网易云音乐 DBA 谈 TiDB 选型:效率的选择
编者按
本文摘自由网易 DBA 团队撰写的《效率的选择——分布式数据库 TiDB 网易内部选型介绍》一文,对比了以 TiDB 为基础的创新架构和 MySQL + DDB 传统架构的差异,从业务适配、降本增效、技术创新等多个维度阐释了网易考虑引入 TiDB 的原因。
作者倪山三(hznishansan@corp.netease.com),网易数据库专家,杭研数据库运维团队负责人。
DDB 是网易内部自研的 MySQL 之上的水平分布式中间件,可以类比为 ShardingShpere 或者 Vitess。
分布式数据库技术发展背景
随着各⽅⾯成本有着显著优势的 PC Server 趋于绝对主流,现在提到数据库,很少有⼈会想到⼩型机和盘柜时代的 Oracle 或 DB2 这样⼀个柜⼦⼏百 T 的⼤型集中式数据库了。但是业务数据量和请求量仍然在不断增⻓,因此近年来我们就要依赖分布式数据库技术,利⽤⼩规格的 PC Server 资源,提供⼤体量的集群式服务。
要尽可能完整地⽀持包括 CRUD 和 DDL 在内的 SQL,同时要⽀持事务特性,满⾜这两点才能算的上是⼀个(关系型)数据库
通过统⼀集群入⼝提供服务,屏蔽内部分布式细节
要有伸缩能⼒,⽆论通过何种⼿段,数据库要能满⾜持续增⻓的存量数据和吞吐能⼒要求
作为最重要的中间件,服务应对软硬件故障的⾼可⽤特性也是重要考虑点

sharded storage(线路 3)⽅案虽然技术含量很⾼,从性能到吞吐能⼒都⽆可指摘,但终归是完全的商业化⽅案。我们并不排斥,将在公有云场景中适时地充分利⽤,但是依赖特殊供应商的商业⽅案显然并不能作为孤注⼀掷的唯⼀选型,除非有相对开放的⽅案出现(好消息是⽹易数科也确实在这⽅⾯进⾏研发,并已经取得进展)。
DDB 是⽹易⾃研的,基于 MySQL 的分库分表型(线路 1)中间件,也是当前我们的主流选型。在这⼀⼤类型的分布式⽅案中,各种开源中间件的功能,实现⽅式都非常雷同,其他任何⽅案与 DDB 相比都不存在同质竞争的明显优势,⽽各⾃缺点都很突出,不如 DDB 普适。因此在中间件这⼀流派,DDB 就是最优解。但是分库分表中间件在如今的业务使⽤场景中逐渐遇到⼀些效率⽅⾯的问题,这也本⽂接下来的主要论述重点,为啥我们有 DDB 分布式⽅案的情况下还需要尝试新的分布式数据库技术。
这样剩下的就只有 NewSQL(线路 2)了,要看是否能解决我们在 DDB 中间件⽅案中遇到的痛点了。⽽ NewSQL 三⼤代表中只有 TiDB 是主打 MySQL 兼容,特别是 YugabyteDB ⼲脆 Postgres 为主,所以我们聚焦的重点⾃然⽽然变成了 DDB VS TiDB。
TiDB 选型优势与传统分布式⽅案⽐较分析
最本质的问题其实是我们是否需要,为什么需要引入 TiDB 技术。如上所言,我们希望通过新⼀代数据库运⽤,来解决或改善当前 MySQL 分布式中间件模式使⽤中的⼀些问题。都有哪些问题、TiDB 如何改善,我们将展开详细介绍。
优势概览
提供 DDB 同等的⽔平扩容能⼒
SQL⽀持能⼒较 DDB 好
资源扩缩容粒度更加灵活,不需要像 DDB,每次都翻倍扩容
扩容⾏为效率和安全性
