从无声视频中生成音乐?这听起来很难。由MIT-IBM 沃森人工智能实验室主任研究员淦创博士领导的研究小组在 ECCV 2020 的一篇论文中,提出了一种名为 “Foley Music” 的模型,仅根据音乐家的身体动作就能自动生成一段极具表现力的音乐。
说起计算机音乐的发展史,还要追溯到 1951 年,英国计算机科学家艾伦 · 图灵是第一位录制计算机生成音乐的人。近年来,深度神经网络的出现促使了利用大规模音乐数据进行训练来生成音乐的相关工作。然而,音乐往往伴随着演奏者与乐器的互动,并通过细微的手势与乐器相互作用以产生独特的音乐。这就会出现一个有趣的问题:给定音乐家演奏乐器的无声视频片段,我们是否可以开发一种模型,能够根据音乐家的身体动作自动生成一段逼真的音乐?这种功能将会为各种应用奠定基础,例如自动为视频添加声音效果,以避免繁琐的人工操作,或在虚拟现实中创造听觉沉浸式体验。但具体来说,如何实现呢?
为了解决这个问题,由MIT-IBM 沃森人工智能实验室主任研究员淦创博士领导的研究小组提出了一种名为 “Foley Music” 的模型,可以从无声视频中生成富有表现力的音乐。该模型将视频作为输入,检测视频中的人体骨架,识别其与乐器之间的交互作用,预测相应的 MIDI 文件。论文已入选计算机视觉顶会 ECCV 2020。
首先,研究者确定了生成音乐的两个关键要素。对于视觉感知,采用身体和手指关键点作为视觉表征,从而可以显式地对身体部位和手部动作进行建模;对于音频表征,研究者提出使用 MIDI,可对每个音符事件的时间和强度信息进行编码,使用标准音频合成器,亦可轻松将 MIDI 转换为逼真的音乐波形。由此将音乐生成问题视为 Motion-MIDI 的转换问题,如图 1 所示。同时研究者还提出了 Graph-Transformer 模块来学习将它们关联起来的映射函数。
为了评估生成音乐的质量,研究者进行了定性研究实验,通过正确性、噪声量、同步性和综合性指标进行衡量。实验结果证明,该方法的性能明显优于其他现有方法。更重要的是,由于 MIDI 是完全可解释和透明的,能够灵活地进行音乐编辑。研究者表示,该工作将为通过人体关键点和 MIDI 来探索视频和音乐之间的联系开辟未来的研究方向。研究者分别选择了人体姿态和 MIDI 作为视觉和音频表征,并提出了一种 Graph-Transformer 模型,根据身体姿态特征预测 MIDI 事件,整体框架如图 2 所示。该模型使用人体姿态特征来捕获身体运动线索。首先,从视频的每帧中检测身体和手指关键点,然后将其 2D 坐标根据时间堆叠为结构化视觉表征。在实际应用中,使用开源 OpenPose 工具箱提取身体关键点的 2D 坐标,并使用预训练手部检测模型和 OpenPose hand API 来预测手指关键点的坐标。总共获得了 25 个身体关键点,以及 21 个手部关键点。选择正确的音频表征对于成功生成富有表现力的音乐非常重要。研究者选择 MIDI 作为音频表征,主要由 note-on 和 note-off 事件组成,每个事件也定义了音高和强度。研究者使用音乐处理软件从视频的音轨中自动检测 MIDI。对于 6 秒钟的视频片段,通常包含大约 500 个 MIDI 事件。这些 MIDI 事件可以很容易地导入到标准合成器中生成音乐波形。
