程序员必须练就的「性能调优」组合拳【4】,练就哪些技能才胜任架构师?,如何从开发岗转型做架构师?
性能调优系列前序文章索引:
- 程序员必须掌握的性能调优:老兵哥结合个人经历解释了程序员往架构师方向发展时为什么要跨越性能调优这一关,以及介绍了从 X、Y、Z 三个维度优化性能的思路。
- 从 X 维度优化系统的性能:老兵哥分享了从 X 维度优化系统性能的思路,包括让客户端分计算存储任务、优化交互设计等,主要是作为引子拓宽我们性能调优的思路。
- 应用容器 Tomcat 性能调优:老兵哥介绍了从 Y 维度通过优化应用容器 Tomcat 来优化系统性能的方法。
- 开发框架 Spring 性能调优:老兵哥介绍了从 Y 维度通过优化开发框架 Spring 来优化系统性能的方法。
程序员在转型架构师的过程中需要建立流程化、结构化、系统化的思维方式,而性能调优是非常难得的契机,它既给了我们压力,也给了我们动力,跨越它就是突破自己的过程。
- X 维度,即业务维度,技术始终是服务业务的,任何技术问题的原点就是业务需求。在启动技术层面的性能优化之前,我们有必要先审视一下业务流程是否合理,交互设计上有没有可以优化的空间等。
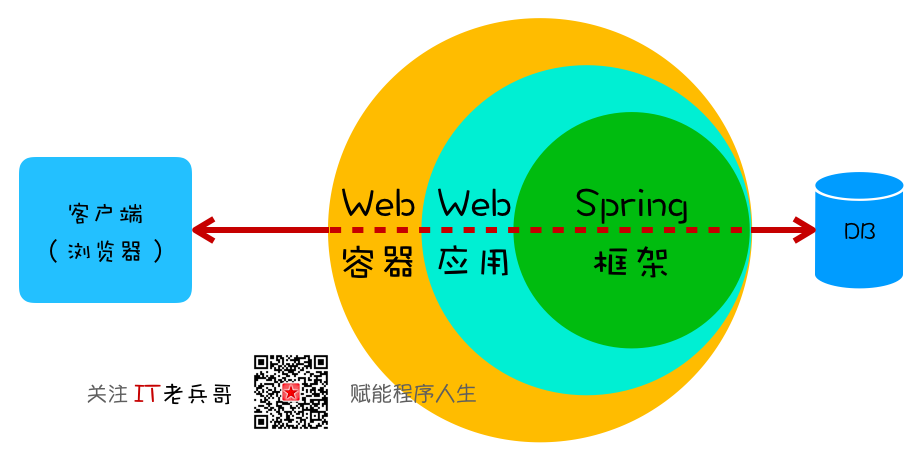
- Y 维度,待业务维度优化完毕,接下来就是审视技术在实现当前业务流程或交互设计的全链路上有没有可优化的地方,即 HTTP 请求处理全流程,从浏览器到应用容器,再到 Spring、Hibernate、数据库等。
- Z 维度,除了沿着 HTTP 请求的横向链路,我们还要审视支持应用系统的纵向技术栈,从上到下包括 JVM、操作系统和硬件等,这是整套应用系统运行的环境,许多性能问题都跟运行环境存在关系。
今天老兵哥将介绍通过优化对象关系映射 ORM 框架(Hibernate)等来优化系统性能的方法。
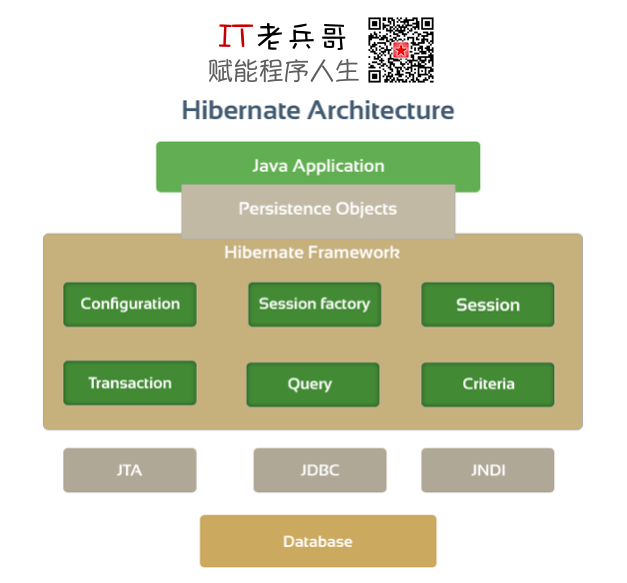
4. ORM 框架 Hibernate
对象-关系映射 ORM(Object/Relation Mapping),是伴随着面向对象软件开发方法的发展而产生的。面向对象的开发方法是当今企业级应用开发环境中的主流方法,关系数据库是企业级应用环境中数据永久存储的主流数据存储系统。对象和关系是业务实体数据的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。
对象-关系映射 ORM 系统通常以中间件的形式存在,借助描述对象到关系数据库数据的映射元数据,将内存中的对象自动持久化到关系数据库中,其本质就是将数据从一种形式转换到另外一种形式。这个转换过程需要额外的开销,自然也就存在许多优化的机会,接下来我们一起来看看如何提升 ORM 框架 Hibernate 的性能。
4.1 批量处理
应用或者 ORM 框架每次执行 SQL 语句都需要跟数据库建立连接,每次建立连接都需要额外开销。如果某个事务内部有循环多次操作数据库的场景,那么将这些操作汇集在一起批量执行,这样就可以降低损耗,具体如下:
- 批量插入
使用这种方法时,首先在 Hibernate 的配置文件 hibernate.cfg.xml 中设置批量尺寸属性 hibernate.jdbc.batch_size ,且最好关闭Hibernate的二级缓存以提高效率。
<hibernate-configuration> <session-factory> <property name="hibernate.jdbc.batch_size">50</property> //设置尺寸 <property name="hibernate.cache.use_second_level_cache">false</property> //关闭缓存 <mapping resource="com/itlaobingge/po/User.hbm.xml" /> </session-factory> </hibernate-configuration>
public class HibernateDemo {
public static void main(String args[]) {
Session session = HibernateSessionFactory.getSession();
Transaction ts = session.beginTransaction();
