大数据浪潮下,诸葛io平台的技术演化之路
本文作者主要以诸葛io背后的大数据平台设计为重点展开讲解。
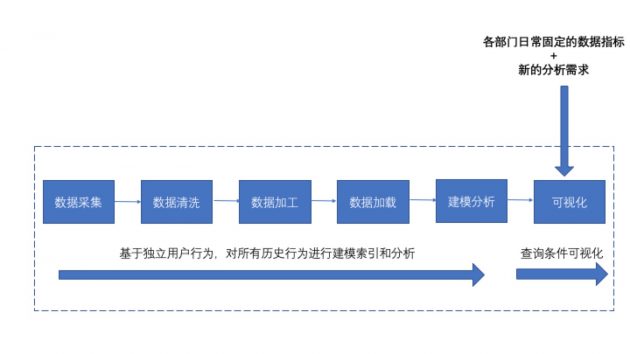
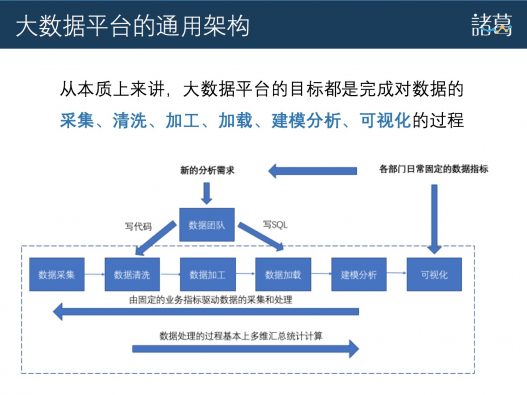 从本质上来讲,大数据平台的目标都是完成对数据的采集、清洗、加工、加载、建模分析,可视化的过程。
从本质上来讲,大数据平台的目标都是完成对数据的采集、清洗、加工、加载、建模分析,可视化的过程。
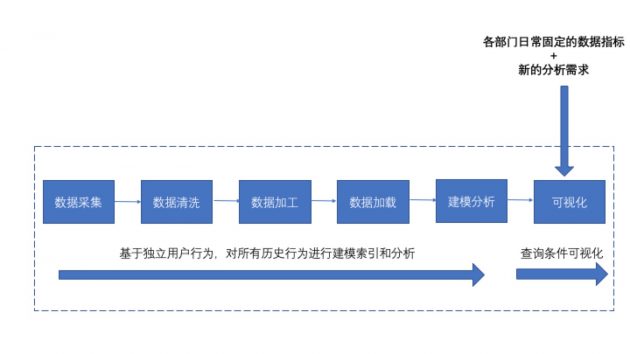 基本上先统一由大数据部门整理输出各部门日常固定的数据指标,然后做个可视化,比如一个简单的页面。
如果有新的分析需求,已经建模好的,那么数据团队就需要根据业务去写SQL然后得到结果,如果没有建模好的,就需要开始采集原始数据,然后重新开始清洗,这样一个过程,往往都比较反复耗时,分析效率很低。主要原因是,这样一种分析流程,是由固定的业务指标驱动数据的采集和处理,然后数据处理的过程基本上都是多维汇总的统计和计算。
所以也就造成了问题:各个业务部门的分析需求需要依赖数据团队专业的数据分析能力进行问题建模,并且依赖他们SQL语言或者代码能力完成分析目标。但数据部门往往也有核心的分析需求和任务,所以公司变大过程中很多问题变得很低效。
基本上先统一由大数据部门整理输出各部门日常固定的数据指标,然后做个可视化,比如一个简单的页面。
如果有新的分析需求,已经建模好的,那么数据团队就需要根据业务去写SQL然后得到结果,如果没有建模好的,就需要开始采集原始数据,然后重新开始清洗,这样一个过程,往往都比较反复耗时,分析效率很低。主要原因是,这样一种分析流程,是由固定的业务指标驱动数据的采集和处理,然后数据处理的过程基本上都是多维汇总的统计和计算。
所以也就造成了问题:各个业务部门的分析需求需要依赖数据团队专业的数据分析能力进行问题建模,并且依赖他们SQL语言或者代码能力完成分析目标。但数据部门往往也有核心的分析需求和任务,所以公司变大过程中很多问题变得很低效。
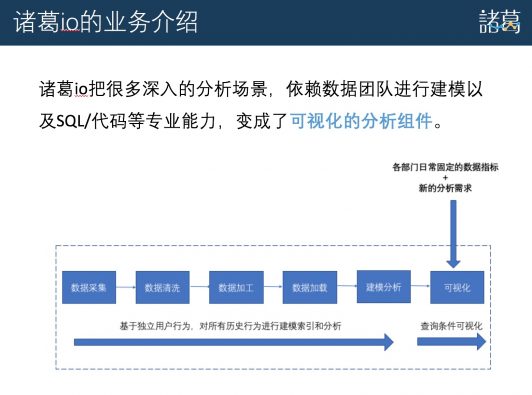 诸葛io的分析能力远远大于目前大多数的统计平台,我们把很多深入的分析场景,依赖数据团队进行建模以及SQL/代码等专业能力,变成了可视化的分析组件。这样极大的提高了企业的数据分析效率,并且我们还有专业的数据分析看板,辅助企业梳理了解分析需求和目标。
诸葛io的亮点如下:
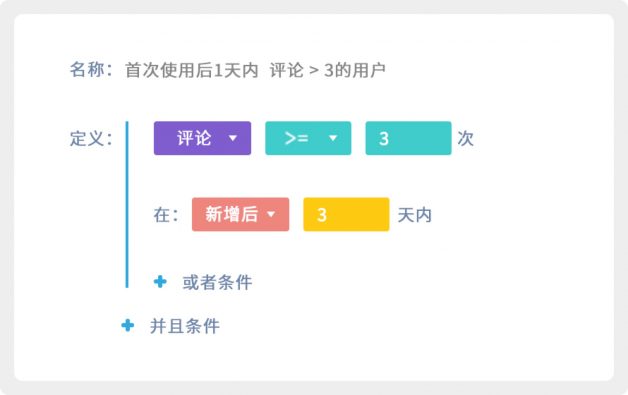
1. 在线实时多维查询,用交互式组件替代SQL和代码。例如以前需要SQL完成的查询,现在只需要如下:
诸葛io的分析能力远远大于目前大多数的统计平台,我们把很多深入的分析场景,依赖数据团队进行建模以及SQL/代码等专业能力,变成了可视化的分析组件。这样极大的提高了企业的数据分析效率,并且我们还有专业的数据分析看板,辅助企业梳理了解分析需求和目标。
