专家教你利用深度学习检测恶意代码
当前,恶意软件的检测已经成为全社会关注的网络安全焦点,因为许多时候,单个恶意软件就足以导致数百万美元的损失。目前的反病毒和恶意软件检测产品,一般采用的是基于特征的方法,它们借助人工设定的规则集来判断某软件是否属于某种已知的恶意软件类型集合。通常来说,这些规则是具有针对性的,即使新出现的恶意代码使用了跟原来的恶意代码相同的功能,检测软件通常也检测不出来。
所以,这种方法是无法令人满意的,因为大部分情况下二进制文件都是非常独特的,或者说是以前从未见过的,并且,这个世界上每天都有数百万个新的恶意软件样本被发现。所以,我们需要开发一种能够适应日新月异的恶意软件生态系统的检测技术,而机器学习看起来非常有希望满足我们这一需求。事实上,一些初创公司和老牌安全公司早就开始着手构建基于机器学习的防御系统了。为了获得高质量的防御系统,这些公司通常都需要在特征工程和分析方面花费大量财力和精力。然而,如果我们是否能够在无需借助特征工程的情况下构建反病毒系统呢?果真如此的话,我们就能将同一系统部署到不同的操作系统和硬件上检测恶意软件。在我们最近发表的研究论文中,我们的研究成果向这个目标迈出了坚实的一步。
本文引入了一种人工神经网络,经过适当的训练之后,只需要输入Windows的可执行文件的原始字节序列,它就能区分该文件是良性的,还是恶意的。这种方法的优点如下所示:

不需要手工构建特征或编译器方面的知识。这意味着训练好的模型对于恶意软件的变种具有普适性和鲁棒性。 计算的复杂度与序列长度(二进制文件大小)呈线性关系,这意味着推断是快速的,所以能够用于大型的文件。 能够从二进制文件中找出对于取证分析来说非常重要的代码段。 这种方法也适用于新出现的文件格式、编译器和指令集架构:只需提供相应的训练数据即可。我们也希望通过本文向大型机器学习社区表明,从原始字节序列中检测恶意软件不仅具有得天独厚的优势,同时也面临许多前所未有的挑战,所以,这是将是一片肥沃的研究领域。
深度学习在恶意软件检测中所面临的挑战
最近,神经网络在计算机视觉、语音识别和自然语言处理方面取得了一系列的成功,当然,成功的原因是多方面的,其中的一个因素就是神经网络具有从诸如像素或单个文本字符之类的原始数据中学习特征的能力。受到这些成功的启发后,我们开始利用可执行文件的原始字节作为数据来神经网络训练,看看它们能否正确判断给定的文件是否为恶意软件。如果这一方法可行的话,必将极大地简化恶意软件检测工具,提高检测的准确性,并能够找出对于检测恶意软件却非常重要却不很显眼的那些特征。 然而,与其他任务相比,深度学习在恶意软件识别领域还面临着一些挑战和不同之处。对于Microsoft Windows Portable Executable(PE)恶意软件,这些挑战包括:将每个字节作为输入序列中的一个单元来处理的话,就意味着我们需要处理时间步长为200万个左右的序列分类问题。据我们所知,这远远超过了之前所有基于神经网络的序列分类器的输入的长度。 恶意软件中的字节包含的信息具有多态性。上下文中的任何特定字节既可以表示为人类可读的文本,也可以表示为二进制代码或任意对象(如图像等)。此外,其中的某些内容可能是经过加密处理的,这样的话,它们对神经网络来说基本上就是随机的。 在函数级别上面,二进制的内容可以任意重新排列,但由于函数调用和跳转指令的存在,所以这些函数之间必定存在复杂的空间关系。在本文所探讨的范围内,我们对序列分类做出了一定的贡献。音频是与序列长度关系最为紧密的一个领域。诸如WaveNet之类的复杂神经网络,虽然它们使用音频的原始字节作为其输入和目标输出,但是,它的序列分析所面临的时间步也只不过是数以万计而已,与我们的恶意软件检测问题相比要小两个数量级。 对于常用于自然语言处理和音频处理领域的神经网络来说,当我们使用包含数百万的时间步的序列数据作为训练网络参数的输入时,必将面临重大的实际挑战。其中的原因是,各网络层中的激活函数必将占用大量的内存空间。例如,假设我们有一个步长为200万的序列,如果该序列的原始字节用32位浮点类型的300维可训练嵌入层来表示的话,那么仅仅输入数据就需要大约2.4GB的内存。如果它被传递到具有滤波器大小为3和滤波器数量为128的保持长度不变的(length-preserving)一维卷积层的话,则单独这一层的激活函数就又需要1GB的内存。请记住,这里是将单个序列输入到单层的情形,而通常情况下,神经网络训练过程中每次输入的是一个minibatch。 就我们的情形而言,将序列分解成单独处理的子序列是没有用的,因为恶意软件的指标可能是稀疏的,并分布在整个文件中,所以,如果将训练文件的全局标签映射到子序列的话,必将会被由此引入的噪声所淹没。此外,由于训练信号非常弱,所以为判别性特征非常稀疏的输入序列的所有两百万个时间步建立一个唯一的标签就成为一个极具挑战性的机器学习问题。