数据存储成本⼀定程度降低(不需要 raid10+rocksdb 压缩-rockdb 写放⼤)
在线 DDL⽀持更好,除了加索引基本都是秒回,⼤表增加修改列成本显著降低
主从复制效率显著提⾼,降低写负载下⼀致性和⾼可⽤降级的⻛险
数据⼀致性下限提升
⾼可⽤⾃动恢复可靠性与效率显著提升
HTAP 能⼒能够减少数据传输环节的成本和⻛险, 提供业务更⾼效的实时分析能⼒
SQL ⽀持能⼒较传统 hash 分表模式得到提升
不⽀持存储过程/触发器, 不⽀持 select into 变量不⽀持 MySQL 较新的 WITH ROLLUP 开窗
不⽀持外键约束
不⽀持视图上的 DML 更新基表
不⽀持显式 XA 流程控制 (因此虽然 MySQL 兼容但⽆法作为 DDB 的存储节点)
不⽀持 savepoint 制
5.0 之前的版本不⽀持 DECIMAL 精度修改
⾃增 ID(AUTO_INCREMENT), 由每个 TiDB server 独立分配, 能保证全局唯⼀, 且单个 TiDB server 内递增, 但是⽆法保证全局递增, 以及没有任何连续性保证。这个其 实和 DDB 的批量分配唯⼀ID 造成结果类似的。
单⾏单列⻓度限制, 都是定死的 6MB, 也就是 KV 的单个 key entry 上限就是 6MB, MySQL ⾥可以通过 longtext/longblob 等突破到 G 级的记录⻓度, 在 TiDB 不适⽤(虽然数据类型是预留了,但是⽂档描述有误)。
事务⻓度限制,在使⽤乐观事务并开启事务重试的情况下默认限制 5000,可调整,同时我们不太可能⼴泛使⽤乐观锁模式,因此影响不⼤。其他以前很坑的事务⾏数限制 30W,总⼤⼩ 100MB 等在 4.0 后不存在了。
⽔平扩容实际效率和能⼒显著提升
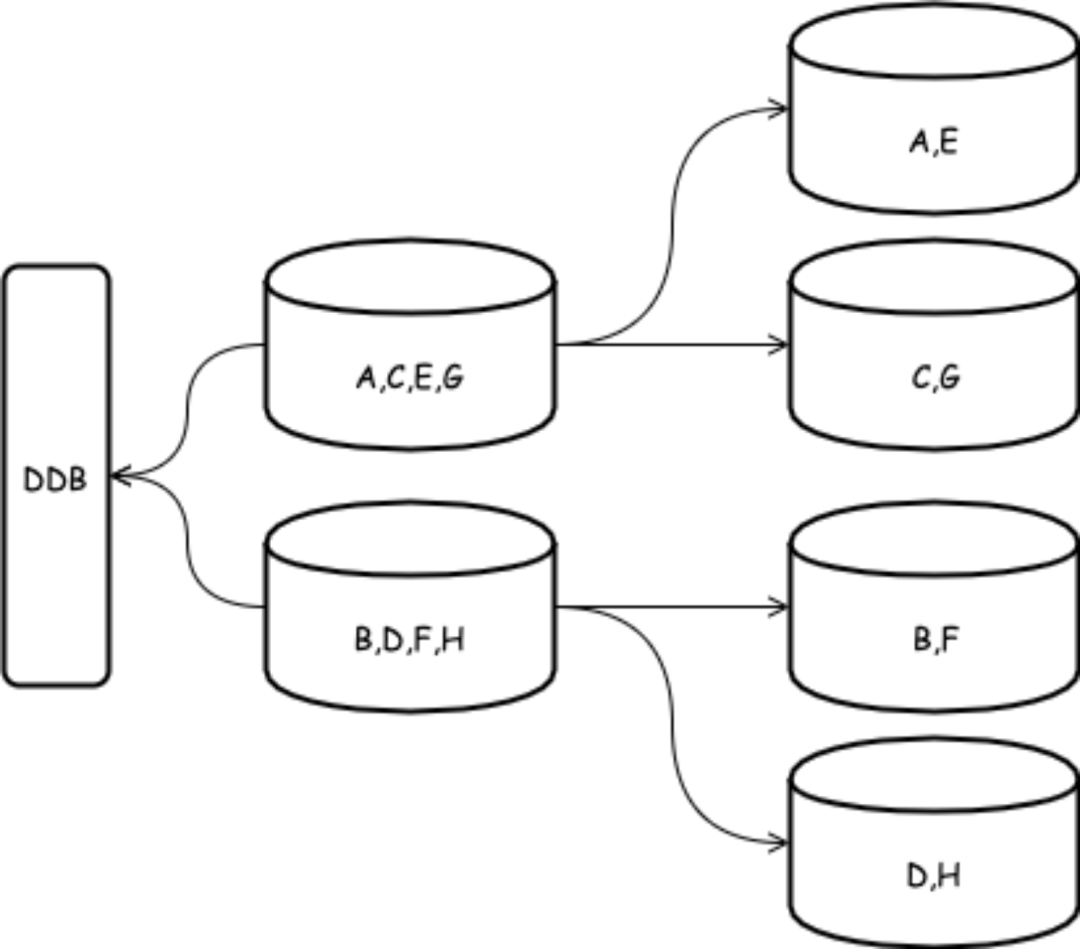
⾸先是必须成倍的资源投入。我们内部较⼤规模的 DDB 集群数据存储量有百 T 这个量级,这是 8 年存量的结果,这个存量情况下数据的增量很难再出现成倍爆发式增⻓。但是传统⼀拆⼆模式下的扩容通常要求成倍的新资源投入,拆完后⽔位从 100% ⼀下回到 50%,⽽⼀年实际增⻓可能还不到 15%,这个⼀次扩容的投入成本效率可⻅⼀斑。当然我们可以同重新 hash 等⽅式使⽤比例扩容,技术上是做的到的,但是下⾯就要讨论时间和稳定性成本了。
其次是扩容过程效率太低了,我们有多种⽅式完成存量数据的迁移以及增量数据实时同步,技术上没有问题,但是效率实在太低了。在保障线上负载相对稳定的前提下,我们的经验数据是算上增量补偿时间,每 2T 数据迁移完成物理⽅式约 10~20 ⼩时,逻辑⽅式约 30~40 ⼩时。当然分布式集群这些传输都是并⾏的,由于磁盘容量因素,我们数据库通常以 6T 为⼀个并⾏单位,即便如此,整个时间也得以周来计算了。
然后就是扩容成功率的问题,⼤部分情况下⾜够的资源投入和⾜够⻓时间的准备周期让我们扩容相对来说还是靠谱的, 但是近年来我们确实遇到了扩容⽅案⽆法实施的问题。例如有⼀次扩容需求来⾃于业务逻辑调整,数据写入吞吐量剧增,负载和容量都不够需要扩容,但是 MySQL 孱弱的主从复制效率造成了扩容后增量数据补偿永远跟不上数据写入量,甚⾄换了更⾼效的内部逻辑并⾏ CDC ⽅案也跟不上,导致数据源切换⽆法完成的情况。也就是我们即使紧急准备了⾜够的资源打算扩容现有集群,依然可能出现⽤不上的情况。