诸葛io的亮点如下:
1. 在线实时多维查询,用交互式组件替代SQL和代码。例如以前需要SQL完成的查询,现在只需要如下:
 2. 丰富的分析组件,支持市场/产品/运营部门的大多数场景分析;
2. 丰富的分析组件,支持市场/产品/运营部门的大多数场景分析;
 除此之外,细致入微的产品设计,贯穿分析过程,例如:
除此之外,细致入微的产品设计,贯穿分析过程,例如:
 我们在建模时非常抽象,并且基于独立用户跟踪了整个业务的流程,所以不只是指标任意的配置可视化,很多以前依赖于SQL和清洗代码的逻辑,也变成了交互式的查询组件,所以能提高效率,那我们是怎么做到的呢?先来看看我们整体的架构:
我们在建模时非常抽象,并且基于独立用户跟踪了整个业务的流程,所以不只是指标任意的配置可视化,很多以前依赖于SQL和清洗代码的逻辑,也变成了交互式的查询组件,所以能提高效率,那我们是怎么做到的呢?先来看看我们整体的架构: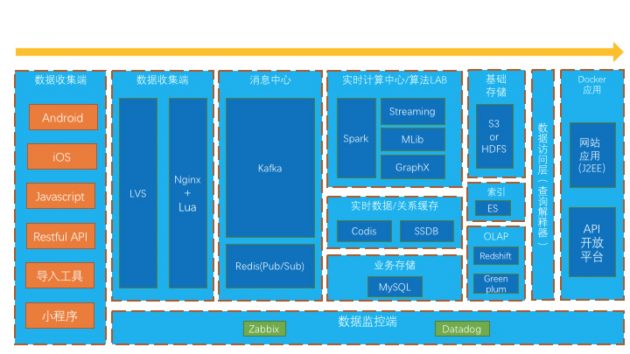 首先看看数据采集端,我们提供丰富的接口和SDK,能够采集到企业各个有用户行为数据的地方,目前来讲,主要分为以下:
首先看看数据采集端,我们提供丰富的接口和SDK,能够采集到企业各个有用户行为数据的地方,目前来讲,主要分为以下:
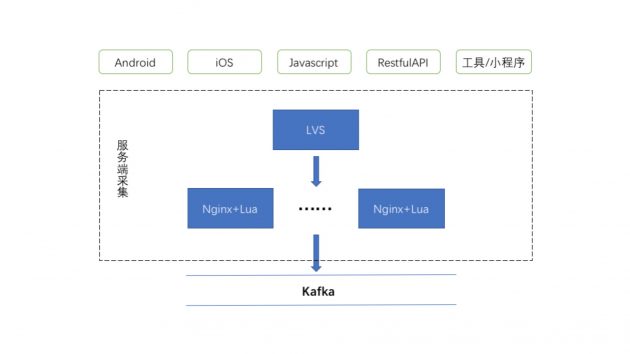 上图是我们的数据收集架构: 核心就是LVS+Nginx+Lua,我们没有用比较重的后端语言来采集,而是选择了比较轻的Lua脚本语言,在nginx中集成就能完成高并发的复杂,LVS做解析服务器的负载均衡,后面是多个Nginx,然后Nginx本身就是高性能高并发服务器,所以并发的承载能力非常强。
诸葛io采用的是HTTPS加密传输,以及支持HTTP2协议:
上图是我们的数据收集架构: 核心就是LVS+Nginx+Lua,我们没有用比较重的后端语言来采集,而是选择了比较轻的Lua脚本语言,在nginx中集成就能完成高并发的复杂,LVS做解析服务器的负载均衡,后面是多个Nginx,然后Nginx本身就是高性能高并发服务器,所以并发的承载能力非常强。
诸葛io采用的是HTTPS加密传输,以及支持HTTP2协议:
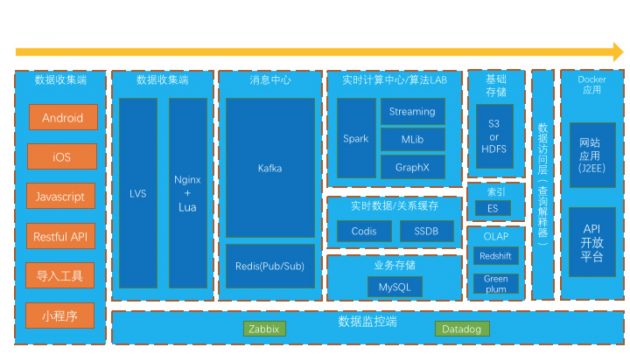 可以看到有消息中心,诸葛io的消息中心是以Kafka为中心进行设计的。
消息中心主要处理包含以下业务消息的汇集和分发:
可以看到有消息中心,诸葛io的消息中心是以Kafka为中心进行设计的。
消息中心主要处理包含以下业务消息的汇集和分发:
从本质上来讲,大数据平台的目标都是完成对数据的采集、清洗、加工、加载、建模分析,可视化的过程。
一、大数据平台的通用架构