for (int i = 0; i < 50; i++) {
User user = new User();
user.setPassword(i);
session.save(user);
if (i%50 == 0) {
// 以 50 为一个批次往数据库提交,此值应与配置的批量尺寸一致
session.flush();
// 清空缓存区,释放内存供下批数据使用
session.clear();
}
}
ts.commit();
HibernateSessionFactory.closeSession();
}
}
- 批量更新
为了使 Hibernate 的 HQL 直接支持 update 的批量更新语法,我们需要在 Hibernate 的配置文件 hibernate.cfg.xml 中设置 HQL/SQL 查询翻译器属性 "hibernate.query.factory_class":
<hibernate-configuration> ...... <property name="hibernate.query.factory_class"> org.hibernate.hql.internal.ast.ASTQueryTranslatorFactory </property> <mapping resource="com/itlaobingge/po/User.hbm.xml" /> </session-factory> </hibernate-configuration>
public class HibernateDemo {
public static void main(String args[]) {
Session session = HibernateSessionFactory.getSession();
Transaction ts = session.beginTransaction();
Query query = session.createQuery("update User set password='123456'");
query.executeUpdate();
ts.commit();
HibernateSessionFactory.closeSession();
}
}
- 批量删除
为了使 Hibernate 的 HQL 直接支持 delete 的批量更新语法,我们需要在 Hibernate 的配置文件 hibernate.cfg.xml 中设置 HQL/SQL 查询翻译器属性 "hibernate.query.factory_class":
<hibernate-configuration> ...... <property name="hibernate.query.factory_class"> org.hibernate.hql.internal.ast.ASTQueryTranslatorFactory </property> <mapping resource="com/itlaobingge/po/User.hbm.xml" /> </session-factory> </hibernate-configuration>
public class HibernateDemo {
public static void main(String args[]) {
Session session = HibernateSessionFactory.getSession();
Transaction ts = session.beginTransaction();
Query query=session.createQuery("delete User where id < 123");
query.executeUpdate();
ts.commit();
HibernateSessionFactory.closeSession();
}
}
4.2 抓取策略
抓取策略是指当应用程序需要在对象关联关系间进行导航时,Hibernate 如何获取关联对象的策略,常见的抓取策略有如下几种:
- 链接抓取(Join Fetching):通过在 select 语句中使用 out join 来获取对象的关联实例或者关联集合。