TiDB server 由于⽆状态,其扩容相对容易,⽽ PD 作为管理服务本⾝⼤概率不需要扩容,因此通常来说的扩容主要是存储服务 TiKV 的扩容。
TiKV 扩容操作仅需要在新增服务器上合理配置并启动服务即可, 新启动的 TiKV 服务会⾃动注册到现有集群的 PD 中, PD 会⾃动做在线的逐步负载均衡, 对业务⽆感知地, 逐步地把⼀部分数据迁移到新的 TiKV 服务中。⽽新投入的 TiKV 资源可以认为在启动的⼀瞬间就已经将资源添加到了现有集群, 不需要再等待漫⻓的, 外部控制的数据重分布过程。
顺便提⼀下, 传统分布式形式中数据库的缩容和扩容基本同样⿇烦, 都需要⾯临数据重分布效率低下的问题。⽽在 TiDB 中缩容 TiKV 节点, 只要不违反相关约束, 安全关闭前 TiKV 会先通知 PD, 这样 PD 可以先把这个 TiKV 上的数据迁移到其他 TiKV 实例, 保证数据有⾜够的副本数后完成⽆感知缩容, 效率和⾃动化程度也较传统模式有巨⼤提升。

schema 变更⽀持能⼒提升
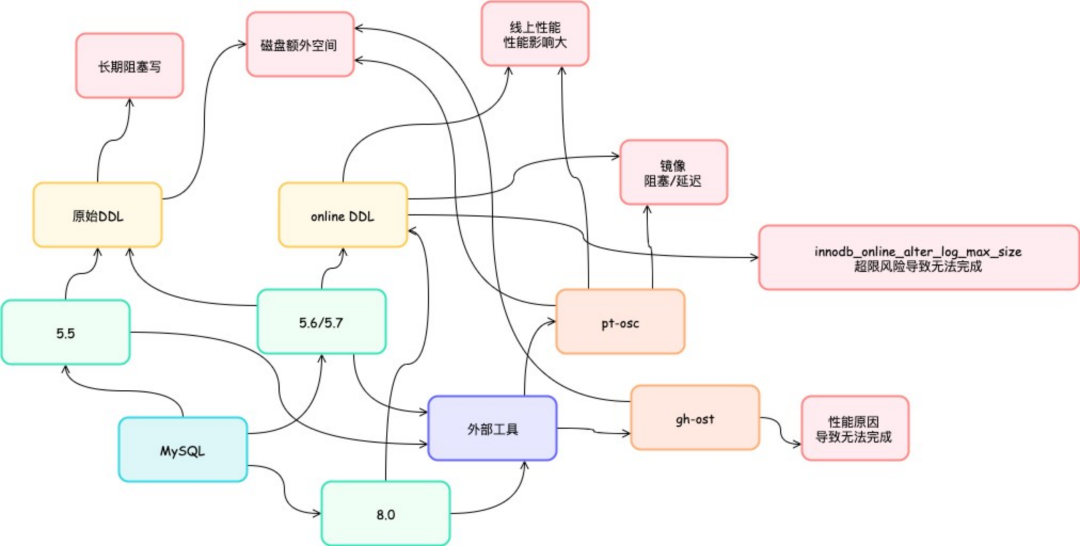
MySQL 的 online DDL 始终让⼈难以完全信任,即使在 online DDL 随着版本完善的过程中,我们也不得不为了规避某些情况坚持使⽤外部变更⼯具。
由于稳定性⻛险, 虽然 online DDL 并不会如传⾔所说锁表时间同增量更新有线性关系, 但是依然有其他⽅⾯的⻛险, 例如我们不太远的过去遇到过 online ddl 中 inplace 算 法 要 求 刷 脏 导 致 写 负 载 型 数 据 库 卡 顿 影 响 稳 定 性 的 ⻛ 险 (想 了 解 的 同 学 可 以 参 考 : http://www.percona.com/community-blog/2020/04/23/unexpected-slow-alter-table-mysql-5-7/)。我们已经在哪种情况使⽤哪种⽅式做了非常多的策略判断了, 多年尝试, 实在难以根据每个特定业务场景做出完全可靠的智能策略,有时候为了避免不必要的⻛险,不得不依然依靠业界⼴泛使⽤,⼴受考验的外部⼯具继续做为统⼀变更⼿段。 由于不确定性⻛险,我们⾃研运维平台⾃动化处理的数据库⼤⼤⼩⼩变更⼀年接近⼗万量级, 如果说⼀种每天都在频繁使⽤的核⼼功能其成功率要依照⼀个默认 128MB,实际不知道多⼤合适的参数的限制,在部分业务场景会经常遇到 RROR 1799 (HY000): Creating index 'idx_xxx' required more than'innodb_online_alter_log_max_size' bytes of modification log……类问题,不但失败还要浪费⼤量资源进⾏回滚的。这个功能是⼀个可靠的功能吗?实际上在业界对 online DDL 的⻓年不敢⼴泛使⽤是 DBA 这边的常态,比如阿⾥云等公有云⼚商和我们是基本相同的做法: 如果你要⼚商提供变更⽀持,则⼀律采⽤外部⼯具,即使在 PolarDB 时代依然如此。
