

作者 | 阿里文娱算法专家 梵生
责编 | 李雪敬
头图 | CSDN下载自视觉中国

视听盛会,剧集、综艺、短视频等都是娱乐行业的主流载体,而高品质的长视频(剧集、综艺)是内容行业提升用户粘性的关键,也是娱乐行业的必争之地。但是,剧集、综艺等长视频面临严峻的问题:剧综的拍摄、剪辑投入巨大,制作周期长,但目前行业很难在播前甚至制作早期进行质量评价或品控。高投入和高不确定性的质量评估体系形成了主要矛盾。 大数据与人工智能已经在各个行业大展身手,而海量的视频数据、用户观看数据,已经为人工智能算法提供了肥沃的土壤;视频、音频、文本等非结构化数据,天然符合人工智能(深度学习)算法擅长的领域。因此,使用AI技术来对视听介质进行全方位解构,并利用海量数据、发掘内容创作规律,辅助内容质量评判是AI技术落地的一大领域,也是一片AI应用的蓝海。
成片体检是我们使用AI算法对内容创作质量进行量化的尝试。类比人的体检,成片体检主要指利用视听AI技术,计算出能够反映内容创作质量的各个维度指标,并根据不同类型的内容,分别计算出优质内容在各个维度指标上的最佳取值或区间,形成内容的健康标准。我们通过AI算法,对待检测内容在各个维度上与健康内容进行比对,给出相应维度的预警、实现成片质量的体检报告辅助剪辑优化。我们期望做到的就是类比医学中的高精密仪器,全方位、准确地数字化扫描整个内容,进而赋能整个内容行业。成片体检的整体框架如图 1所示。整个框架可以分为指标层、指标提取算法、融合层、基础模型层。1)指标层是依赖于内容创作体系所总结归纳出来的,可用以量化内容创作的计算指标。为了从原始视频媒介得到这些指标,我们需要自下而上分别建立基础算法层,算法融合层和指标提取层;2)基础算法层指对原始视频介质的解析,学术上属于典型的视频理解与视频解构。基础算法包括典型人物检测、人物识别、人物重拾、场景识别、动作行为识别,也包括镜头切分识别、表情识别、情绪识别、景别识别、背景音乐情绪识别等内容行业特别关注的基础模型。基础模型往往得到一些视频基础元素级别的结果,需要经过模型融合层的相关模型,才能形成具有内容意义的中间结果;3)模型融合层包括角色轨迹识别、故事场景切换,角色情绪发展模型等。指标提取层则直接根据融合层结果或者基础模型结果,结合用户播放、评论数据筛选出的优质内容,计算出内容的健康标准。比如,一部正常的电视剧,不同番位的出镜占比、故事线的占比是怎样的,一般用怎样的镜头时长,怎样的景别占比;角色交互的复杂度指标如何等等。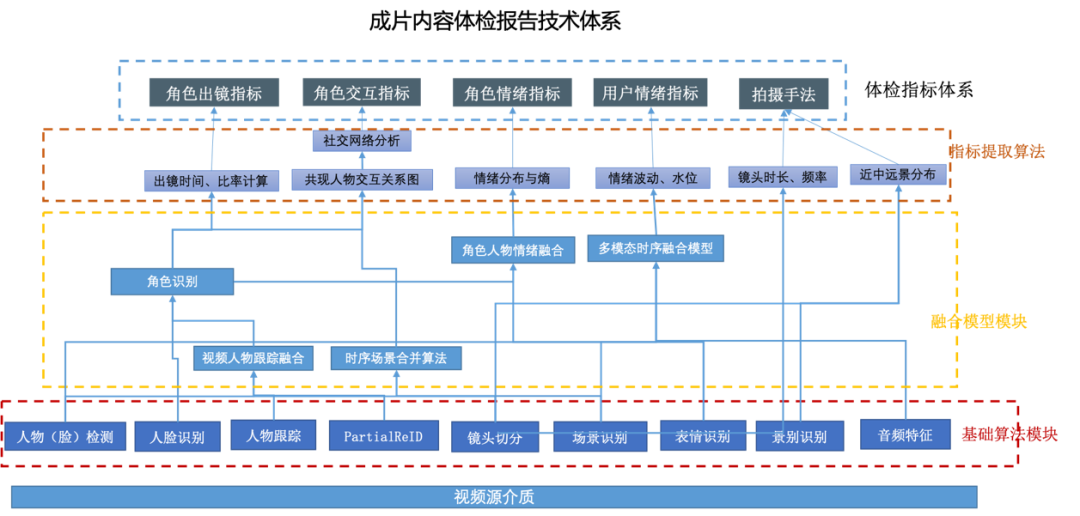 图1 成片内容体检报告技术体系