- 查询抓取(Select Fetching):发送另外一条 select 语句抓取当前对象的关联实体或者关联集合。除非我们显示地指定 lazy=”false” 禁止延迟抓取,否则只有当我们真正访问了关联关系时才会执行第二条 select 语句。
- 子查询抓取:另外发送一条 select 语句抓取在前面查询到或抓取到的所有实体对象的关联集合。除非你显式的指定 lazy="false" 禁止延迟抓取,否则只有当你真正访问关联关系的时候,才会执行第二条 select 语句。
- 批量抓取(Batch fetching):对查询抓取的优化方案,通过指定一个主键或外键列表,Hibernate 使用单条 select 语句获取一批对象实例或集合。
Hibernate 会区分下列几种情况:
- 立即抓取(Immediate fetching):当宿主被加载时,关联、集合或属性被立即抓取。
- 延迟集合抓取(Lazy collectionfetching):直到应用程序对集合进行了一次操作时,集合才被抓取。
- Extra-lazy 集合抓取(Extra-lazy collection fetching):对集合类中的每个元素而言,都是直到需要时才去访问数据库。除非绝对必要,Hibernate 不会试图去把整个集合都抓取到内存里来。
- 代理抓取(Proxy fetching):对返回单值的关联而言,当其某个方法被调用,而非对其关键字进行 get 操作时才抓取。
- 非代理抓取(No-proxy fetching):对返回单值的关联而言,当实例变量被访问的时候进行抓取。与上面的代理抓取相比,这种方法没有那么延迟得厉害,就算只访问标识符,也会导致关联抓取,但是更加透明,因为对应用程序来说,不再看到 proxy。这种方法需要在编译期间进行字节码增强操作,因此很少需要用到。
- 属性延迟加载(Lazy-attribute fetching):对属性或返回单值的关联而言,当其实例变量被访问的时候进行抓取。需要编译期字节码强化,因此这一方法很少是必要的。
定制合理的抓取策略对系统的性能提升有很大的帮助。查询抓取在 N+1 查询的情况下是极其脆弱的,因此我们可能会要求在映射文件中定义连接抓取(fetch=”join”),但是在映射文件中定义的抓取策略将会产生以下影响:通过 get() 或者 load() 方法获取数据,只有在关联之间进行导航时,才会隐式的取得数据。
条件查询,使用了 subselect 抓取的 HQL 查询,不管使用哪种抓取策略,定义为非延时的类图会保证装载入内存,这就意味着一条 HQL 查询后紧跟着一系列的查询。通常我们并不使用映射文件进行抓取策略的定制,更多是保持其默认值然后在待定事务中适用 HQL 的左连接对其进行重载。
Hibernate 推荐的做法也是最佳实践:把所有对象关联的抓取都设为 lazy,然后在特定事务中进行重载。这种考虑是基于对象之间的关联关系错综复杂,有时候哪怕我们只是一个简单的查询,也会导致很多关联对象被装载出来,所以在 Hibernate 中,所有对象关联都是 lazy 的。
在 Hibernate 中实施关联抓取,我们可以定义每次抓取数据的数量,批量地将数据载入内存,减少与数据库交互的次数,在应用程序中可以定义默认的关联抓取数量。Hibernate 提供了两种批量抓取方案:
- 类级别的批量查询,如果一个 Session 中需要载入 30 个 User 实例,在 User 中拥有一个类 Class 成员变量 class。如果 lazy=“true”,我们需要遍历整个 user 集合,每一个 user 都需要 getClass(),在默认情况下要执行 30 次查询得到 Class 对象。因此,可以通过在映射文件的 Class 属性设置 batch-size,这样Hibernate 只需要执行两次查询即可:
<class name=”Class” batch-size=”15”>...</class>
- 集合级别的批量查询,如果我们需要遍历 30 个 Class 对象下所拥有 User 对象列表,在 Session 中需要载入 30 个 Class 对象,遍历 Class 集合将会引起 30 次查询,每次查询都会调用 getUsers()。如果在 Class 的映射定义中,允许对 User 进行批量抓取,则 Hibernate 就会预先加载整个集合。
<set name=”users” batch-size=”15”>...</set>
4.3 二级缓存