在从视频中提取的 2D 关键点坐标基础上,研究者采用 GCN 对身体和手部不同关键点之间的时空关系进行显式建模。与 ST-GCN 类似,首先,将人体骨架序列表示为无向时空图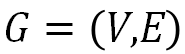 ,其中节点对应于人体关键点,边反映了人体关键点的自然连通性。每个节点的输入是检测到的人体关键点的 2D 坐标。为了对时空信息进行建模,研究者首先采用空间 GCN 对每帧上的姿态特征进行独立编码,然后对得到的张量采用时间卷积来聚合时间信息。编码后的姿态特征 P 定义为:
,其中节点对应于人体关键点,边反映了人体关键点的自然连通性。每个节点的输入是检测到的人体关键点的 2D 坐标。为了对时空信息进行建模,研究者首先采用空间 GCN 对每帧上的姿态特征进行独立编码,然后对得到的张量采用时间卷积来聚合时间信息。编码后的姿态特征 P 定义为:
其中,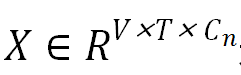 是输入特征;V 和C_n分别是关键点数和每个节点的特征维度;是邻接矩阵,根据身体和手指的关节连接定义;W_S 和 W_T 分别是空间 GCN 和时间卷积的权重矩阵。研究者通过 GCN 更新节点特征。最后对节点特征进行聚合得到编码姿态特征
是输入特征;V 和C_n分别是关键点数和每个节点的特征维度;是邻接矩阵,根据身体和手指的关节连接定义;W_S 和 W_T 分别是空间 GCN 和时间卷积的权重矩阵。研究者通过 GCN 更新节点特征。最后对节点特征进行聚合得到编码姿态特征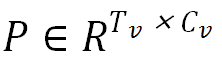 ,其中, T_v 和 C_v 分别是时间维度和特征通道数。由于音乐信号表示为 MIDI 事件序列,因此研究者将根据人体运动生成音乐视为序列预测问题。为此,研究者使用 Transformer 模型的解码器部分,该部分已展示出在序列预测中捕获长期结构的强大能力。研究者将此模型应用于运动 MIDI 转换问题。具体而言,给定视觉表征
,其中, T_v 和 C_v 分别是时间维度和特征通道数。由于音乐信号表示为 MIDI 事件序列,因此研究者将根据人体运动生成音乐视为序列预测问题。为此,研究者使用 Transformer 模型的解码器部分,该部分已展示出在序列预测中捕获长期结构的强大能力。研究者将此模型应用于运动 MIDI 转换问题。具体而言,给定视觉表征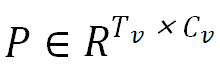 ,Transformer 解码器负责预测 MIDI 事件序列
,Transformer 解码器负责预测 MIDI 事件序列 ,其中 T_m 和 L 表示视频片段中包含的 MIDI 事件的总数以及词汇量。在每个时间步长,解码器都会将之前在 MIDI 事件上生成的特征编码和视觉姿态特征作为输入,并预测下一个 MIDI 事件。Transformer 中的核心机制是自注意力模块。该模块首先将向量序列转换为 Query,Key 和 Value,之后输出 Value 的加权和,其中权重通过 Key 和 Query 点积获得
,其中 T_m 和 L 表示视频片段中包含的 MIDI 事件的总数以及词汇量。在每个时间步长,解码器都会将之前在 MIDI 事件上生成的特征编码和视觉姿态特征作为输入,并预测下一个 MIDI 事件。Transformer 中的核心机制是自注意力模块。该模块首先将向量序列转换为 Query,Key 和 Value,之后输出 Value 的加权和,其中权重通过 Key 和 Query 点积获得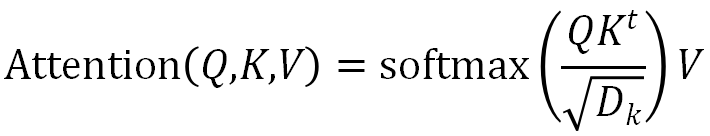
