间的隐藏联系。受阿姆斯特丹国立博物馆特别展览“伦勃朗和贝拉克斯兹”的启发,新的“MosAIc”系统通过使用深层网络了解两个图像的近似程度,发现了来自不同文化、艺术家和媒介的成对(也即“类似”的)作品。在那次展览中,研究人员受到了一种看似并不可能但却确实相似的匹配作品的启发:弗朗西斯科·德·祖巴兰(Francisco deZurbarán)的《圣塞拉皮翁难》和扬·阿瑟林(Jan Asselijn)的《受威胁的天鹅》,这两幅作品都描绘了深刻的利他主义场面,并拥有非常令人惊讶的视觉相似性。一位来自CSAIL的博士生马克·汉密尔顿(Mark Hamilton)说:“这两位艺术家一生中没有通信或彼此见面,但他们二者的画作都拥有着丰富而相似的潜层结构” 。汉密尔顿是有关“MosAIc”的论文的主要作者。为了找到两幅相似的画作,该团队使用了一种新的图像搜索算法来发现特定艺术家或文化的最接近匹配。例如,对于一项“哪种乐器最接近于此蓝白色连衣裙绘画”查询,该算法检索了蓝白色瓷小提琴的图像。这些作品不仅在样式和形式上相似,而且源于荷兰人和中国人之间更广泛的瓷器文化交流。汉密尔顿说:“图像检索系统使用户能够找到语义上与查询图像相似的图像,充当反向图像搜索引擎和许多产品推荐引擎的基础。”“将图像检索系统限制为特定的图像子集可以帮助对视觉世界中的关系产生新的见解。我们的目标是鼓励更高层次的与创造性艺术品的互动。”对于许多人来说,艺术与科学水火不容:科学基于逻辑、推理和经证实的真理,而艺术则基于情感、美学和美感。但是最近,人工智能和艺术出现了新的变化,在过去的十年中,这种变化变得越来越大。比如说,从前,绝大多数的新研究集中于使用AI生成新艺术。有一个由麻省理工学院、NVIDIA和加州大学伯克利分校的研究人员开发的GauGAN项目就是一个例子。还有汉密尔顿曾经参与过的GenStudio项目;甚至还有过一件AI生成的艺术品,被在苏富比以51,000美元的价格售出。但是,MosAIc的目的不是创造新艺术,而是帮助探索现有艺术。谷歌的“X分离度”是一种类似的工具,可以找到将两件艺术品联系起来的艺术品路径,但是MosAIc的不同之处在于,它仅需要一张图片即可。它没有找到路径,而是发现用户感兴趣的任何文化或媒体中的联系。汉密尔顿(Hamilton)指出,建立他们的算法是一项艰巨的尝试,因为他们希望找到不仅颜色或样式相似,而且含义和主题相似的图像。换句话说,他们希望狗与其他狗靠近,人们与其他人靠近,等等。为了实现这一目标,他们在大都会博物馆和国家博物馆的开放访问集合中,针对每个图像探究了深层网络的内部“激活”。他们如何判断图像相似性,就是通常称为“功能”的这种深层网络“激活”之间的距离。为了找到不同文化之间的相似图像,该团队使用了一种新的图像搜索数据结构,称为“条件KNN树”,该结构将相似图像组合成树状结构。为了找到匹配的对象,他们从树的“树干”开始,然后跟随最有希望的“分支”,直到他们确定找到最接近的图像为止。通过允许树快速将其自身“修剪”到特定的文化,艺术家或馆藏,从而快速产生对新型查询的答案,数据结构对其前身进行了改进。汉密尔顿和他的同事感到惊讶的是,这种方法也可以用于帮助发现现有的深层网络的问题,这些问题与最近涌现的deepfake有关。他们应用此数据结构来查找概率模型(例如经常用于创建深造品的生成对抗网络)崩溃的区域。他们将这些有问题的区域称为“盲点”,并指出它们使我们能够洞悉GAN的偏见。这种盲点进一步表明,即使大多数伪造品可以欺骗人类,GAN仍难以代表数据集的特定区域。该团队评估了MosAIc的速度,以及它与人类对视觉类比的直觉之间的接近程度。对于速度测试,他们希望确保其数据结构在通过快速,强力搜索简单地搜索整个集合中提供价值。为了了解系统与人类直觉的协调程度,他们制作并发布了两个新的数据集,用于评估条件图像检索系统。一个数据集对算法提出了挑战,即使使用神经样式转移方法对其进行“样式化”后,也要查找具有相同内容的图像。第二个数据集挑战了算法以恢复不同字体的英文字母。不到三分之二的时间,MosAIc能够一次从5,000张图像中猜测出正确的图像。汉密尔顿说:“展望未来,我们希望这项工作能激励其他人思考信息检索工具如何帮助其他领域,例如艺术,人文科学,社会科学和医学。”“这些领域充满了从未被这些技术处理过的信息,可以为计算机科学家和领域专家带来巨大的灵感。这项工作可以在新的数据集,新的查询类型和新方式方面得到扩展了解作品之间的联系。”https://techxplore.com/news/2020-07-algorithm-hidden-met.html实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/




![允洛:气鼓鼓 [哼] ](https://imgs.knowsafe.com:8087/img/aideep/2021/8/12/7228f3c70a5cdf799ec21e728ac36f39.jpg?w=250)




 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





