王者荣耀「绝悟」升级,全英雄池解禁!网友:会进化的AI太可怕了!

??新智元报道??
??新智元报道??
编辑:QJP、小匀
【新智元导读】11月28日,由腾讯 AI Lab 与王者荣耀联合研发的策略协作型 AI「绝悟」推出升级版本「绝悟完全体」?。新算法将AI可用英雄池数量从40个增至100+个,还优化了禁选英雄博弈策略,其相关研究已被 AI 顶级会议 NeurIPS 2020 与顶级期刊 TNNLS 收录。

 ? ? ? ?
? ? ? ? ? ? ? ?
? ? ? ?
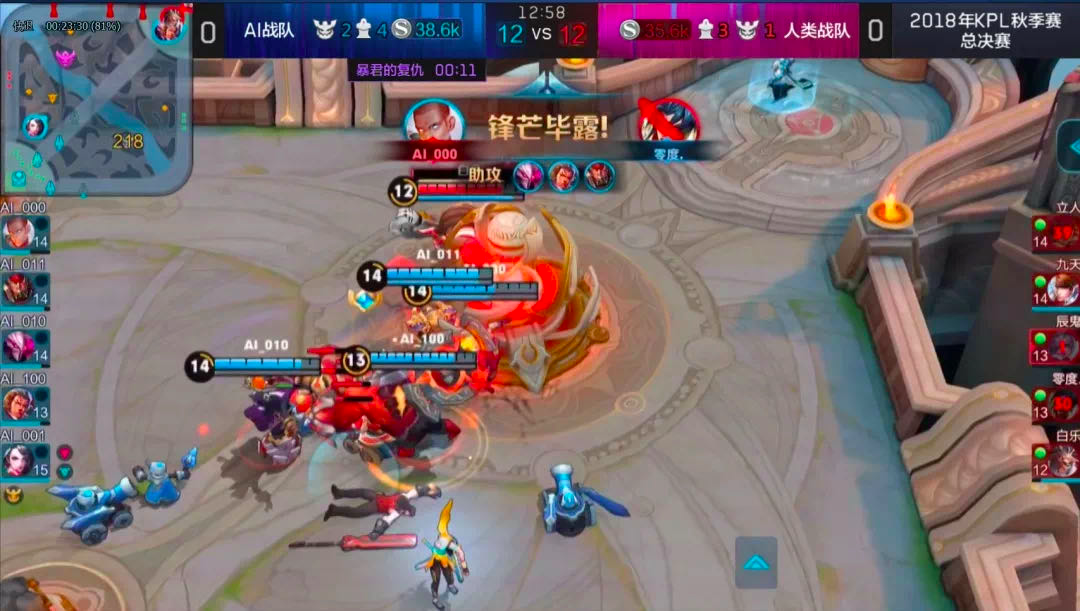
在王者荣耀中,若每个职业都有4个紫色熟练度英雄,你就能解锁「全能高手」称号。但因为练习时间与精力限制,很少有人能精通所有英雄。
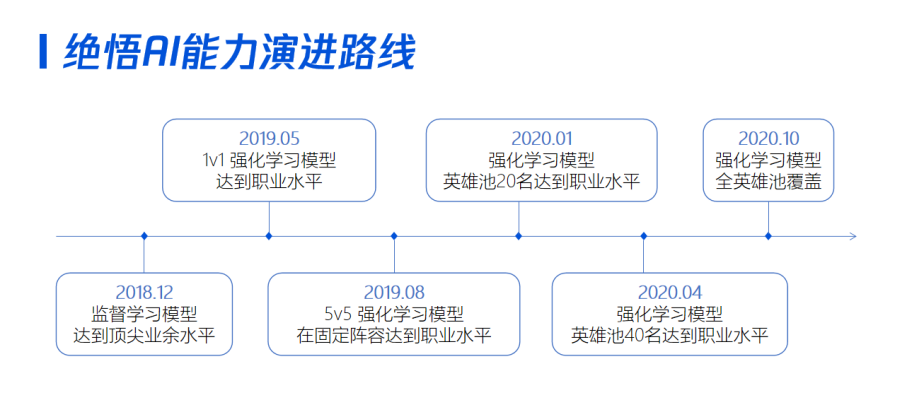 ? ? ?
? ? ?绝悟:前有强兵开路,后有军师辅佐,一代宗师终练成
 ? ? ?
? ? ?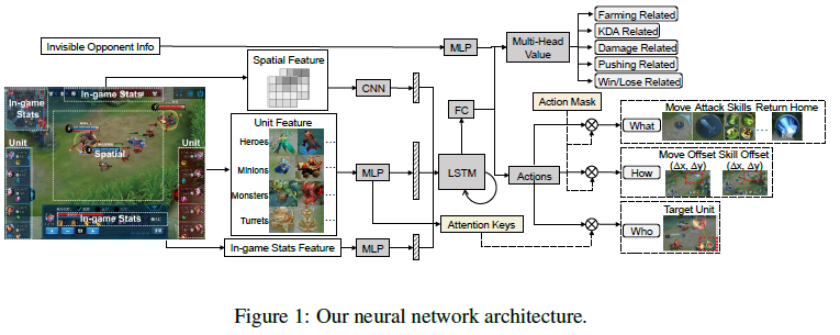 图:网络结构
图:网络结构 图:CSPL流程图。设计思想:任务由易到难,模型从简单到复杂,知识逐层深入