图1 成片内容体检报告技术体系
为了支撑成片体检体系搭建,我们在音视频基础模型上进行了一些探索。整个体检指标体系所需要的基础模型涉及几乎视频理解领域所有的问题,包括但不限于人物(人脸)检测、识别、跟踪,人物重拾,人物动作识别,人物表情识别等等。为了充分发挥阿里巴巴整个集团的技术优势,我们在部分模型上选取了集团或其他团队的模型,比如人脸识别、动作识别等等;同时,针对内容行业的视频介质特点,我们团队也自研了针对内容视频的定制优化的人物匹配框架,视频情感计算,剧集场景识别等基础模型,并在各自领域的接近或者超越业内最佳性能。下面着重介绍人物匹配框架与观影情绪模拟这两部分工作。1. 剧综人物匹配框架
成片体检的许多指标需要依赖于准而全的视频人物角色识别。内容行业的视频是多机位、多角度拍摄剪辑而成;同时,根据拍摄需求,人物妆容、衣着都有着较大差异,这就导致了人物识别问题有别于传统的人脸识别或者行人检测。主要体现在:- 多机位的拍摄导致的是非配合式的人脸识别,在侧脸、背面、远景下,人脸识别尚无太好的解决方案;
- 镜头切换与剪辑有别于监控场景,打破了视频内在逻辑,使得检测跟踪的作用有限;
- 根据创作需要,经常交替出现人物的全身、半身画面。上述特点会导致大量侧脸、背面、远景、半身、全身角度下人物的丢失。无法满足我们“准”、“全”的要求。
针对上述问题,我们设计了剧综人物匹配框架。如图2,我们把剧集内的人物“准全”的识别,拆解为镜头内和跨镜头的问题进行分析。在同一镜头内,我们复用成熟的检测与跟踪,那么跨镜头则需要人物重拾。对于长时的多姿态,则需要利用时空、人脸人体、上下文等整体信息进行人物匹配,这就类似于多维信息下人物检索问题。人物重拾的特征作为基础特征层,被多维信息人物检索使用。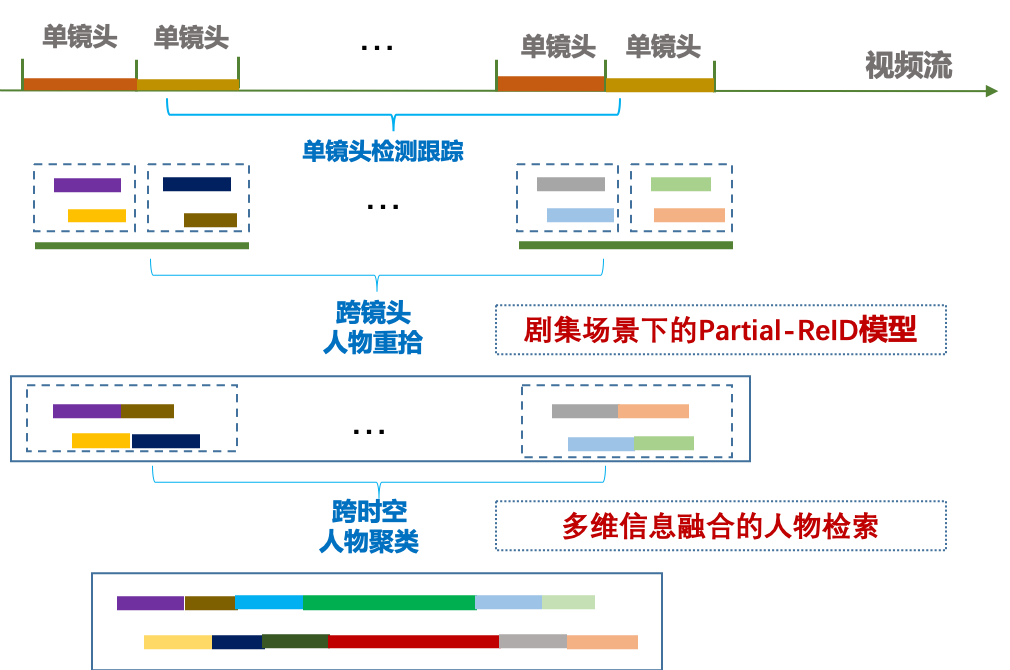
图2 剧集场景下的人物匹配算法框架
在基础人物重拾模型上,我们提出了适用于影视行业的 DramaReID 剧集 ReID 数据集和 ESA-ReID 模型。DramaReID 数据集来自于我们海量的剧综视频数据,覆盖了上万个人物的全身、半身等视角,是目前业内已知的最大的partial reid 数据集。针对刚才提到的人物重拾问题特点,我们提出了 Entropybased Semantic Alignment Re-ID 模型,模型的整体架构如图3所示。类似与传统的 re-ID 模型,我们使用 ResNet50 作为主干特征提取网络,随后,针对全半身比对时需要的语义级别的特征和比对,我们分别引入了语义分割多任务,基于语义分割不确定性的置信度模块和基于置信度的动态比对模块,以解决剧综场景下全半身人物重拾问题,得到的人物形象表征也为后续多维人物检索做准备。