MySQL 内部机制不太靠谱, 外部⼯具也问题多多, 特别是效率问题, 外部⼯具变更需要比变更表更⼤的磁盘剩余空间来完成操作, 因为外部⼯具和原始 DDL 的 copy 模式是⼀样的, 只是不锁 DML⽽已。我们需要完全拷⻉⼀份原表数据应⽤变更, 并且期间还会造成⼤量 binlog。比⽅说, 你想变更⼀个 500G 的表, 我们的经验是数据库本地需要⾄少还有 1T~1。5T 以上空余空间, 我们通常认为才是完全安全的。同时拷⻉数据同上⾯扩容是类似的情况, 需要⼤量时间。实际情况是核⼼业务存量表往往较⼤, 导致你还得先扩容再变更, 这就造成了变更的时间成本和资源成本经常让业务难以接受——翻倍的资源, 以周计算的时间, 变更期间读写分离⼀致性失效, ⾼ 可⽤失效……我们的业务通常望⽽⽣畏,让本该随⼼所欲的数据库变更变成⼀种仅在理论上可能,实际难以实现的需求。
其他的性能冲击,约束键导致的⼀致性⻛险,变更期间⾼可⽤⻛险,DDB 环境下分布式变更的调度和原⼦性控制,极端情况下⼤家都会遇到的 MDL 阻塞,对备份机制的影响 ……各种各样问题不⼀⽽⾜。
由于 kv 模拟⾏表的数据结构,以及 LSM 存储⽆法更新的特点,⼤量数据类型,加减字段,默认值类的操作都可以通过仅元数据变更实现完全 instant,相较 MySQL 8.0 的 instant 范围显然要⼴,效率非常⾼,都是 1s 级别完成变更,且业务感知⼩。
加索引这类必须产⽣新持久化数据,⽆法 instant 的操作,采⽤后台任务,异步线程的机制实现对业务影响相对⼩。⽽且 ADD INDEX 时 tidb 有明确参数记录⽬前索引 创建的进度和速度,能够较好安排调度。
上述两者都比 MySQL copy 或外部⼯具模式显然节省空间。⽽且 TiDB 本⾝扩容就要比 MySQL 中间件⽅式容易的多,变更的效率和可⾏性都将巨⼤提升。
更不会有主从问题带来的⼀系列延伸问题。
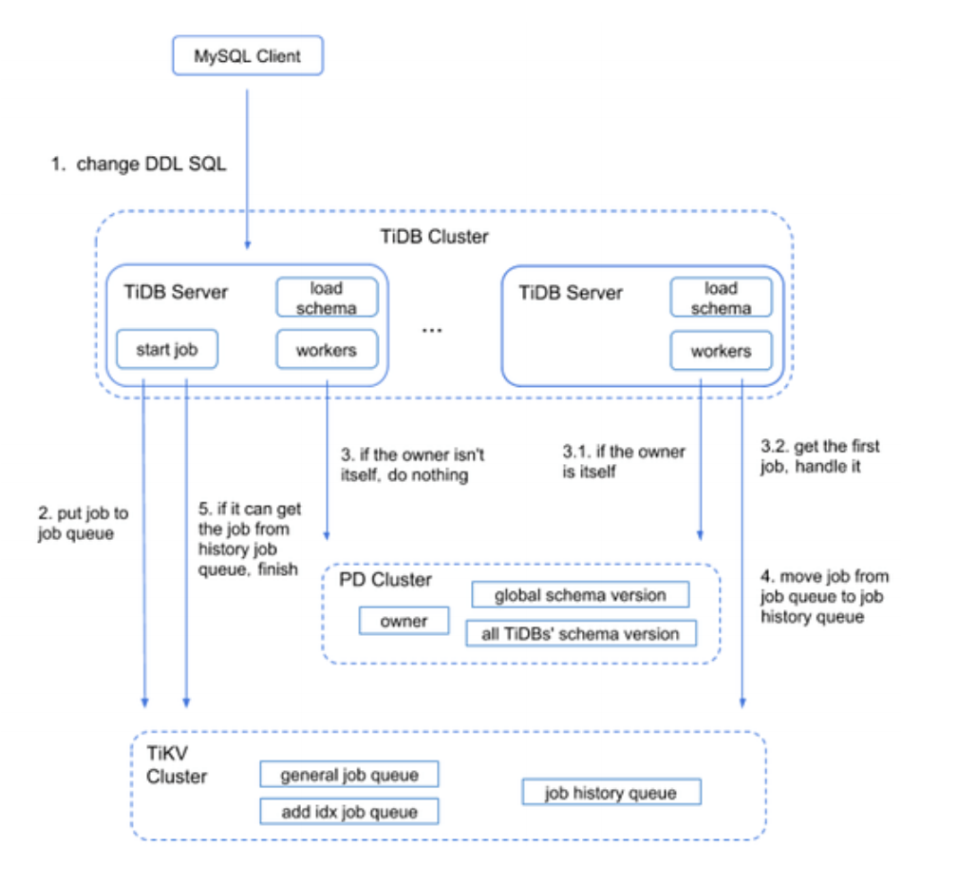
由于 schema version 的变化,执⾏的 DML 语句中涉及的表和集群中正在执⾏的 DDL 的表有相同的,那么这个 DML 语句就报错Information schema is changed,⼀次性,但是需要业务使⽤连接池连接数据库,并且业务端有重试机制避免事务完全失败。
ADD INDEX 操作,根据压测,⽬标列被频繁读写,特别是写多时对性能影响较⼤(即 对业务原有字段加索引时可能会对性能有较⼤影响),QPS/TPS 极端情况下下降 23% 左右,这个其实和 pt-osc 近似了。
⾼可⽤可靠性与效率显著提升
主从⼀致性虽然可以做到相对安全,但是下限非常低,需要许多相关参数和机制配合,例如多种 log 持久化,半同步,复制信息表记录,半同步 ack 模式,non-loss 等……⼀项问题都可能导致主从不⼀致,进⽽影响可靠性。
不⽤ MGR 则集群没有内部协调机制,切换需要外界参与,⽽不能向 ZK,redis cluster ⼀样集群内部完成,这就导致了切换成功率,资源漂移可⾏性,以及如何防⽌极端 情况脑裂双写⽅⾯⼤量的坑。并不是不能做,但是要做到完全靠谱并不容易,这块我之前的⽂章有非常详细机制原理的介绍,如感兴趣请参考。