图:CSPL流程图。设计思想:任务由易到难,模型从简单到复杂,知识逐层深入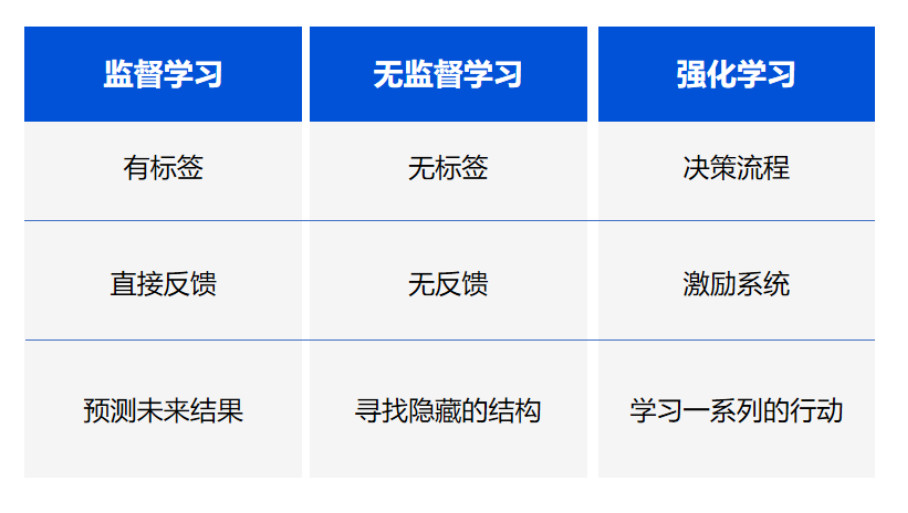
 ? ? ?
? ? ?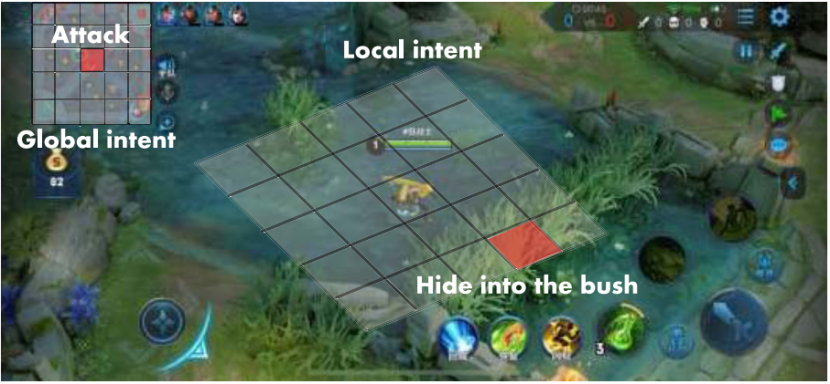 图1:大局观的多视角意图标签
图1:大局观的多视角意图标签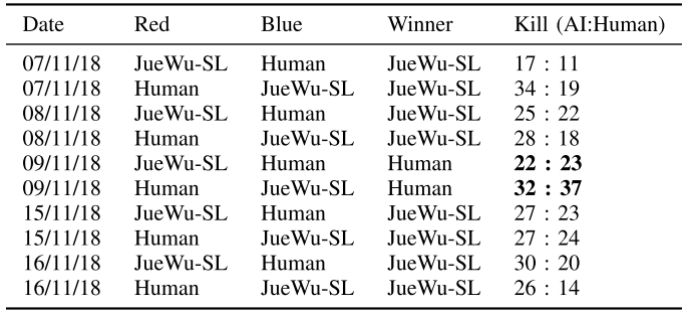 ??
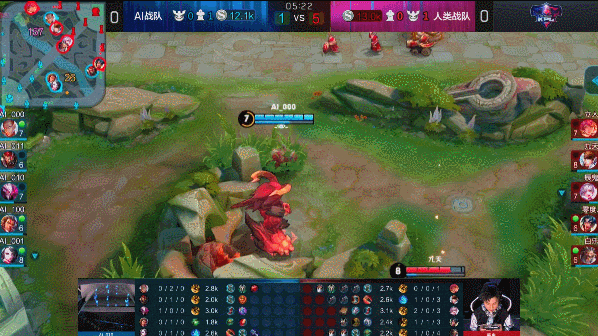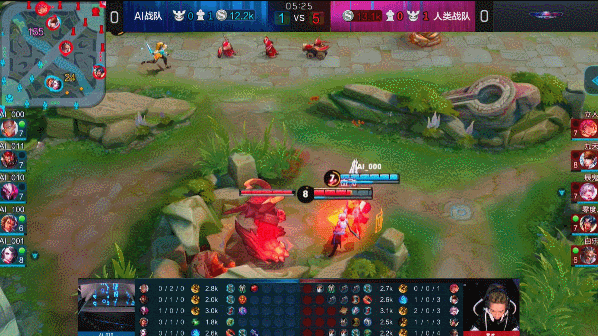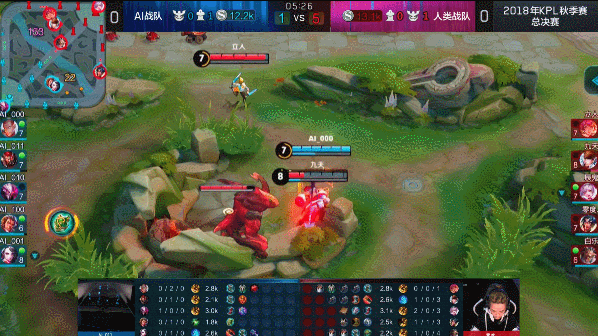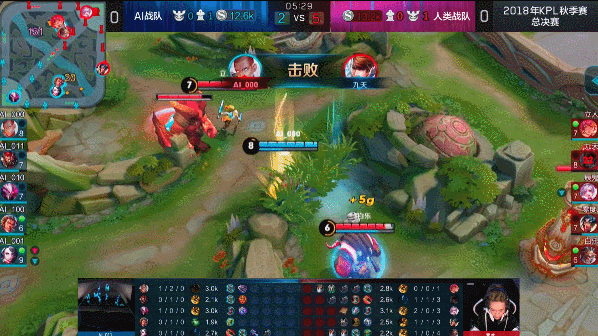
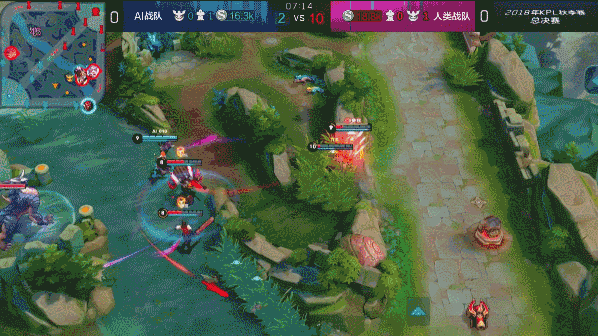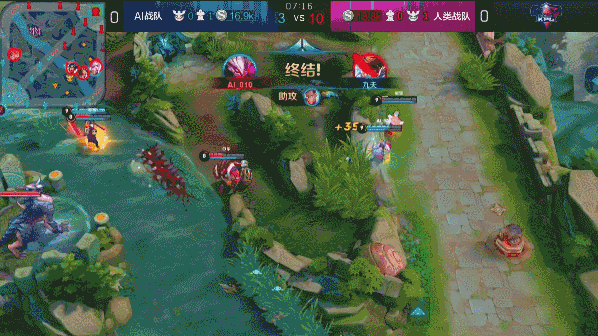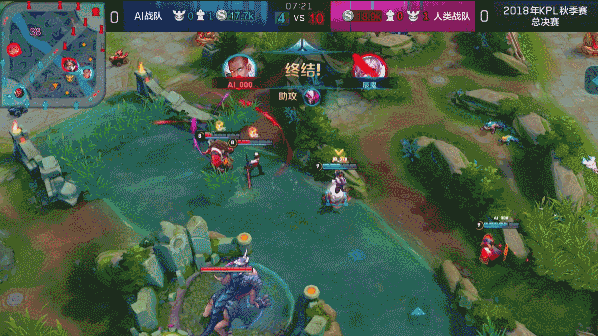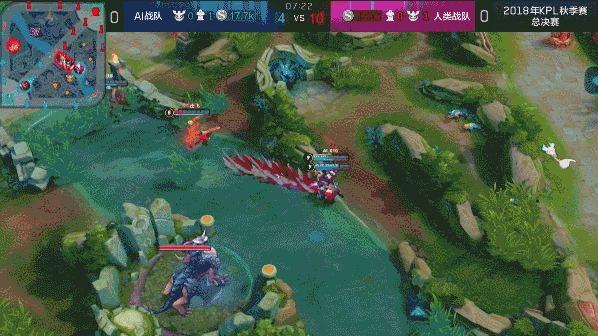
?? 图:达摩蹲草埋伏击杀赵云
图:达摩蹲草埋伏击杀赵云

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/



![四喜戴娜 这么好看的花 当然要拍照记录啦~[兔子] ](https://imgs.knowsafe.com:8087/img/aideep/2022/8/15/f99c49f73e99075a3c87e5987a9e0c17.jpg?w=250)


 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 打好关键核心技术攻坚战 7904069
- 2 在南海坠毁的2架美国军机已被捞出 7809352
- 3 立陶宛进入紧急状态 卢卡申科发声 7714385
- 4 持续巩固增强经济回升向好态势 7618361
- 5 多家店铺水银体温计售空 7521489
- 6 奶奶自爷爷去世9个月后变化 7429075
- 7 仅退款225个快递女子已归案 7328746
- 8 日舰曾收到中方提示 7231753
- 9 沙特拟建2000米世界第一高塔 7138469
- 10 我国成功发射遥感四十七号卫星 7047906