具体地,我们使用成熟的语义分割模型,对待识别的人物进行人体部件语义分割,该分割结果作为监督信号,来训练我们的语义分割支路。语义分割支路得到人体各个部位的分割区域及其概率后,会经过基于熵的不确定性计算模块,来获得人体高确定性和不确定的掩模区域。我们的方法是业内首个利用熵来度量人物重拾任务中的语义分割的不确定的。通过度量不确定性,一方面减弱语义分割的误差对模型性能的影响,另一方面,不确定性高的区域,正好对应了人体缺失或被遮挡的部位,可以用于人物相似度计算。通过基于熵的不确定模块得到确定性和不确定性掩模后,我们可以得到人体各个部件的特征,以及对应的不确定性。在计算待匹配的两个人物的相似度时,就能够通过各个部件一一比对,并用其对应的不确定性来做权重进行计算。一方缺失的部件,其不确定性高,进而权重变低甚至为0,这样相似度就取决于待比较的两个人物共同出现的身体部位的视觉特征。 整体上看,我们的 ESA Re-ID 方法是端到端的模型,在 inference 阶段不依赖任何第三方模型;同时,我们引入的基于熵的度量,极大程度降低了语义分割支路的误差,并在语义部位级别进行了对齐比对。我们的模型在业内公开的数据集,如 Market1501, DukeMTMC 等达到了 SOTA 水平,在 Partial-ReID,PartialILID 等 partial 测试集上,大幅超越了 SOTA。在我们自建的 Drama ReID 数据集上,我们的方法也和业内主流的 SOTA 方法进行了比较,性能上均有巨大提升。具体可见我们后续将要公开的论文。人物重拾的特征目前无法解决剧集中长时场景下,人物变装变形象的问题。该问题可以定义为多维信息的人物检索问题。多维信息包括人脸特征、人体特征、场景特征等等,业内也有学术论文进行了相关的研究工作。目前,我们设计了一种无监督的,基于人脸、人体多维特征长时跨镜头层次聚类的方法。具体图4。整体思路是,我们期望在时域局部使用人物重拾特征进行人物合并,而在全时域使用人物与人脸特征进行合并,这样综合人脸和人体重拾特征的层次聚类,在聚类的纯度、精度都有巨大提升。
图4 人物层次聚类示意图
在使用了上述的人物匹配框架之后,我们的剧综人物的准确率、召回率都有10%以上的提升,不仅为成片体检提供了准确的人物类数据与指标,还为优酷的“只看他“业务提供了算法支撑,提升了人物召回率,降低审核成本。2. 观影情绪模拟