⽤了 MGR,虽然集群内部角⾊和⾃治切换问题得到了解决,但访问模式官⽅⼀直没有给出非常好的解决思路,⽆论是堪比 sidecar 的 proxy 模式还是⾃⼰改客户端,或者像过去⼀样外部控制资源漂移,都没有很好地解决客户端切换的问题。这块MySQL一直没有和 Redis 或 MongoDB 学习,让人比较郁闷。
外部切换还存在效率问题,也就是切换对客户端恢复服务的时间间隔。有可能是域名切换,客户端缓存导致的问题,也可能是 DDB 这⾥元数据更新串⾏化导致的。特别是⽹易内部 DDB ⼴泛使⽤的 DDB 模式下,由于通过更新路由配置中⼼实现,存在通知客户端⽹络超时和配置中⼼更新只能串⾏两⽅⾯的痛点,导致硬件故障造成的最基本切换场景所需的时间只能保证在 1 分钟级别,5 分钟以内,这就是切换效率的问题了。
最⼤的痛点,即便是 MGR,MySQL binlog 复制是⾼可⽤功能上⽆法回避的梦魇。这块接下来要单独讲。
相对 Oracle 的数据⻚逻辑复制,MySQL 的 binlog 逻辑复制性能简直让⼈⽆法忍受。即便是并⾏复制情况下,根据业务特征,⼤部分情况下,⽆论哪种并⾏模式都⽆法让复制效率实现质变,为了提高效率我们不得不折腾日志持久化,组提交等周边性能要素,甚至造成一些持久化风险。通常我们认为在 CPU,IO 和⽹络都没有瓶颈的情况下,单组 MySQL 实例⾄多也就只能保证简单更新 3000~5000 tps 的复制效率,随着逻辑复杂,部分业务可能超过 2000 tps 就可能产⽣延迟,如果在所有安全措施特别是从库⽇志持久化相关全部严格要求下,性能可能更糟……复制延迟意味着⾼可⽤⾃动切换失效——虽然⽇志到了从库,但是数据尚未被更新,不能让业务切换后读写延迟的数据。
线上⾼负载可能导致复制延迟,例如我们⼀些电商类的活动⾼峰期间,订单等数据的写入⾼峰造成延迟,再最关键的时候数据库⾼可⽤实际上是没有保护的。
变更可能造成延迟,⽆论是 online DDL 还是外部⼯具变更,都会随着变更对象规模变化,造成不可控的延迟,严重的可能以天计算,在变更期间⽤于读写分离分流负载的从库⽆法读,同时主库缺乏⾼可⽤保护,挂了就挂了……⼤家知道真相是不是会出⼀⾝冷汗?
MySQL 解决延迟我们认为唯⼀可⾏的办法就是实例级别的⽔平拆分,每个实例来撑尽可能⼩的 tps 负载,⼀种非常另类的并⾏化。但是这并不是⼀种非常可⾏的模式,例如 DDB 为代表的分布式中间件场景下,⼀个数据库从 64 分片拆到了 640 分片,每个客户端连接对象,分布式事务损耗,集群变更和管控难度都会不断正在,⽽且也⽆法保证真的能彻底解决延迟——比如问题是热点造成,如果业务热点写集中在⼀个分片呢?
⼀致性下限就非常⾼,raft 机制保证数据副本可靠,想要造成不⼀致的可能反⽽困难。
TiKV raft group ⾃治选举,⽆状态的 TiDB server 层⾃动更新路由,⾃治切换和业务连接漂移都不再是难事。
切换效率也非常好,虽然每个 group 都要选举,但是⾼度并⾏化,稳定的 10s 数量级内完成。