1. 数据采集 采集是指集中企业待分析的原始数据的过程,例如可能是包含但不限于以下:1. 企业服务器的日志; 2. 企业各种信息系统的数据(CRM/ERP/数据库); 3. 企业的网站/App/小程序等客户端的用户行为记录; 4. 使用的第三方系统(客服、IM、HR)提供的API;采集的方式基本上分为两种: PUSH模式:企业的数据一般来讲都是散落在很多地方,各种系统或者各种服务器,所以有一个数据采集中心,然后在各个数据产生的位置都有一个agent(可以认为是采集程序)然后朝数据采集中心发送数据的过程就是PUSH,比如在App或者网站植入了SDK,定期发送采集到的用户行为数据到服务端的过程就是PUSH模式; PULL模式:企业有数据采集中心,从采集中心去访问获取各个数据产生点的数据,这个过程就是PULL,比如从企业的数据中心去调用第三方系统的API获取数据,就是PULL模式。 2. 数据的清洗 数据清洗的过程是指对数据进行一些处理,过滤无用的信息,规范得到我们能用到的数据。包括但不限于以下情况:
1. 过滤SPAM垃圾数据,例如被攻击/造假/BUG产生的大量数据; 2. 抽取有用字段,例如上传的数据包含的信息很多,我们只用到一小部分; 3. 原始数据有很多格式不规范,要统一格式;3. 数据的加工 数据加工是指清洗后的数据,还需要补充一些信息,可能是通过数据库查询出来的,也可能是通过计算规则计算出来的,或者算法技术加工出来的新字段。 例如,数据里面有个ip地址,需要计算出用户的地理位置,那么地理位置就是加工出来的字段。一般来讲,对于大多数大数据分析平台而言,加工是很重要的过程,基本上最后可用来进行分析的数据,要通过这一步充分完成加工计算。 4. 数据加载 数据加载是指把加工后的数据加载到合适的存储,可能是Hadoop集群的HDFS上,也可能是某个数据库,有可能是文件等等其他存储类型。 5. 建模分析 建模分析是指在查询前需要把数据进行处理,以优化查询,例如以下:
1. 数据仓库建好了仓库模型,要把数据加载到数据仓库中; 2. 需要做数据索引,把数据进行索引优化;数据模型很重要,是整个数据处理分析的核心之一。每个企业都有自己的核心业务,以及核心目标,并且也有各自的数据源以及数据类型,所以也就意味着每一家企业的数据模型多少都会有些差异,也就是最个性化的一个地方,数据仓库就是这个数据模型的载体,一般来讲数据就是数据库技术,常见数据库之外,还有Infobright,Greenplum,Vertica,也有基于Hadoop技术的,用HDFS作为基础的存储,然后使用的查询引擎,包括Imapla,Presto,SparkSQL等等。 通常而言,数据团队要进行复杂的查询和分析,都是在此基础之上,通过SQL语言或者代码查询来实现的。 6. 可视化 可视化是最终分析结果要展示的过程,例如“双十一”酷炫的图表,一般企业都有自己的数据看板等等。 可视化背后主要是执行SQL或者运行代码得到的数据结果,可能是一维,也可能是二维,还有可能是多维,然后选择合适的图表类型进行展示,例如“线状图”、“柱状图”、“饼状图”、“雷达图”、“中国地图”等等。 刚刚讲的主要是通用的大数据平台整个数据处理的方式,不知道是否讲的通俗易懂,接下来我就从诸葛io与通用的数据平台的差异入手,然后带入我们的技术设计。 首先,诸葛io的整套技术能够做到的是,对企业分析流程的效率提升。 大多数企业的分析现状:自建或者第三方统计平台(百度统计/友盟/Talkingdata)+ 数据BI团队(早期团队人数很少,甚至是一两个工程师兼任);