共情是内容拉动观众的核心,预测内容能给观众带来的情感体验是内容体检的另一个重要且直观的指标,能够在内容播放前就预测观众的观看的结果,比如情绪高点、低谷,或者平局的情绪高点的时长占比等,将对视频优化有重要指导意义。直接通过视频内容来预测观众的情感状态是音视频和情感计算交叉领域问题。在情感计算领域,除了使用典型的7类情感之外,学术界会使用 Valence 和 Arousal 二维情绪模型,来细粒度全面描述人的情感状态。Arousal可以理解为是情绪的强度,范围为(-1,1),1表示最强,如激动,-1 表示最弱,比如睡着的状态。Valence表示情绪的正负(-1,1),1表示正向,-1表示负向。那么任何情感状态均可以使用在 Valence 和 Arousal 的坐标系中表示。另一方面,视频表征领域,可以利用视频的场景、人物、行为姿态、背景音乐等多个维度共同表征视频特点。那么上述观影情绪模拟就是建立上述视频表征到情感状态的映射函数。基于学术界的相关研究和已有的开源数据集,我们提出了基于多维视频表征的情绪预测模型,模型的输入是连续的剧综片段,输出预测的用户逐时情绪 Valence 和 Arousal 值。
图5 观影情绪模拟模型结构图
模型的整体结构如图5所示:首先,将整个视频分成连续的固定长度的片段,随后,对每个片段进行基础特征提取。在基础特征上,我们使用了分别提取了场景特征,人物表情特征,人物行为特征和音频特征。具体地、场景特征使用了基于 Places365 数据集 pretrained 的 Vgg6 作为特征提取器,提取每帧的场景表征;人物表情特征则使用了我们自研的人物帧级别表情模型作为特征提取器,逐帧提取该帧图片的人物特征;行为特征使用了 OpenPose 的预训练主干网络,音频特征使用了基于梅尔倒谱和 Vggish 的特征提取器提取音频帧特征。在得到各个模态的逐帧表征后,我们引入了长短时融合机制,以反映情绪随时间具有依赖性的特点,并兼顾长期趋势和短期波动。在短时特征融合上,我们将每帧的各个模态特征,分别送入各自的 LSTM 层,得到各个模态在该视频段落的最终表征。经过 LSTM 之后的多模态特征经过合并后,再次送入第二层 LSTM,该层 LSTM 的输入是相邻视频段的融合后的模态表征,输出的是每个视频段的 Valence 或 Arousal 值。第一层 LSTM 是短时时序融合,第二层 LSTM 则是长时时序融合。考虑到 Valence 和 Arousal 存在一定差异,我们对两者分别进行建模。人的情绪强度往往具有更强的平滑性,而 Valence 则可以随片段快速转变。