raft group 级别⾼度并⾏的复制效率,我们做过相关压测,写压⼒在 MySQL 等量集群延迟⽔位 10~20 倍以上的情况下依然没有相关⻛险。
存储成本有优势
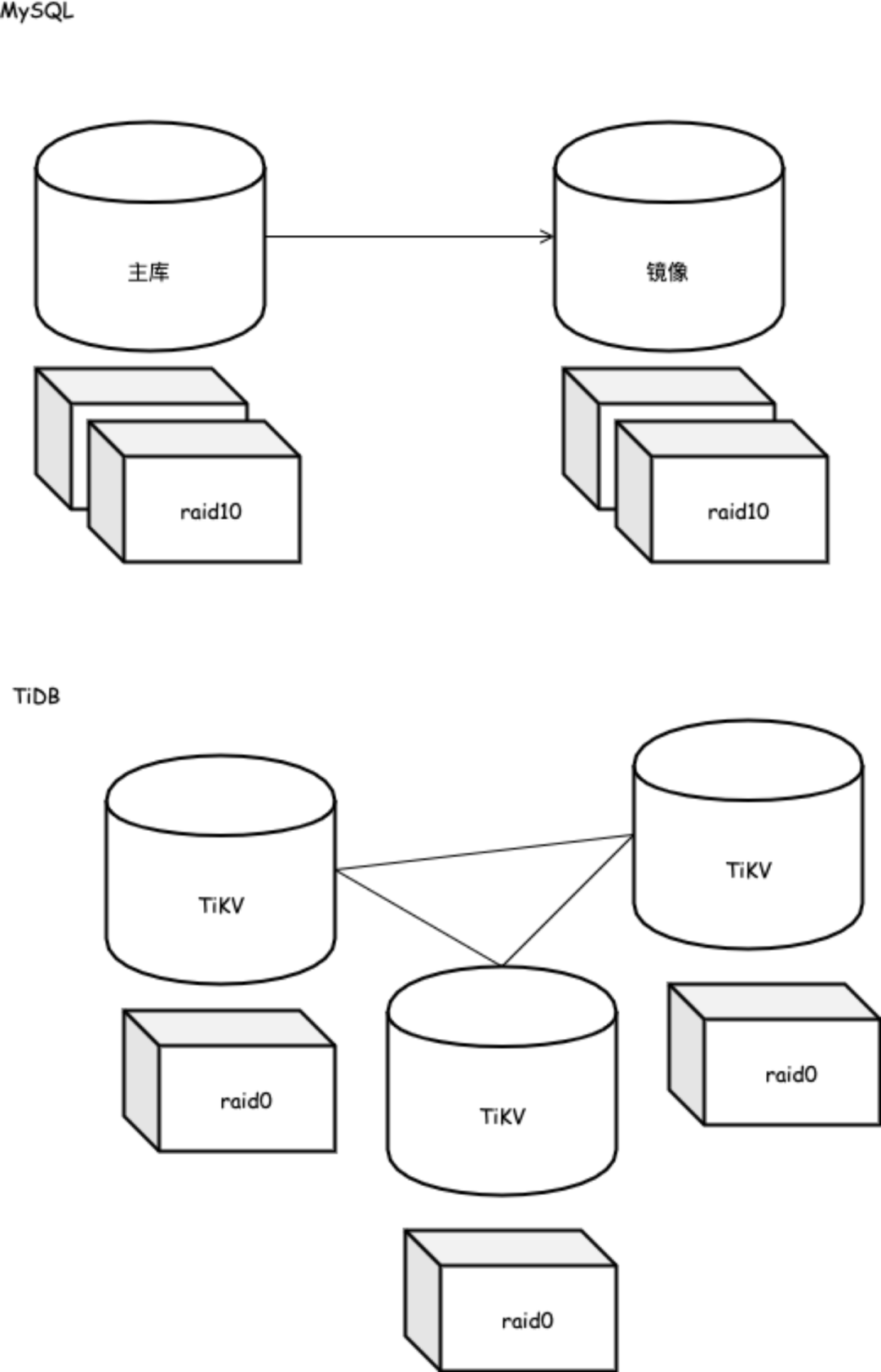

68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441这种类似的随机字符数据 innodb 114G,⽽ TiDB 102G。
HTAP 创新模式
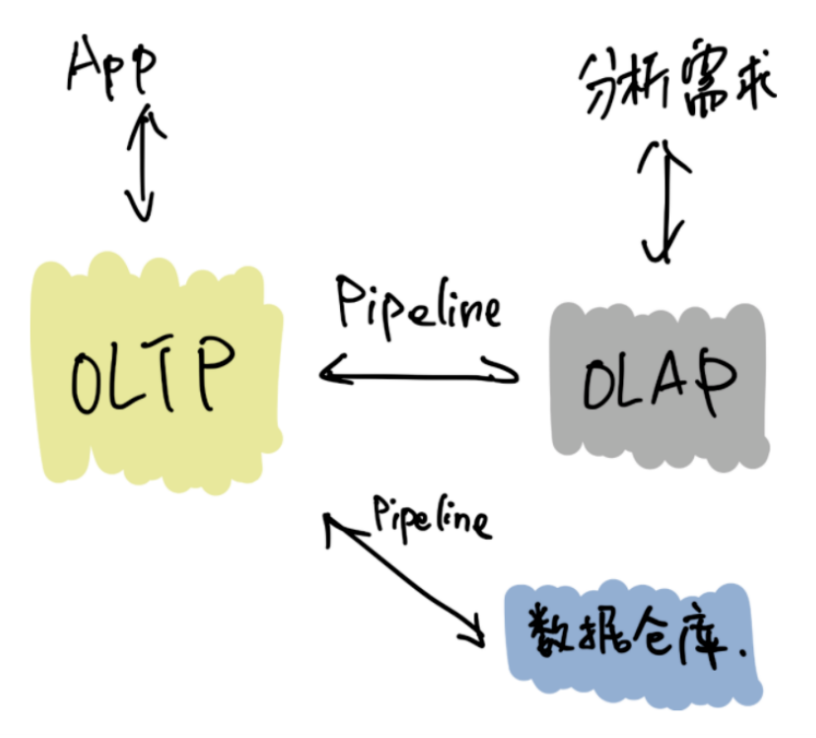
OLTP 部分主要就是 MySQL 及其分布式中间件。
pipline 环节通常也可能是有逻辑过程的 ETL 环节,技术栈可能有定期批量的 sqoop 或 datax ⽅式,实时的 CDC(内部是 NDC)方式,处理过程中为了进⾏清洗和逻辑过滤等需求,还得⽤上 kafka 等队列和业务代码。
OLAP 光处理 ad-hoc ⽅⾯⽬前我们就有 Oracle,greenplum,clickhouse,kudu+impala,presto 这⼀堆技术栈;其他 SQL 引擎如 doris,keylin,druid,hive 都有应⽤; 如果流式需要还有补上消息队列,flink,spark 等; 离线任务侧 yarn,spark……

ETL 过程时效性与数据⼀致性。
逻辑上的变更往往也是难点,⽆论是服务架构,存储⽅式,或是最上游表结构变更,都需要链路上⼤量改动⽀持。
服务技术栈特征是典型的多、专、深,依赖⼤量富有经验的研发和运维投入。
投入资源较⾼,中间过程和存储都是如此,如果需求需要多种技术栈才能满⾜要求,则投入成倍增⻓。
架构和团队复杂化带来的⼀些效率问题。


这⼀架构有⼀些显著的优势:
架构简单紧凑,管理和实施⽅案非常完善,且 TiFlash 功能的启⽤很灵活,业务任何阶段都可以调整,任何线上表可以不开启节约成本,可以随时开启⽀持新增分析需求。
集群实施成本也从 HDFS 级别缩减到了正常数据库级别,你不⽤非得⼀下⼦找⼗⼏台来搞最⼩线上部署,按需投入资源即可。
分析⽤数据从表结构到内容基本同在线表完全⼀致,如果分析需求就是需要基于在线结构,那么直接写 SQL 即可,可以完全省下同步环节相关的资源和维护开销。当然客观来讲,ETL 当然还有 T 的需求。
优化器⽀持,查询到底走哪种形式可以通过⾃定义,也可以交给优化器判断,⼀定程度上把纯粹 SQL 暴露做的更彻底,业务可以更简单地实现需求。
OLAP 部分非常专业的深度优化,例如 TiSpark 可借助类似 clickhouse 的向量化引擎,按照和 TiKV 相同的 coprocessor 协议下推任务到 TiFlash,提升资源利⽤和性能。
扩展与 TiKV ⼀样容易。当然除了⼀⼩部分 (点名 clickhouse) 外的⼤部分分布式⼤数据集群⽅案在这⽅⾯还是可以的。
替代现有相对老旧的 Oracle 和 GreenPlum 技术,主要是 roll up 类可能有些麻烦,但是绝大部分联表类肯定是可以的。GreenPlum 还好,Oracle 以我们现在的硬件条件,扩容都很困难
