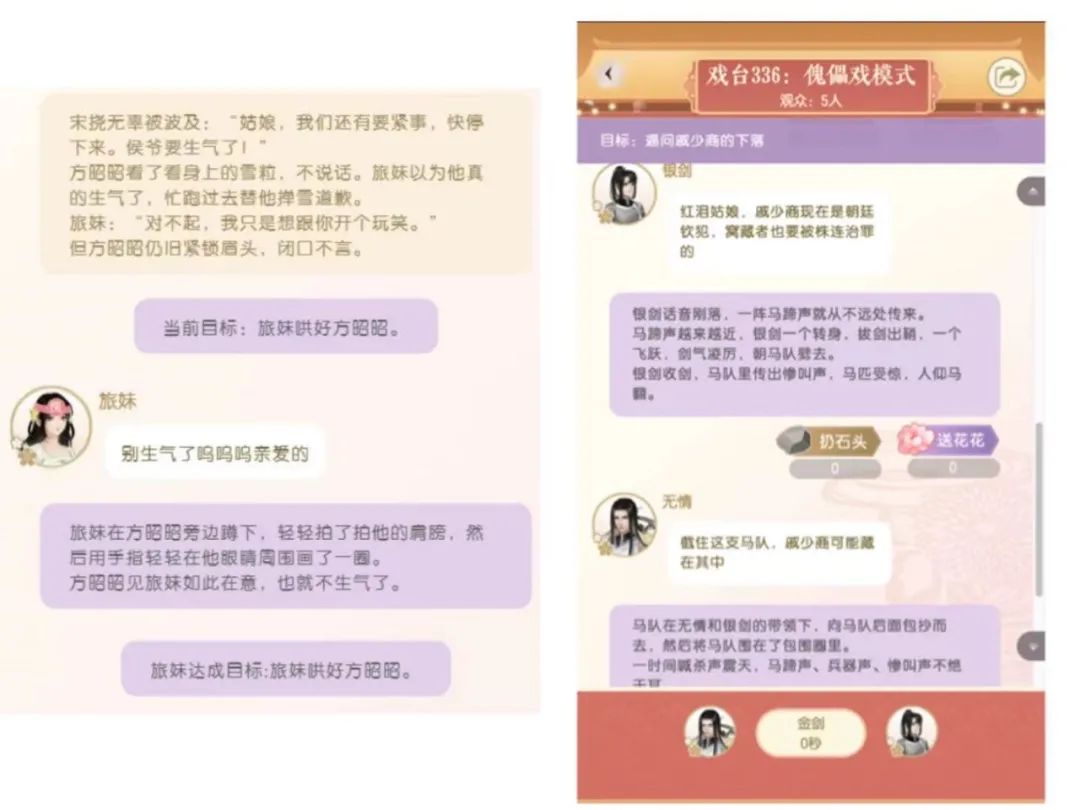
近日,国际AI顶尖学术会议ACL 2021(Annual Meeting of the Associationfor Computational Linguistics)公布了论文录用结果。网易伏羲共有三项研究被本届ACL收录,内容包括自然语言生成、无监督文本表示学习等方向,相关技术已应用于游戏、文创及智慧文旅等行业。ACL由国际计算语学协会主办,是自然语言处理(NLP)与计算语言学领域最高级别的学术会议,被中国计算机学会(CCF)列为A类国际学术会议,涵盖语言分析、信息抽取、机器翻译与自动问答等各个领域。本届ACL共收到3350篇论文投稿,其中主会论文录用率为21.3%。除三篇收录论文外,网易伏羲提交的一篇演示论文(Demo Paper)也引发了评审高度关注。该论文主要探讨手游《遇见逆水寒》中所采用的“大宋傀儡戏”玩法。傀儡戏起源于汉代,又名木偶戏。游戏中,AI就像傀儡,而玩家则是提线操控的“傀儡师”。根据玩家输入的语句,AI能自动编写故事,与玩家共创剧本。据了解,“大宋傀儡戏”玩法是中文领域首个采用大规模预训练语言模型的开放域文字游戏,融入了网易伏羲的多项算法创新。一方面,网易伏羲通过设置剧情目标、任务奖励等玩法创新方式,规避了游戏中滥用AI编剧的情况发生;另一方面,通过在模型压缩、推理加速等多个环节进行创新,线上服务的成本也得以有效降低。目前,网易伏羲正在利用更大规模的预训练语言模型,持续优化该玩法,为玩家带去更好的体验。《OpenMEVA:一个评估开放式故事生成指标的基准数据集》在自然语言生成(NLG)领域,如何尽量客观、准确地评价AI自动生成的文本质量,是一大行业难题。目前,主要有两种评估NLG系统的方法:人工评估和自动评估指标。相较之下,人工评估在准确性和有效性上更胜一筹,自动评估指标则在成本和效率上更具优势。随着NLG的快速发展,现有的评估方式越来越难以满足行业痛点,一系列评估NLG系统质量的新方法也应运而生。由于缺乏标准化的基准数据集,无论是全面衡量指标的能力,还是比较不同指标的性能,都极为困难。为此,网易伏羲与清华大学的黄民烈老师团队合作提出了一个针对自动评估指标的基准数据集“OpenMEVA”。借助“OpenMEVA”,可以全面评估针对开放式故事的自动评估指标性能:包括自动生成指标与人工评估的相关性,对不同模型输出和数据集的泛化能力,故事语篇连贯性能力,以及对扰动的稳健性等。《人工位置信息残留会通过MLM预训练模型动态词向量传播》文本表示学习,是指将文本字符串表示转化成计算机能处理的分布式表示的过程。文本表示学习是基于深度学习的自然语言处理的基础,良好的文本表示可以大幅提升算法效果。本研究中,网易伏羲基于掩码语言模型(Masked LanguageModel),从预训练语言模型中抽取了各层文本分布式表示,并从中发现了一个共同但并不理想的特征:在BERT和RoBERTa的隐状态向量中,持续存在有离群神经元的情况。在SST-2和QQP数据集上的Bert-base各层平均向量为研究该问题的根源,网易伏羲引入了一种神经元级别的分析方法。该方法显示,异常值与位置嵌入(Position Embedding)所捕获的信息密切相关,而这些异常值是造成编码器原始向量空间各向异性的主要原因。通过剪除这些异常值,可以提高各向量的相似度。剪切后的向量可以更准确地区分词义;同时,使用均值池化(Mean Pooling)后,可以得到更好的句子嵌入。《通过对句子层面和语篇层面的一致性进行建模来生成长文本》AI自动生成连贯的长文本,本身就是一项极具挑战的任务。而故事生成这类开放式的文本生成任务则更为困难。尽管在句内连贯性上,现有的大规模语言模型表现不俗,但要保持整体生成文本的连贯性,依旧非常困难。这是因为在上下文中,很难捕捉到超越token级别共现的高级语义和语篇结构。本研究中,网易伏羲和清华大学黄民烈老师团队合作提出了一个长文本生成模型,可以在解码过程中,在句子层面和语篇层面上表示上下文。借助两个预训练任务,模型通过预测句子间的语义相似性、区分正常和打乱的句子顺序来学习表征。实验表明,在生成文本的连贯性上,该模型优于现有最先进的基线模型。关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/


















 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