我们的解决方案
为了解决这个问题,我们尝试了各种不同的神经网络体系结构。同时,为了迎接上面提到的挑战,我们尝试了一些不寻常的架构和参数选择方法。在寻找性能更好的体系结构的时候,我们一方面要增加模型中训练参数的数量,同时还要让激活函数的内存占用量尽量少,所以,这要求我们在两者之间取得平衡,从而确定出合适的最小批量大小,以便不仅让训练时间满足实际要求,同时,还能让训练过程收敛。 在设计网络模型时,我们要努力争取:计算量和内存用量能够根据序列长度而高效地扩展 在检查整个文件的时候能同时考虑到本地和全局上下文 在分析标记为恶意软件的时候能够提供更好的解释能力
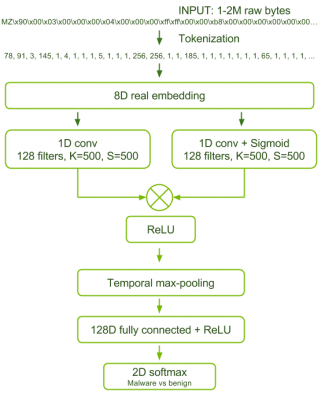
图1 恶意软件检测网络的体系结构
结果发现,表现最好的模型在体系结构方面,不但具有更少的训练参数(134,632),同时还具有更少的网络层数,具体如图1所示。 我们能够通过使用门控卷积体系结构和可训练的输入字节的嵌入向量表示来最大化网络的可训练参数数量来实现了上面的第一个目标。在门控体系结构中,对于每个卷积层,都提供了一个使用sigmoid激活函数的副平行卷积层。然后,将这两个平行层的输出进行逐元素相乘,并将结果传递给非线性的reLU激活单元。这样的话,sigmoid卷积层就会过滤掉reLU卷积层所允许的那些信息,使得该体系结构能够以有效的方式为模型的特征表示增加额外的容量。 我们通过使用更大的步幅和更大的卷积滤波器大小来控制卷积层激活单元所占用的内存单元数量。从表面上看,这些选择似乎会降低模型的准确性,然而我们在实验中发现,更精细的卷积和更小的步幅并没有带来更好的性能。 我们在卷积层后面添加了全局最大池化层,从而实现了第二个目标。对于网络的这项功能,一种解释方法是,门控卷积层能够识别恶意软件的本地指标,对全连接层最大池化处理后,使得系统能够评估整个文件中这些指标的相对强度,从而找出重要的全局组合。 根据针对几种架构的测试结果来看,它们都具有过度拟合的倾向。考虑到必须使用单一损失函数来学习大型输入特征空间的良性/恶意软件分类,这种情形并不奇怪。我们发现惩罚全连接层的隐藏状态激活函数之间的相关性,详细介绍请参考 [Cogswell et al. 2016],是最有效的调整形式。更加有趣的是,我们发现,常用的批正则化操作(batch – normalization)实际上妨碍了模型的收敛和泛化。至于出现这种情况的具体原因,请参阅论文的第5.3节。训练数据和训练方法
对于这个神经网络,我们采用了两个数据集进行训练和验证。我们的第一组数据,即A组,可以从公开的网络上面下载。良性数据是从全新安装的Microsoft Windows系统上面收集来的,其中包含一些常用应用程序;恶意软件取自VirusShare样本库。其中,A组包含43,967个恶意文件和21,854个良性文件。第二组,也就是B组,是由行业防病毒合作伙伴提供的,这些文件都是从现实中的计算机上搜集到的,B组包含400,000个独立的文件,其中良性和恶意文件各占一半。同时,B组还包括一个由74,349个文件组成的测试集,其中4万个文件是恶意的,其余的文件都是良性的。 我们发现,在对A组进行训练的过程中,会产生严重的过拟合现象,导致训练好的模型的功能变成识别某个文件是否“来自微软”,但是无法判断某个文件是否是“良性的”。利用A组数据训练的模型,无法推广到B组数据。但是,我们发现,通过B组数据训练的模型可以顺利推广到A组数据上面。因此,我们通过B组数据来训练模型,然后利用A组和B组数据来测试模型。这样做的好处是,我们的模型可以获得更好的泛化能力,因为这些数据来自不同的源。我们对于模型在A组数据上面的测试性能更感兴趣,毕竟模型是在B组数据上面进行的训练,当然,我们希望模型在两个测试集上具有相似的性能,这样就能表明所学的特征是非常有用的。 另外,在我们的实验后期,我们收到了来自B组同源的更大的训练数据集,其中包含2,011,786个独立的二进制文件和1,011,766个恶意文件。 为了让模型尽快收敛,可以在训练网络的时候增加batch的大小,这个方法非常有效。由于网络激活函数需要占用大量的内存,这就需要使用数据并行的模型训练方式。在我们的试验中,使用的是含有8个GPU的DGX-1系统,当利用含有400,000个样本的B组训练集以数据并行的方式训练这个模型的时候,如果8个GPU上的计算单元和内存“火力全开”的话,完成一轮训练需要大约16.75小时,训练过程共计需要完成10轮。如果使用含有两百万个样本的训练集的话,使用同样的系统,则需要花费一个月的时间。实验结果