解决一些不合适的 SQL 直接在 MySQL 或者 DDB 集群里跑的问题,让 OLAP 处理效率合理化,促进更多数据分析能力和需求
如下图,部分替代 Impala on Kudu 和 Presto on HDFS。数据都来自线上导入,就可以尝试所见链路,提供更标准的 SQL 入口应该有的吸引力。

TiDB 内部实践
适⽤场景推荐
有明显淡旺季,周期性,需要⾼峰保障类型的业务
如电商有促销活动的场景,如⼀些业务专⻔⽀持临时活动的模块,如有显著周期性的教育类业务等,可以充分享受灵活扩缩容的优势。
对⾼可⽤和数据⼀致性需求特别强烈的业务
记账对账,消费凭证,外部⽀付回调等,⾼可⽤和⼀致性较⾼⽔平的保障能够帮助业务尽可能提⾼可靠性。 公有云上由于资源可靠性不如内部机房,如果未使⽤ RDS,可以尝试 TiDB。
核⼼模块两地三中⼼⽅案
TiDB 提供⼀种非常有针对性的两地三中⼼实施⽅案, 参考: https://docs.pingcap.com/zh/tidb/stable/three-data-centers-in-two-cities-deployment。意味着同城机房做跨机房的实时⾼可⽤冗余切换,异地机房提供⼀份非常可靠的最终数据冗余兜底。这⼀场景可以活⽤于重要性⾼的系统元数据,比如私有云服务元数据,像内部对象存储元数据这块再合适不过了,极⼤规模的关键数据,还能充分利⽤快速⽔平扩展的能⼒。
对 HTAP 有需求的业务
前⾯提过,如果对任何线上数据有分析查询需求,完全可以尝试不再使⽤传统导数据流程,使⽤ TiDB 单系统内搞定。
计划使⽤ MySQL/DDB, 但也对 TiDB 非常感兴趣
确实遇到存量⼤变更扩容难痛点
单纯想尝鲜⼀下
想要降低存储和运维成本的
想要学习分享新技术的
技术迁移和配套⽀持⽅案
使⽤ TiDB 与其他原有数据库的区别:
业务使⽤ TiDB 主要考虑 SQL 兼容和客户端连接⽅案。
如果是⾃研系统,业务在⽹易内部习惯于使⽤ MySQL 或公私有云的 RDS,⽽非使⽤ DDB,那么 TiDB 使⽤上和过去项⽬没有任何差异,使⽤普通驱动和连接池,更新数据库地址即可。以我的经验中,TiDB 不⽀持的 SQL 功能我们正常研发也基本不会⽤到。
如果要作为其他开源系统的底层元数据存储,可能要考虑下 SQL 兼容性,因为业界使⽤ SQL 的复杂程度有较⼤区别,我们⻅过⼀些国外开源项⽬ SQL 使⽤深度比较复杂的情况。
如果过去习惯使⽤ DDB,是 DBI 也就是特有驱动模式的,需要更换为 jdbc 驱动,并增加连接池,因为 DBI 客户端是内置连接池,jdbc 没有。
替换 DDB 的 SQL ⽅⾯⼤致没有问题,TiDB ⽀持是 DDB 的⽗集。需要注意的主要是 DDB ⼀些老式的唯⼀ ID 分配模式,要替换为 MySQL 兼容类型,例如隐式分配等。
如果过去习惯使⽤ QS 代理⽅⾯模式连接 DDB, 使⽤了 LBD 的要去掉 LBD, 改成正常 jdbc 连接⽅式即可。过去使⽤ QS 但未使⽤ LBD 模式 (比如 NLB 模式) 的不需要做任何修改。
TiDB server 分布式集群⼊⼝访问
