干货 :使用Spark进行大规模图形挖掘(附链接)
本文约4700字,建议阅读15分钟
下文可回顾示例图和笔记:
https://github.com/wsuen/pygotham2018_graphmining

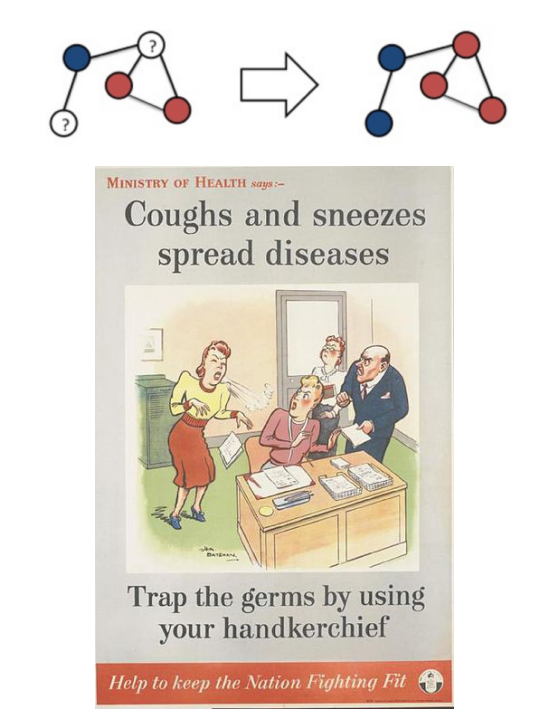
带标签的数据很好,但不是必需的。使LPA适用于我们的无监督机器学习用例。
参数调整非常简单。LPA使用max_iterations参数运行,并且使用默认值5就可以获得良好的结果。Raghavan和她的合作者针对几个标记的网络测试了LPA。他们发现至少有95%的节点在5次迭代中被正确分类。
集群的先验数量,集群的大小,不需要其他指标。如果你不希望图形具有特定的结构或层次结构,那么这一点至关重要。我没有关于网络图的网络结构、拥有数据的社区数量或这些社区的预期规模的先验假设。
接近线性运行时间。LPA的每次迭代均为O(m),与边数成线性。与此前某些社区检测解决方案的O(n log n)或O(m + n)相比,整个步骤的顺序接近线性时间。
可解释性。可以给别人解释为什么将节点分到某个社区。

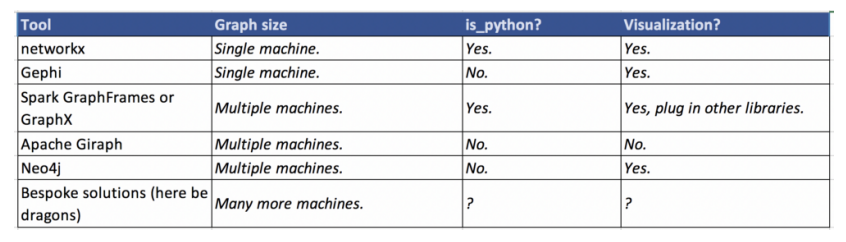
请记住:适合您的项目的最佳图形库取决于语言,图形大小,存储图形数据的方式以及个人喜好!

# add GraphFrames package to spark-submitimport osos.environ['PYSPARK_SUBMIT_ARGS'] = '--packages graphframes:graphframes:0.6.0-spark2.3-s_2.11 pyspark-shell'import pyspark# create SparkContext and Spark Sessionsc = pyspark.SparkContext("local[*]")spark = SparkSession.builder.appName('notebook').getOrCreate()# import GraphFrames
# show 10 nodesvertices.show(10)+--------+----------------+| id|name|+--------+----------------+|000db143|msn.com||51a48ea2|tradedoubler.com||31312317|microsoft.com||a45016f2|outlook.com||2f5bf4c8|bing.com|+--------+----------------+only showing top 5 rows# show 10 edgesedges.show(10)+--------+--------+| src|dst|+--------+--------+|000db143|51a48ea2||000db143|31312317||000db143|a45016f2||000db143|31312317||000db143|51a48ea2|+--------+--------+only showing top 5 rows
# create GraphFramegraph = GraphFrame(vertices, edges)# run LPA with 5 iterationscommunities =graph.labelPropagation(maxIter=5)communities.persist().show(10)+--------+--------------------+-------------+| id| name| label|+--------+--------------------+-------------+|407ae1cc| coop.no| 781684047881||1b0357be| buenacuerdo.com.ar|1245540515843||acc8136a| toptenreviews.com|1537598291986||abdd63cd| liberoquotidiano.it| 317827579915||db5c0434| meetme.com| 712964571162||0f8dff85| ameblo.jp| 171798691842||b6b04a58| tlnk.io|1632087572480||5bcfd421| wowhead.com| 429496729618||b4d4008d|investingcontrari...| 919123001350||ce7a3185| pokemoncentral.it|1511828488194|+--------+--------------------+-------------+only showing top 10 rows
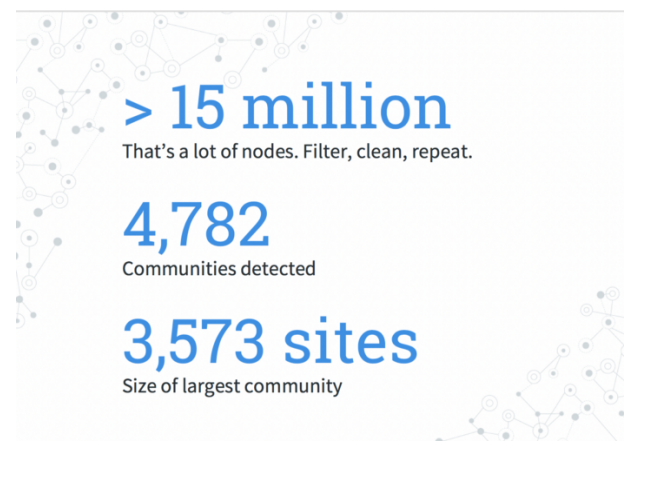
LPA发现了4,700多个社区。但是这些社区中有一半以上仅包含一个或两个节点。
在规模范围的另一端,最大的社区是3500多个不同的网站!为了给出范围的概念,这大约是我最终图形后过滤中节点的5%。

