在最新的 NLU 测试基准 SuperGLUE 中,微软提出的 DeBERTa 登顶榜单,并超越人类。
去年 6 月,来自微软的研究者提出一种新型预训练语言模型 DeBERTa,该模型使用两种新技术改进了 BERT 和 RoBERTa 模型。8 月,该研究开源了模型代码,并提供预训练模型下载。最近这项研究又取得了新的进展。微软最近通过训练更大的版本来更新 DeBERTa 模型,该版本由 48 个 Transformer 层组成,带有 15 亿个参数。本次扩大规模带来了极大的性能提升,使得单个 DeBERTa 模型 SuperGLUE 上宏平均(macro-average)得分首次超过人类(89.9 vs 89.8),整体 DeBERTa 模型在 SuperGLUE 基准排名中居于首位,以 90.3 的得分显著高出人类基线(89.8)。目前该模型以 90.8 的宏平均(macro-average)得分高居 GLUE 基准排名的首位。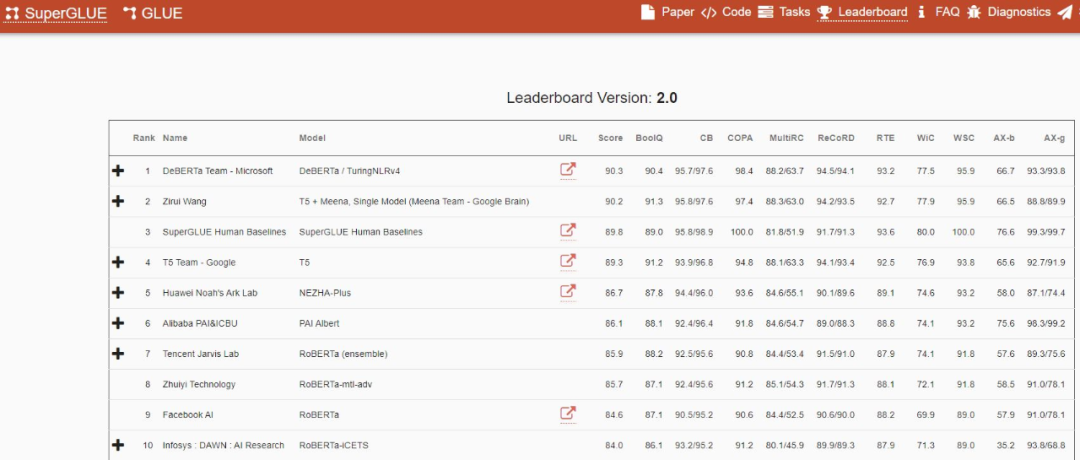
SuperGLUE 排行榜,2021 年 1 月 6 日。DeBERTa 是一种基于 Transformer,使用自监督学习在大量原始文本语料库上预训练的神经语言模型。像其他 PLM 一样,DeBERTa 旨在学习通用语言表征,可以适应各种下游 NLU 任务。DeBERTa 使用 3 种新技术改进了之前的 SOTA PLM(例如 BERT、RoBERTa、UniLM),这 3 种技术是: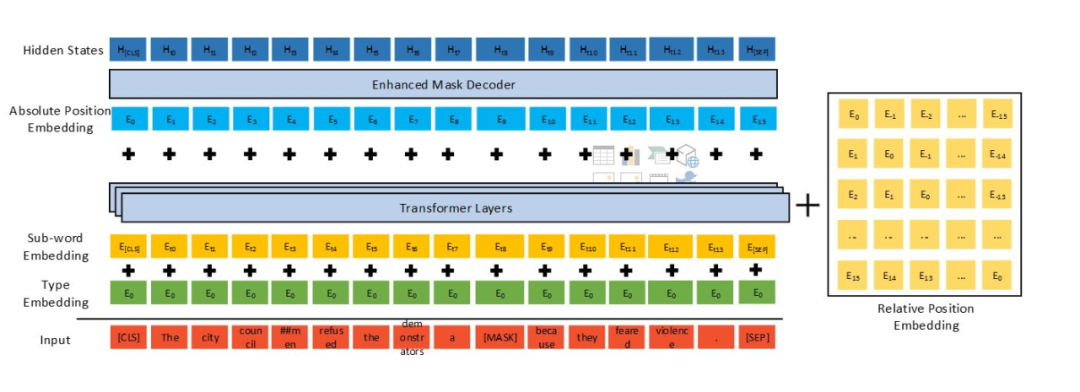
最近该研究在 arXiv 上提交了 DeBERTa 的最新论文,文中详细介绍了 DeBERTa 模型的方法及最新的实验结果。
论文链接:https://arxiv.org/pdf/2006.03654v2.pdf与 BERT 不同,DeBERTa 中每个词使用两个对其内容和位置分别进行编码的向量来表示,使用分解矩阵分别根据词的内容和相对位置来计算词间的注意力权重。采用这种方法是因为:词对的注意力权重(衡量词与词之间的依赖关系强度)不仅取决于它们的内容,还取决于它们的相对位置。例如,「deep」和「learning」这两个词在同一个句子中接连出现时的依赖关系要比它们出现在不同句子中强得多。与 BERT 一样,DeBERTa 也使用掩码语言建模(MLM)进行了预训练。DeBERTa 将语境词的内容和位置信息用于 MLM。分解注意力机制已经考虑了语境词的内容和相对位置,但并没有考虑这些词的绝对位置,但这在很多情况下对于预测至关重要。