自建或者第三方统计平台:大多都是汇总统计指标平台。对通用指标(例如PV、UV、DAU、留存)的计算,对企业设定好的业务行为(打车、订单、参与、金额)等汇总统计人数或者次数,数据平台存储的都是指标的汇总结果。指标的选择和下钻分析都需要数据团队的支撑。 数据BI团队:完成基础数据平台的搭建,并且梳理核心业务分析目标,对基础数据进行采集建模,并完成各个部门的分析需求。所以大家可以看到最开始上面那张图就是大多数企业现在的分析现状:
基本上先统一由大数据部门整理输出各部门日常固定的数据指标,然后做个可视化,比如一个简单的页面。
如果有新的分析需求,已经建模好的,那么数据团队就需要根据业务去写SQL然后得到结果,如果没有建模好的,就需要开始采集原始数据,然后重新开始清洗,这样一个过程,往往都比较反复耗时,分析效率很低。主要原因是,这样一种分析流程,是由固定的业务指标驱动数据的采集和处理,然后数据处理的过程基本上都是多维汇总的统计和计算。
所以也就造成了问题:各个业务部门的分析需求需要依赖数据团队专业的数据分析能力进行问题建模,并且依赖他们SQL语言或者代码能力完成分析目标。但数据部门往往也有核心的分析需求和任务,所以公司变大过程中很多问题变得很低效。
二、诸葛io平台技术的演化之路
诸葛io的整个数据处理也是符合上面的整个流程,我们和其他数据分析平台,尤其是传统数据平台,按照处理过程抽象的差异主要如下:
诸葛io的分析能力远远大于目前大多数的统计平台,我们把很多深入的分析场景,依赖数据团队进行建模以及SQL/代码等专业能力,变成了可视化的分析组件。这样极大的提高了企业的数据分析效率,并且我们还有专业的数据分析看板,辅助企业梳理了解分析需求和目标。
诸葛io的亮点如下:
1. 在线实时多维查询,用交互式组件替代SQL和代码。例如以前需要SQL完成的查询,现在只需要如下:
2. 丰富的分析组件,支持市场/产品/运营部门的大多数场景分析;
- 用户群:根据用户的新增情况,触发行为,用户字段筛选待分析的用户;
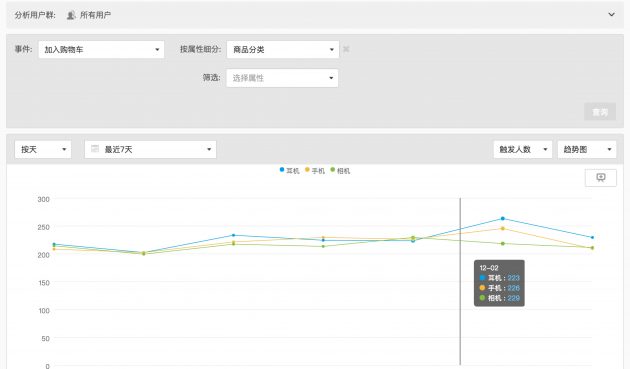
- 事件分析:对某个业务行为的参与情况;
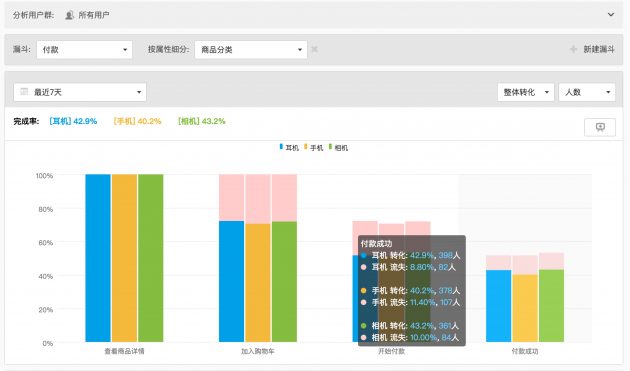
- 漏斗分析:用户的转化情况;
- 用户行为路径:用户的行为路径;
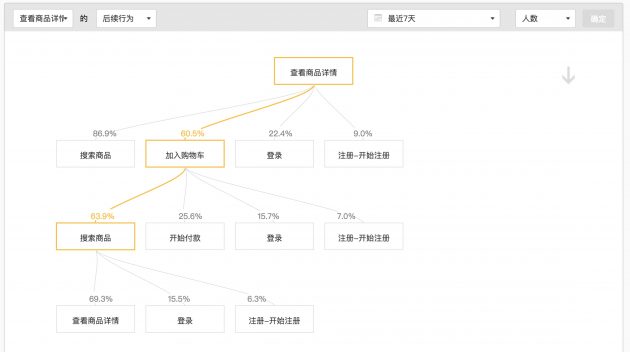
- 自定义留存:某个功能或者某个业务用户的持续参与;

- 分析API和数据API,完全掌控您的数据,基于诸葛io灵活扩展:
除此之外,细致入微的产品设计,贯穿分析过程,例如:
点击数字到用户画像的洞察; 漏斗的无序和有序; 用户群“新增后X天”; 还有更多的场景,可以去感受和体验;这样一来,回到刚刚的图片:
我们在建模时非常抽象,并且基于独立用户跟踪了整个业务的流程,所以不只是指标任意的配置可视化,很多以前依赖于SQL和清洗代码的逻辑,也变成了交互式的查询组件,所以能提高效率,那我们是怎么做到的呢?先来看看我们整体的架构:
首先看看数据采集端,我们提供丰富的接口和SDK,能够采集到企业各个有用户行为数据的地方,目前来讲,主要分为以下:
Android客户端 : Android SDK iOS客户端 : iOS SDK 网站或微站H5 :Javascript SDK 小程序:小程序SDK 日志::服务端Restful接口 CRM数据库 :导入工具也就是采用了“PUSH”模式,各个端采集用户的行为,然后再按照规则发送给我们的数据收集中心,各个端也就写了一些SDK,让开发者调用采集,然后就是我们的数据收集端:
上图是我们的数据收集架构: 核心就是LVS+Nginx+Lua,我们没有用比较重的后端语言来采集,而是选择了比较轻的Lua脚本语言,在nginx中集成就能完成高并发的复杂,LVS做解析服务器的负载均衡,后面是多个Nginx,然后Nginx本身就是高性能高并发服务器,所以并发的承载能力非常强。
诸葛io采用的是HTTPS加密传输,以及支持HTTP2协议:
使用LVS的原因是,虽然Nginx的性能很高,但是在高并发压力情况下,我们能够快速添加Nginx节点,再加上数据采集是异步,所以大流量情况下,LVS+Nginx基本上都能保证不会出现连接等待的情况了。 Lua是一种轻型的脚本语言,直接在nginx配置中嵌入,在很多游戏的服务端架构以及电商秒杀的架构中使用。我们服务端接收到上传数据之后,Lua会进行解析,并且添加上传时一些信息(ip,服务端时间,User-Agent)等等,然后push到Kafka的集群。 我们这套架构也是在诸葛io的日上传数据量逐步上涨过程中,逐步演化出来的。 简单来讲,数据采集具有以下特点:
- 采用HTTPS的原因是,防止数据在传输过程中被抓包截获;
- 采用HTTP2协议,服务端的处理性能能够极大的提升,连接也有优化。
然后就是数据清洗。诸葛io采集到的数据会有以下几个问题需要处理:
- 高并发;
- 高伸缩性性;
- HTTPS安全传输;
- 垃圾数据:乱码或者埋点错误产生的数据;
- 作弊数据:恶意进行注入伪造的数据;
- 淘汰数据 : 已经弃用的SDK版本数据;
加工信息之后,我们还会对数据按照我们的数据模型进行格式转化和预计算处理,得到我们所需要的最优于查询的数据。 关于数据清洗加工部分,我们和其他大数据技术还有一些差异:
- 识别用户和设备的身份关系;
- 加工字段:地理位置、UTM推广信息、设备、系统版本(网站或者微站根据UA);
- 事件行为匹配系统id;
接下来是数据加载。数据加载的过程,就是把我们数据处理后的结果写入存储,这里,诸葛io主要加载的目标位置有以下:
- 独立的用户行为跟踪;
- 基于用户身份的数据整合;
- 精准的用户和设备关系识别;
- 事件的标签化;