static final Srting DB_URL = "jdbc:mysql:loadbalance://10.170.161.65:4121,10.200.166.102:4121/zane?useSSL=false&failOverReadOnlly=false";
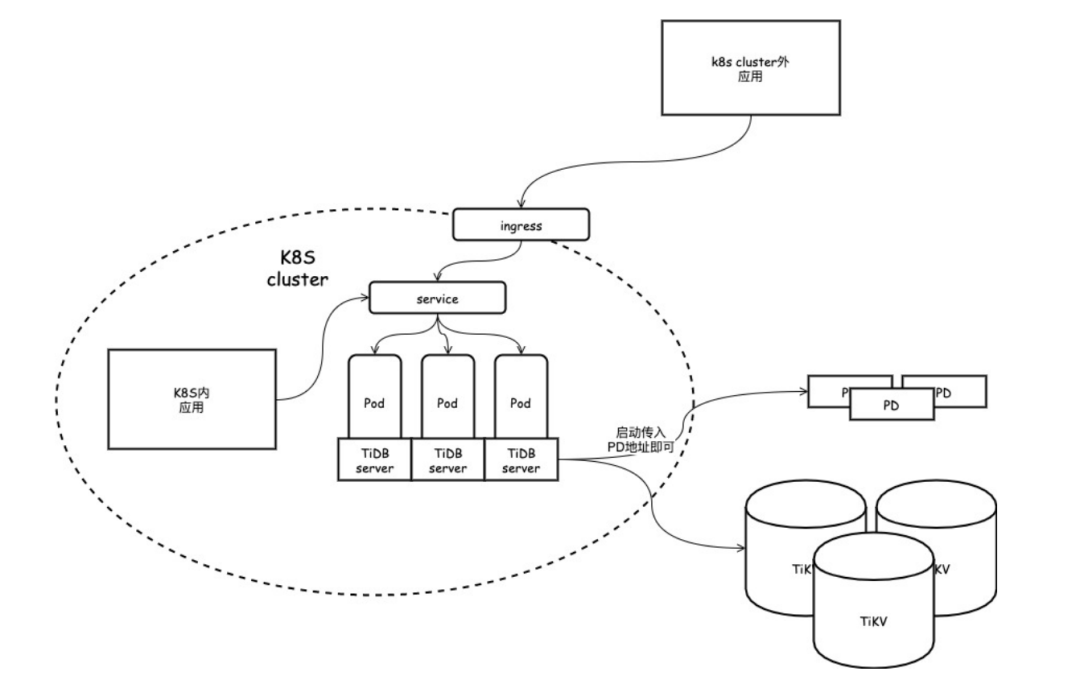
监控与其他运维⽀持


现有业务迁移⾄ TiDB ⽅案
我们肯定不希望采⽤⻓期停服(⾄少停写)的迁移⽅案, 最好数据能实时同步
并且肯定要考虑可随时回滚应⽤以起到回滚数据库的⽬的,因此要保证切换到 TiDB 后的增量数据还得实时回流原数据库集群,实现随时回滚切换回数据源的⽬标。
要有⼀定的灰度发布空间,以验证业务对 TiDB 的连接和使⽤是否可⾏。
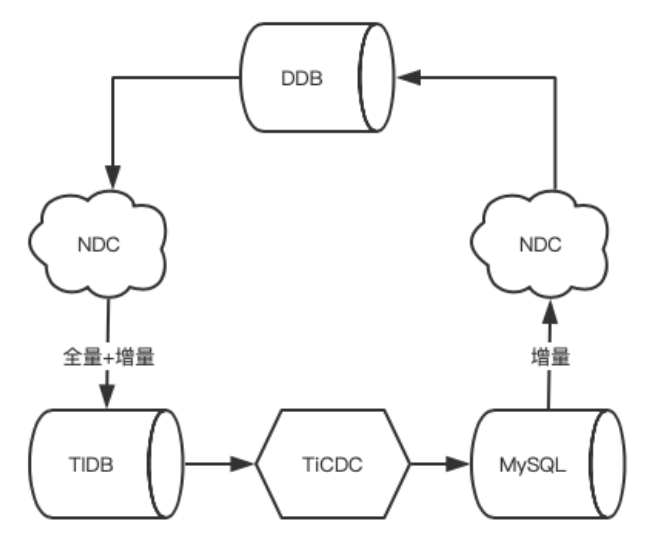
NDC 是⽹易内部⾃研的多数据源迁移和 CDC 平台,可以类比 xdata+canal 的平台化产品
⽬前两个数据源双向同步核⼼问题是没有冲突解决和循环复制解决机制,因此⽆法实现全⾯的双写,应当保持单数据源单写,这样⽅案就是安全的。也是业务迁移步 骤最关键考虑点。
⾸先准备好 DDB->TiDB 的实时同步,直到数据⼀直追上。⾄此并不开启 TiDB->DDB 的反向链路。
如果可能,业务灰度发布只读业务⾄ TiDB,验证服务可⽤性。
正式发布切换在低峰期,业务 DDB 集群禁写,同时暂停 DDB->TiDB 链路,开启 TiDB->DDB 反向链路,业务发布 TiDB 数据源版本。服务不可写时间仅发布期间。
如果上⼀步顺利,则线上回归应⽤后迁移基本成功。
如果切换数据源后发现任何问题,确定要回滚应⽤和数据源解决,由于反向链路保证 DDB 同 TiDB 数据⼀致,因此 TiDB 禁写,DDB 开写,应⽤回滚即可。

近期 TiDB 相关业务应⽤情况简介
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/


![百炼成丹EasyNegative, (worst quality, low quality:1.4), [:(badhandv4:1.5):27],](https://imgs.knowsafe.com:8087/img/aideep/2023/8/26/9d72c81e2d4fe13031528e1d06af96e5.webp?w=250)



 PingCAP
PingCAP
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 劳动是一切幸福的源泉 4917535
- 2 青岛一景区爆满 回头就脸贴脸 4919676
- 3 爸爸为女儿在回家路旁种满鲜花 4834014
- 4 寻找劳动的色彩 献给忙碌的你 4794630
- 5 家长占用医院雾化机让孩子写作业 4672084
- 6 如家酒店被曝花洒现粪便状异物 4531223
- 7 大唐不夜城丢刀侍卫演我五一加班 4483183
- 8 内蒙古1.2万切糕事件反转 4317764
- 9 江苏疾控辟谣新能源车辐射致癌 4230974
- 10 自律儿子不爱学习但每天6点做饭 4179102