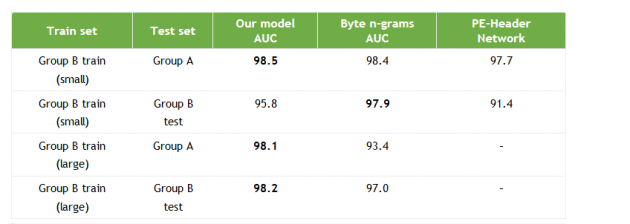
在评估模型性能的时候,最关键的指标是AUC。这是因为对恶意软件进行分类的时候,我们可以通过模型对二进制文件进行排队,实现恶意文件和良性文件的隔离,同时还可以通过人工分析给出优先级评分。较高的AUC分值(接近1)就意味着已经将大多数恶意软件成功地排在了大多数良性文件的前面。所以,取得高分值的AUC是非常重要的,因为恶意软件分析专家通过手工方式分析单个二进制文件所需时间可能会超过10个小时。AUC还有一个好处,就是可以对模型在两个具有不同数量的良性和恶意样本的测试数据集上的性能进行比较。 表1显示了我们的模型与文献中表现最好的模型之间的性能比较。第一个模型使用原始字节n-gram作为逻辑回归模型的输入特征[Raff et al. 2016]。第二个模型将一个浅层的全连接的神经网络用于从文件PE-Header中提取字节n-gram[Raff et al. 2017]。在表1中,我们用粗体来显示最佳结果。
表1:利用小样本(400,000个样本)和大样本(200万个样本)的B组训练集进行训练后,我们的恶意软件检测模型在A组和B组测试集上面的性能表现。
通过上面的数据不难看出,我们的模型在A组上面的表现最佳,在B组上面的表现次之。但是,当使用多达200万个文件的训练集进行训练时,我们发现,我们的模型的性能得到了进一步的提升,在两个测试集上都表现出了最佳的性能,但是基于字节n-gram的模型的性能反而出现了下降。这表明在字节n-gram模型中存在脆弱性和过度拟合的倾向。模型的实用性
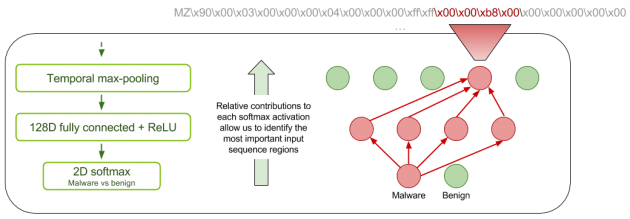
在本文中,我们还提供了在实验中关于模型的平衡测试准确性的报告,也就是说,它们能够区分良性和恶意软件文件,并给予每个文件同等的重要程度。虽然我们的模型在这个指标上面表现不错,但它并不一定代表模型在现实世界中的性能。恶意软件检测系统具有各种不同的使用场景。对于大容量文件分类,吞吐量是最重要的,这意味着对误报的容忍度可能会降低。在其他场景中,误报可能是可以接受的,以获得高灵敏度;换句话说,真正的恶意软件很少被“放过”。 但不论是哪种情况,对于检测的结果,都需要对潜在恶意软件进行某种形式的深入分析,通常由恶意软件分析专家来完成这项分析任务。所以,我们希望自己的神经网络对分类的结果具有一定的可解释性,以节约分析师的精力和时间。本文的思想是受到[Zhou et al. 2016]论文中的类激活映射(CAM)技术的启发而获得灵感的。对于良性和恶意软件中的每一个类别,我们都会为卷积层中最活跃的应用位置上每个过滤器的相对贡献生成一个映射。您可以将其视为找出哪些区域对良性或恶意软件分类贡献最大。我们称之为改进型稀疏-CAM,因为这里使用全局最大池化而不是平均池化技术,所以自然会得到稀疏的激活函数映射。图2为读者详细展示了稀疏-CAM的示意图。
图2 稀疏-CAM示意图
通过阅读已经发表的相关论文,我们发现,对于字节n-gram模型来说,几乎所有的判别性信息都是从可执行文件的头部中取得的。这意味着字节n-gram模型通常不使用文件的实际可执行代码或数据段作为判别性特征。表1中的结果表明,在我们的测试中,可以访问整个可执行文件的模型比仅限于文件头的模型具有更高的分类准确性。 我们的恶意软件分析专家对224个随机选取的二进制文件的稀疏CAM进行分析的结果显示,在我们的模型获取的最重要的特征中,有39-42%的特征位于文件头之外。特别是,我们发现可执行代码和数据中都含有判别性特征。
表2:来自文件各部分的重要特征,这些都是通过稀疏-CAM映射到PE文件输出的非零区域确定出来的。
小结