缓存可以降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。缓存对 Hibernate 来说也是很重要的,它使用了如下图所示的多级缓存方案:
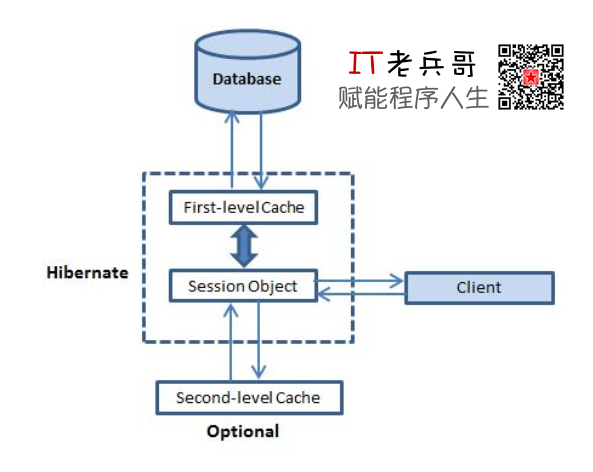
- 一级缓存,第一级缓存是 Session 缓存,属于强制性缓存,所有请求都必须通过它。Session 对象在它自己的权利之下,在将它提交给数据库之前保存一个对象。如果你对一个对象发出多个更新,Hibernate 会尝试尽可能长地延迟更新来减少发出的 SQL 更新语句的数目。如果你关闭 Session,所有缓存的对象丢失,或是存留,或是在数据库中被更新。
- 二级缓存,第二级缓存是可选择的,第一级缓存在任何想要在第二级缓存中找到一个对象前被询问。第二级缓存可以在每一个类和每一个集合的基础上被安装,并且它主要负责跨会话缓存对象。任何第三方缓存都可以和 Hibernate 合作,只要它实现 org.hibernate.cache.CacheProvider 接口。
Hibernate 的二级缓存通过两个步骤设置:
- 第一,你必须决定好使用哪个并发策略(Transactional、Read-write、Nonstrict-read-write、Read-only);
- 第二,你使用第三方缓存提供者来配置缓存到期时间和物理缓存属性。并发策略,负责保存缓存中的数据项和从缓存中检索它们,如何选择并发策略及配置可以查资料。
4.4 查询缓存
查询结果集也可以被缓存,只有在经常使用同样的参数进行查询时,查询缓存才会有些用处。如果要使用查询缓存,你必须打开它:hibernate.cache.use_query_cache,该设置将会创建两个缓存区域:一个用于保存查询结果集(org.hibernate.cache.StandardQueryCache);另一个则用于保存最近查询的一系列表的时间戳(org.hibernate.cache.UpdateTimestampsCache)。
在查询缓存中,它并不缓存结果集中所包含的实体的确切状态,它只缓存这些实体的标识符属性的值、以及各值类型的结果,所以查询缓存通常会和二级缓存一起使用。绝大多数的查询并不能从查询缓存中受益,所以 Hibernate 默认是不进行查询缓存的。如若需要进行缓存,请调用 Query.setCacheable(true) 方法。这个调用会让查询在执行过程中时先从缓存中查找结果,并将自己的结果集放到缓存中去。
关注「 IT老兵哥 」,赋能程序人生!坚持原创不易,请小伙伴们不吝点个「 赞 」哦!推荐软技能文章,请点击链接:程序员,怎样打造个人影响力?

近期热评系列《 程序员必须懂的架构师入门课 》:
- 架构到底是什么,你知道吗? (阅读人数:1218)
- 架构都有哪些,我该怎么选? (阅读人数:891)
- 架构师都干什么,你知道吗? (阅读人数:1192)
- 练就哪些技能才胜任架构师? (阅读人数:1157)
- 怎样才能搞定上下游的客户? (阅读人数:495)
- 如何从开发岗转型做架构师? (阅读人数:1309)
- 程序员必须懂的架构入门课 (阅读人数:611)
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/



![河豚抚子打工结束啦~明天就要去成都看熊猫啦!![舔屏] ](https://imgs.knowsafe.com:8087/img/aideep/2023/3/26/bb95d0cd813967b20dfc9003b4620fba.jpg?w=250)


 IT老兵哥
IT老兵哥
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 习近平引领网信事业高质量发展 4981771
- 2 女歌手在老人寿宴上踩裙摆摔倒去世 4952512
- 3 迪拜暴雨过后像“外星人入侵” 4871250
- 4 中国载重最大货运列车今将开行 4768210
- 5 男子钓到50斤大鱼绑车后逛街 4612864
- 6 孙艺洲真的COS吕布了 4505372
- 7 大妈在周杰伦演唱会VIP区呼呼大睡 4445115
- 8 葛斯齐替汪小菲发声引热议 4344752
- 9 网民造谣家家有猎枪 被处罚 4245478
- 10 中央财经大学多名学生吐槽800米体测 4103378