例如句子「a new store opened beside the new mall」其中,「store」和「mall」在用于预测时被掩码操作。尽管两个词的局部语境相似,但是它们在句子中扮演的句法作用是不同的。(例如,句子的主角是「store」而不是「mall」)。这些句法上的细微差别在很大程度上取决于词在句子中的绝对位置,因此考虑单词在语言建模过程中的绝对位置是非常重要的。DeBERTa 在 softmax 层之前合并了绝对词位置嵌入,在该模型中,模型根据词内容和位置的聚合语境嵌入对被掩码的词进行解码。虚拟对抗训练是一种提升模型泛化性的正则化方法。它通过提高模型对对抗样本(adversarial examples)的鲁棒性来实现这一点,其中对抗样本是通过对输入进行细微的干扰而创建的。对模型进行正则化,以便在给出一种特定任务样本时,该模型产生的输出分布与在该样本的对抗型干扰版本上产生的输出分布相同。对于 NLU 任务,干扰被用于词嵌入,而不是原始的词序列。但是,嵌入向量的值范围(范数)在不同的词和模型上有所不同。对于具有数十亿个参数的较大模型,方差会比较大,从而导致对抗训练不稳定性。受层归一化的启发,为了提高训练稳定性,该研究开发了一种规模不变的微调(Scale-Invariant-Fine-Tuning (SiFT))方法,该方法将干扰用于归一化的词嵌入。该研究用实验及结果评估了 DeBERTa 在 NLU 和 NLG 的各种 NLP 任务上的性能。受此前 BERT、 RoBERTa 和 XLNet 等论文的影响,该研究使用大型模型和基础模型进行结果展示。
表 1 总结了 8 个 GLUE 任务的结果,其中将 DeBERTa 与具有类似 transformer 结构的一些模型进行了比较,这些模型包括 BERT、 RoBERTa、XLNet、ALBERT 以及 ELECTRA。注意,RoBERTa、 XLNet 以及 ELECTRA 训练数据的大小为 160G,而 DeBERTa 训练数据大小为 78G。该研究还对 DeBERTa 进行了一些其他的基准评估:
表 2:在 MNLI in/out-domain、 SQuAD v1.1、 SQuAD v2.0、 RACE、 ReCoRD、 SWAG、 CoNLL 2003 NER 开发集上的结果展示。基础模型预训练的设置与大型模型的设置类似,基础模型结构遵循 BERT 的基础模型结构,性能评估结果如表 3 所示。