本文表明,神经网络无需借助昂贵和不可靠的特征工程就能学会如何区分良性和恶意的Windows可执行文件。这样一来,它不仅能够在进行分类时取得较高的AUC得分,还能够避免普通防病毒和恶意软件检测系统所面临的诸多问题。 对程序的字节级的理解,其应用范围非常广泛,而非仅限于恶意软件的分类,其他应用领域还包括静态性能预测和自动代码生成等。但是,要想实现这一目标,需要批判性思考如何减少所需的内存量,以及哪些类型的神经网络架构能够更好地捕捉以二进制形式表示的信息的各种模式。 我们希望这项工作能够鼓励更多的机器学习社区来关注恶意软件检测,因为这一领域面临着许多独特的挑战,例如极长的序列和稀疏的训练信号,所以,对于研究人员来说,这将是一片沃土。众所周知,深度学习已经在图像、信号和自然语言处理方面取得了一些惊人的成功和进步。如果将其扩展到诸如恶意软件检测这样完全不同的领域,可以帮助我们从不同角度更好地理解了这些工具和学习方法,因为有些方法并不是在所有新的数据和问题领域都同样适用,例如batch正则化。同时,这也能够帮助我们进一步了解神经网络的普适性。 与本文相关的论文可以从Arxiv下载,同时还可以从这里聆听我们在AAAI 2018网络安全人工智能研讨会上针对这项工作所做的报告。参考文献 [Cogswell et al. 2016] Reducing Overfitting in Deep Networks by Decorrelating Representations, Cogswell, M.; Ahmed, F.; Girshick, R.; Zitnick, L.; and Batra, D. (ICLR 2016) https://arxiv.org/abs/1511.06068 [Zhou et al. 2016] Learning Deep Features for Discriminative Localization. Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; and Torralba, A. (CVPR 2016) https://arxiv.org/abs/1512.04150 [Raff et al. 2016] An investigation of byte n-gram features for malware classification. Raff, E.; Zak, R.; Cox, R.; Sylvester, J.; Yacci, P.; Ward, R.; Tracy, A.; McLean, M.; and Nicholas, C. Journal of Computer Virology and Hacking Techniques. 2016 [Raff et al. 2017] Learning the PE Header, Malware Detection with Minimal Domain Knowledge, Raff, E.; Sylvester, J.; and Nicholas, C. arXiv:1709.01471, 2017本文翻译自: https://devblogs.nvidia.com/parallelforall/malware-detection-neural-networks/ ,如若转载,请注明原文地址: http://www.4hou.com/web/9136.html
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/




![Luna稻田樱子最爱小椰汁~[馋嘴][馋嘴][爱你]2杭州·杭州水裹·汤泉生活(新天地店) ](https://imgs.knowsafe.com:8087/img/aideep/2022/5/10/0d50d4d33d8e7f2990c6c31919fac755.jpg?w=250)
![郝婧同Micky:愿你出游半生,归来仍是少年。[兔子] ](https://imgs.knowsafe.com:8087/img/aideep/2021/7/14/c4c82d97b38865c304979dfa08fe4e32.jpg?w=250)
 嘶吼
嘶吼
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 钓鱼台漫步和意悠长 4980659
- 2 美国一票否决巴勒斯坦入联申请 4986655
- 3 儿子讲述父亲疑被当猎物枪杀 4856642
- 4 4.0版消博会 外资看中三个“新” 4721735
- 5 小龙虾身价暴跌 4628917
- 6 抗战烈士墓发现年轻女子照片 4582357
- 7 北京一皇家级四合院4.5亿元起拍 4462462
- 8 10岁女孩险被陌生男拐走?官方回应 4361648
- 9 养老保险断缴即清零?不实 4214856
- 10 理想L6售价24.98万起 4185795