1. 原始数据备份:因为诸葛io同时支持SaaS和私有部署,私有部署我们采用的方案会有差异,S3和HDFS都是文件访问,所以业务层基本是一致,S3是因为存储成本低,HDFS是大多数企业的Hadoop平台。加工后的数据同上。 模型仓库,Redshift和Greenplum都是基于PostgreSQL的。我们加上自定义函数,在数据访问层保持一致,然后在建模分析的过程,建模分析的核心是诸葛io的数据模型,也就是我们的数据仓库设计,诸葛io现在的核心数据模型,分为以下主题:2. 加工后的数据:
- AWS S3
- HDFS(私有部署)
3. 模型数据仓库
- AWS S3
- HDFS(私有部署)
- Redshift
- Greenplum(私有部署)
用户:用户的属性信息; 事件(行为):诸葛io的数据模型底层都已经对用户和行为进行建模,我们从上层指标的计算,可以直接下钻用户群体,并且对于用户的行为历史也有完整的还原和实时的洞察。 传统的数据分析平台都以设备进行统计,我们是基于用户的,所以用户和设备的关系我们能精准还原。 诸葛io的数据查询和访问:行为发生平台:平台(设备)的基础信息;
- 事件的属性信息;
- 事件的触发环境;
数据访问层,是诸葛io把基于数据仓库的SQL查询访问抽象了一层服务,分为对内和对外两部分,用以控制对数据访问的统一管理。主要分为两部分:可视化查询在诸葛主要是通过诸葛io的网站进行完成,并且在技术上也是基于数据访问层实现。可视化在诸葛主要分为两部分:
- 对内是通过统一的API服务来进行访问;
- 对外是有Open API的开放平台;
1. 数据指标展现的可视化; 2. 查询操作的可视化;指标展现可视化,包括不限于表格、柱状图、线图、漏斗。回到整个架构上:
可以看到有消息中心,诸葛io的消息中心是以Kafka为中心进行设计的。
消息中心主要处理包含以下业务消息的汇集和分发:
- 各种SDK或者工具上传的数;
- 数据清洗产生的中间的数据;
- 模型结果数据;
- 备份数据;
- 其他流式处理数据;
- 进行元数据统计管理
- 进行备份
- 进入数据仓库模型前的清洗
- 进行实时的统计计算;
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 诸葛io
诸葛io
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 习近平的尊老敬老情 4999139
- 2 12306一种新的存钱方式 4974914
- 3 学生偷外卖被毒死?学校回应 4867363
- 4 “4.0版”消博会上“新”了 4776904
- 5 家暴遭割喉女子父亲发声 4625886
- 6 马斯克为部分遣散费过低道歉 4503941
- 7 外交部回应以色列袭击伊朗境内目标 4488797
- 8 寻味谷雨节气美食 4336034
- 9 广西白沙大道一大楼倒塌系谣言 4213370
- 10 被控受贿1.08亿余元 李东受审 4115260