表 3:在 MNLI in/out-domain (m/mm)、SQuAD v1.1 和 v2.0 开发集上的结果对比。该研究在数据集 Wikitext-103 上,进一步对带有自回归语言模型 (ARLM) 的 DeBERTa 模型进行了评估。
表 4:在 Wikitext-103 数据集上,不同语言模型对比结果。DeBERTa_base 在开发集和测试集上都获得了比较好的 PPL 结果,MLM 和 ARLM 联合训练进一步降低了 PPL,这展示了 DeBERTa 的有效性。消融实验:为了验证实验设置,该研究从头开始预训练 RoBERTa 基础模型。并将重新预训练的 RoBERTa 称为 RoBERTa-ReImp_base。为了研究 DeBERTa 模型不同部分对性能的影响,研究人员设计了三种变体:EMD 表示没有 EMD 的 DeBERTa 基础模型;
C2P 表示没有内容到位置 term 的 DeBERTa 基础模型;
P2C 表示没有位置到内容 term 的 DeBERTa 基础模型。由于 XLNet 也使用了相对位置偏差,所以该模型与 XLNet + EMD 模型比较接近。

表 5 总结了 DeBERTa 基础模型消融实验在四个基准数据集上的结果。为了研究模型预训练的收敛性,该研究以预训练 step 数的函数的形式可视化微调下游任务的性能,如图 1 所示,对于 RoBERTa ReImp 基础模型和 DeBERTa 基础模型,该研究每 150K 个预训练 step 存储一个检查点,然后对两个有代表性的下游任务(MNLI 和 SQuAD v2.0)上的检查点进行微调,之后分别报告准确率和 F1 得分。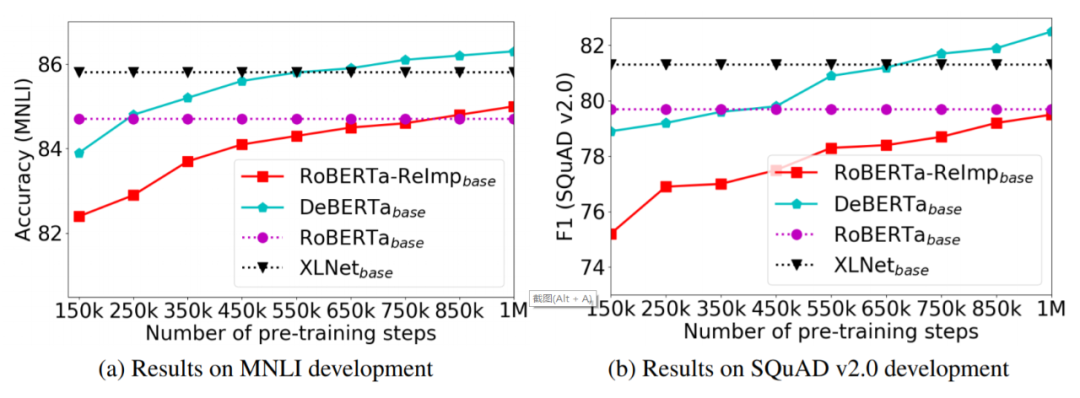
图 1:DeBERTa 及其相似模型在 MNLI 、 SQuAD v2.0 开发集上的预训练性能曲线。更大的预训练模型会显示出更好的泛化结果。因此,该研究建立了一个拥有 15 亿个参数的 DeBERTa,表示为 DeBERTa_1.5B,该模型有 48 层。在 160G 预训练数据集上训练 DeBERTa_1.5B,并且使用数据集构造了一个大小为 128K 的新词汇表。
表 6:DeBERTa_1.5B 和其他几种模型在 SuperGLUE 测试集上的结果。https://www.microsoft.com/en-us/research/blog/microsoft-deberta-surpasses-human-performance-on-the-superglue-benchmark/© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