因此我们对 Arousal 部分进行了滑动平均处理,得到最终的 Arousal 结果。我们的模型在开源的多媒体情感计算数据集上,在 MSE,PCC 等指标均超过了业内的 SOTA 水平。模型具体实现和数据测评见我们公开的论文(https://arxiv.org/abs/1909.01763)。情感模拟反映了用户对内容的真实感受,我们使用模型的结果和真实线上视频的收视数据进行了对比,发现了惊人的一致性。这就充分证明了模型的使用价值。图6是在电影《我不是药神》的 case 和《长安十二时辰》收视曲线和 Arousal 曲线的比对结果。可以看到,在《我不是药神》的 Valence 预测中,我们的情感 Valence 正确的反映了电影前喜后悲的情感趋势。图7是《长安十二时辰》的情绪 Arousal 预测和收视曲线比对,发现情绪高潮点和低点对应了收视高点和低点,这进一步证实了用户情绪模拟的巨大业务价值。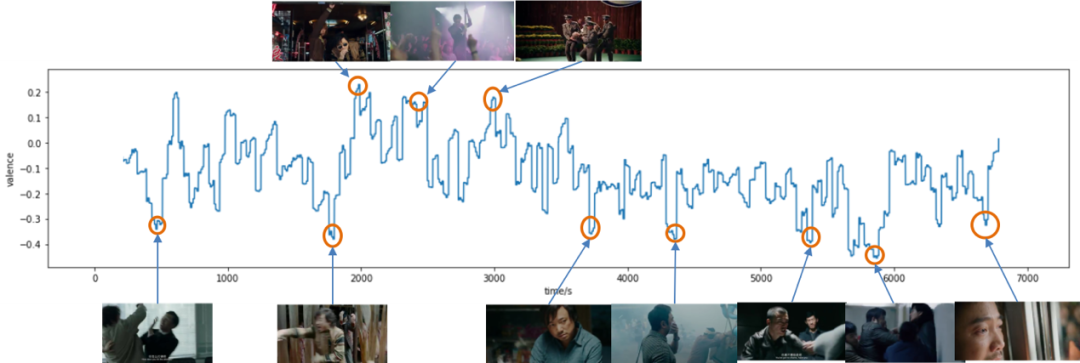
图6《我不是药神》Valence 预测结果示意图
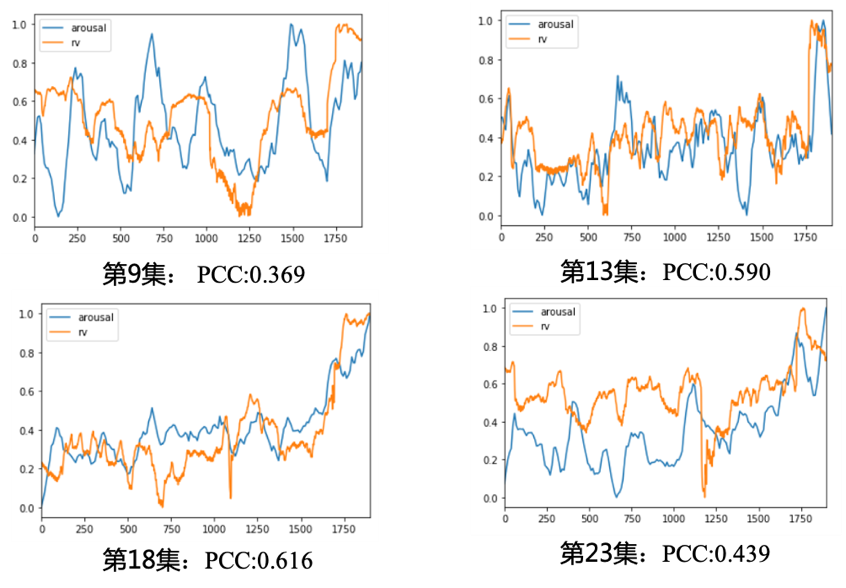
图7 长安十二时辰收视曲线与 Arousal 预测对比

目前,我们已经建立了基本的基于人物和情感的体检体系,并根据全网头部剧集,建立了各个题材相应的“健康标准“。覆盖了主要的剧综播前评估与优化。在人物侧,通过人物识别得到的故事线、人物出镜指标,帮助我们发现了前期热播的剧集在第一集主人公故事线缺失的预警,并得到片方认可和修改。我们的情绪模拟曲线,全面在覆盖优酷的自制综艺、剧集、网大。其中,通过网大开放平台对业内透出的体检能力,能够为网大片方检测成片的高潮低谷,和相对业内优质内容的水位参考,为平台带来了大量的签约与合作,不少内容经过体检和优化后成为了网大爆款,如图8。
图8 开放平台内容辅助优化效果喜报
未来,整个成片体检将会更加深入和精细化。从应用角度看,我们将继续扩展体检维度,同时深入题材特有的细粒度体检指标,形成题材定制化体检能力。在整个视觉AI技术上,围绕成片体检,我们将继续在多模态人物检索,多模态情感计算,人物交互片段检测与关系属性识别等理解视频剧综内容所面临的特有的问题上深入研究,持续向文娱行业输出算法成果与能力。

更多精彩推荐
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/









 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