与仅使用位置正弦波来表示时序信息的 Transformer 模型不同,研究者采用相对位置使注意力明确地知道序列中两个 token 之间的距离。这对于建模音乐至关重要,因为音乐具有丰富的和弦声音,并且相对差异与音长和音高息息相关。为了解决这个问题,研究者为每个 Query 和 Key 之间可能的成对距离学习一个有序相对位置嵌入R,如下所示: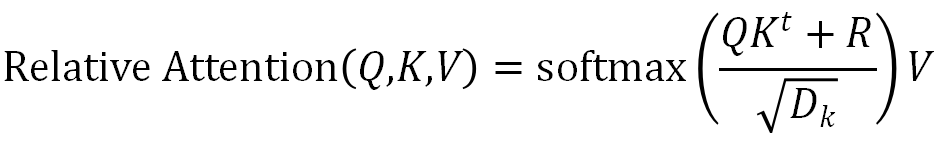
对于 MIDI 解码器,研究者首先使用具有相对位置嵌入的掩模自注意力模块来对输入的 MIDI 事件进行编码,其中 Query,Key 和 Value 均来自相同的特征编码。之后将掩模自注意力模块的输出 和姿态特征
和姿态特征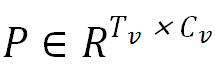 传递到多头注意力模块中,其计算公式如下:
传递到多头注意力模块中,其计算公式如下: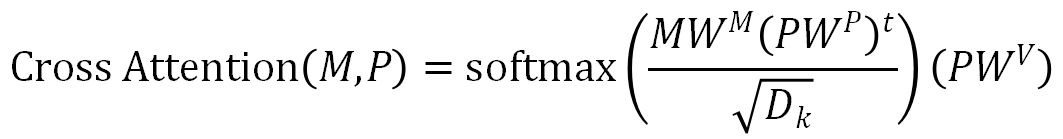
其输出通过两层全连接层和 softmax 后得到下一个 token 在词汇表中的概率分布研究者在 URMP,AtinPiano 和 MUSIC 这三个乐器演奏视频数据集上进行了实验,其中包含手风琴、贝斯、巴松管、大提琴、吉他、钢琴、大号、尤克里里和小提琴共九种不同类别乐器的大约 1000 个演奏视频。研究者将本文模型与 SampleRNN,WaveNet 和 GAN-based Model 这三种现有方法进行了比较。公平起见,为所有基准提供的姿态特征是相同的。在 AMT 上通过四个评价指标定性比较生成音乐的感知质量。(1)正确性:生成音乐与视频内容相关;(2)噪音量:生成音乐包含噪音最小;(3)同步性:生成音乐在时间上与视频匹配;(4)综合性:总体质量最佳。研究者向 AMT 工作人员展示了四个视频,这些视频具有相同的视频内容,但具有不同的声音,分别由本文方法和三个基准方法合成。AMT 工作人员需要分别根据以上指标从中选择出最佳的视频。表 1 展示了不同乐器类别的综合性指标结果,该方法在所有乐器类别上均优于基准方法。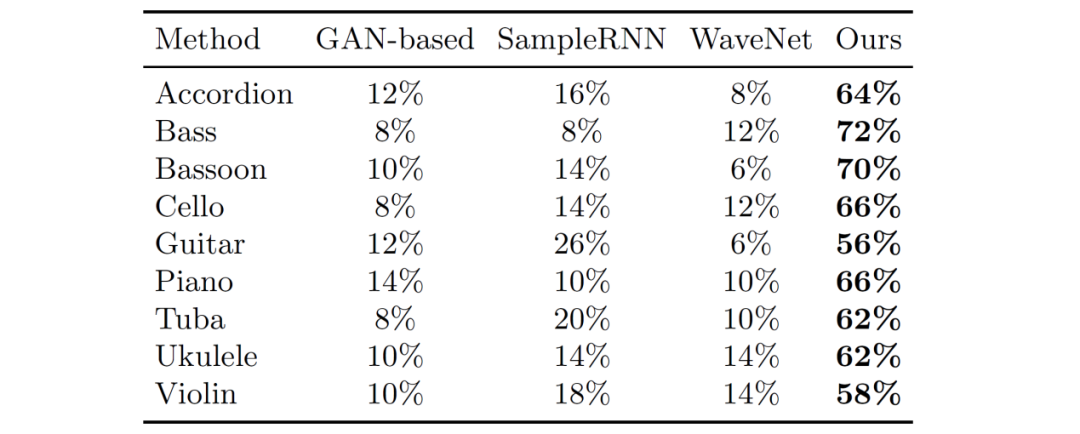
图 3 分析了正确性,噪音量和同步性指标结果。可以观察到,在所有评价指标上,该方法也始终优于并远超基准方法。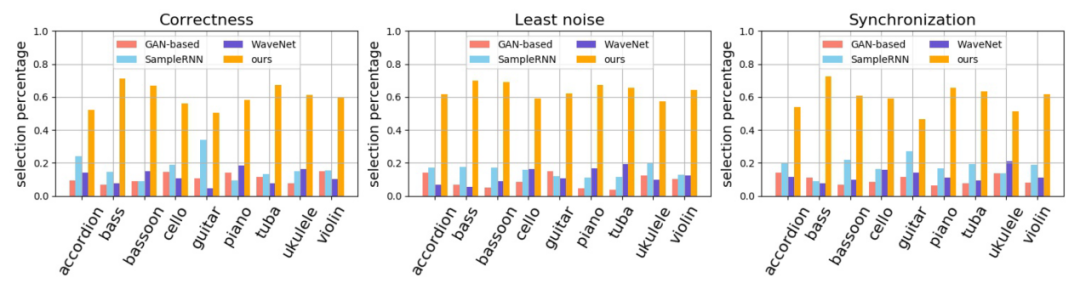
这些结果证明了本文所提出方法的有效性,即 MIDI 有助于改善声音质量,语义对齐以及时间同步。图 4 左侧展示了这一方法预测的 MIDI 和 GT 之间的对比。可以观察到,该方法所预测的 MIDI 与 GT 非常相似。图 4 右侧展示了不同方法生成的声谱图结果。可以发现该方法比其他基准方法生成了更多的结构化谐波分量。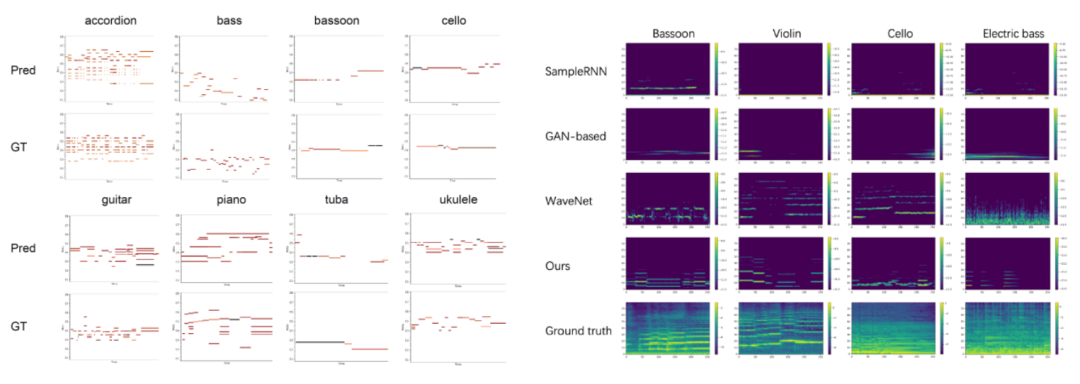
基于 MIDI 的可解释性和灵活性,可以通过 MIDI 文件轻松地进行音乐编辑,生成不同风格音乐,如图 5 所示。这对于以前使用波形或频谱图作为音频表示形式的系统而言难以实现。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