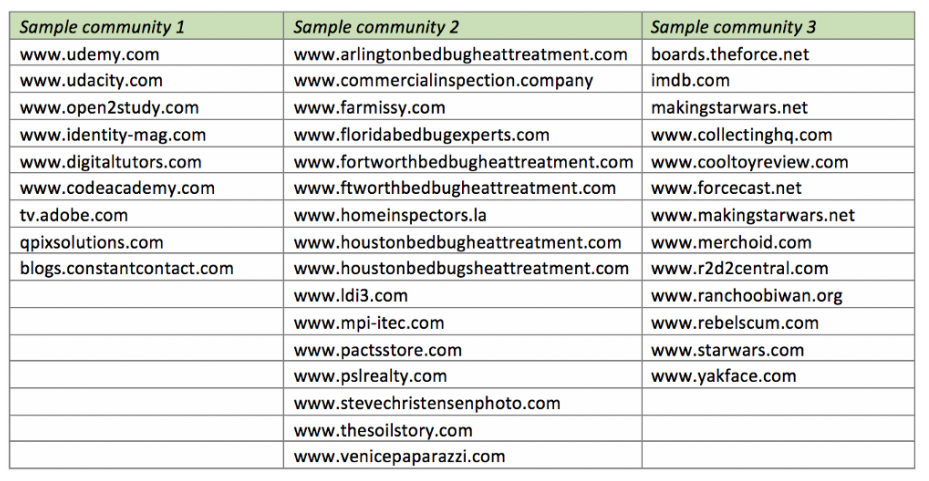
电子学习站点:与电子学习页面相关或链接到该站点的站点。是时候找一些新的数据科学MOOC了!
Bedbug网站:与房地产和臭虫相关的网站。所有这些站点都使用相同的模板/图像,只是域名略有不同,数量不止于此。
《星球大战》社区:谈论《星球大战》电影,事件和纪念品的站点经常相互链接。
分层并传播元数据:如果我们向数据添加诸如边权重,链接类型或外部标签之类的信息,那么如何在图中传播此信息呢?
删除/添加节点并衡量对社区的影响:我很好奇如何添加或删除具有较高边缘集中度的节点会改变LPA的有效性和最终社区的质量。
观察网络图随时间的演变:每个月都有一个新的Common Crawl数据集!观察随着时间的推移会出现什么集群会很有趣。相反,哪些社区保持不变?我们知道,互联网不是一成不变的。

我们是先驱者!
Adamic, Lada A., and Natalie Glance. “The political blogosphere and the 2004 US election: divided they blog.” Proceedings of the 3rd international workshop on Link discovery. ACM, 2005.
Common Crawl dataset (September 2017).
Farine, Damien R., et al. “Both nearest neighbours and long-term affiliates predict individual locations during collective movement in wild baboons.” Scientific reports 6 (2016): 27704
Fortunato, Santo. “Community detection in graphs.” Physics reports 486.3–5 (2010): 75–174.
Girvan, Michelle, and Mark EJ Newman. “Community structure in social and biological networks.” Proceedings of the national academy of sciences99.12 (2002): 7821–7826.
Leskovec, Jure, Anand Rajaraman, and Jeffrey David Ullman. Mining of massive datasets. Cambridge University Press, 2014.
Raghavan, Usha Nandini, Réka Albert, and Soundar Kumara. “Near linear time algorithm to detect community structures in large-scale networks.” Physical review E 76.3 (2007): 036106.
Zachary karate club network dataset — KONECT, April 2017.
译者简介:陈丹,复旦大学大三在读,主修预防医学,辅修数据科学。对数据分析充满兴趣,但初入这一领域,还有很多很多需要努力进步的空间。
转自: 数据派THU 公众号;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

![廖miko:“比起“你要不要”, “这个给你”更让人感到幸福[爱心]。” ](https://imgs.knowsafe.com:8087/img/aideep/2021/7/14/c324e8461dcf74cb64ccbcc628d1e785.jpg?w=250)




 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 构建人与自然和谐共生的地球家园 4951904
- 2 深圳天空一秒变黑 4988838
- 3 多名斗鱼主播已成消失的她 4801523
- 4 世界读书日 4763975
- 5 禁止大学生宿舍挂床帘有必要吗? 4614776
- 6 男子照顾孤寡老人12年继承北京5套房 4558405
- 7 村支书回应种地先交钱:县里让收的 4488672
- 8 张朝阳谈如何应对焦虑 4312579
- 9 官方辟谣薪资9千招档案管理员 4228240
- 10 小蛮腰一小时接了六次闪电 4179341