解密亚马逊AWS大规模重启服务器背后的故事
9月23日,XEN官方来了个帽子戏法,一口气爆出3个漏洞。随后,就有关于亚马逊AWS大规模重启服务器的消息爆出。这次重启事件不论是影响到的产品、还是持续的时间都是史无前例的,整个修复周期持续5天,从9月25日下午7点到9月30日下午5点,影响的产品包括EC2、RDS、ElastiCache、RedShift,其中EC2最为严重,大约占到AWS EC2总量的10%。由于是发生在美国,所以国内这块的报道较少,很多同学可能还不知道是什么漏洞,让亚马逊做如此大范围的重启操作。下面我们一块看看这三兄弟到底是啥来头。这次的三个漏洞,危害有哪些?
1、CVE-2014-7154
这个可以说是三兄弟中的老大,为何?因为它在关键位置有人,因为它老爹是dom0。dom0在XEN架构中的地位非常重要,它包含控制硬件的驱动和控制虚拟机的工具集。所以它会影响到整个物理机上面所有的虚拟机,这样的漏洞是最恐怖的,波及范围广,修补起来又需要重启,那就得业务中断啊,还有,如果重启起不来咋办??
2、CVE-2014-7155
这个可以排行老二,客户机可以利用该漏洞加载自己的IDT或GDT,可能导致虚拟机的宕机,还可以获取root权限。看到这里我们也不要太慌张,因为这里不是虚拟机逃逸,而是获取虚拟机的root权限。危害也不小,“黑阔”又多了一个提权利器。
3、CVE-2014-7156
与上述那俩老大哥比起来,就个漏洞危害就要差一些了。利用该漏洞,可能导致虚拟机的宕机,但宕机也不是小事,不容小觑,只是生不逢时。
神马是XEN?
在进行技术分析之前,我们先了解一下关于XEN的背景知识。
VMware大家都很熟悉了,无论是WorkStation还是企业级的ESX,XEN就是类似于ESX的一个软件,不过是开源的(类似的还有KVM)。现在KVM已经是Linux官方加入到内核中的虚拟化技术。
XEN最早由剑桥大学开发,现在被Citrix收购,亚马逊的AWS就是基于XEN技术的。通过下图我们来了解下XEN技术架构:
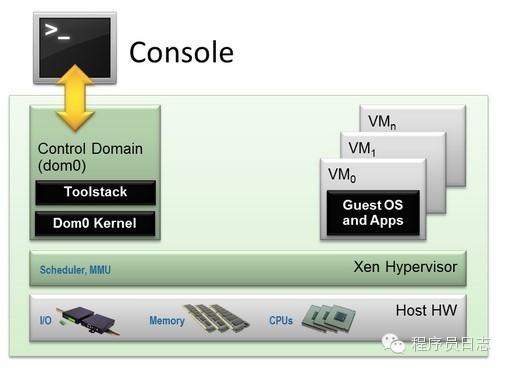 从上面可以看出,XEN hypervisor直接运行在硬件之上,负责处理CPU、内存、中断等。它是运行完bootloader之后第一个运行的程序。在hypervisor之上允许虚拟机,在XEN里面,一个虚拟机实例被称为domain或者guest。其中,domain0是一个特殊的domain,它包含所有控制硬件的驱动,同时包含控制管理虚拟机的工具集。
除了domain0之外,其它的虚拟机就是我们熟悉的guest,大致分为两种类型:Paravirtualization(PV)半虚拟化 和 Full Virtualization(HVM)全虚拟化。
PV是由XEN引入的,后来被其它虚拟化平台采用。半虚拟化是一种高效、轻量的虚拟化技术,它不需要物理机CPU含有虚拟化扩展,但却需要一个Xen-PV-enabled内核和PV驱动,说白了就是需要修改虚机系统的内核,好在Linux、BSD、OpenSolaris等提供了该内核,但是Windows就不行了,因为只有微软可以修改它的内核。
HVM使用了物理机CPU的虚拟化扩展来虚拟出虚拟机。该技术需要Intel VT或者AMD-V硬件扩展。Xen使用Qemu来仿真PC硬件,包括BIOS、IDE硬盘控制器、VGA、USB控制器、网卡等等。由于使用虚拟机硬件扩展来提高仿真性能,所以HVM不需要修改内核,因此其上可以运行Windows系统。技术揭秘现在我们大致了解了这三漏洞有啥危害了,下面我们跟着官方的漏洞通告和补丁文件,来具体分析下这些漏洞。
1、CVE-2014-7154
CVE-2014-7154说的是在HVMOP_track_dirty_vram里面存在竟态条件,HVMOP_track_dirty_vram是一个用来控制脏显存跟踪设置的函数。下面是官方给出的补丁:
从上面可以看出,XEN hypervisor直接运行在硬件之上,负责处理CPU、内存、中断等。它是运行完bootloader之后第一个运行的程序。在hypervisor之上允许虚拟机,在XEN里面,一个虚拟机实例被称为domain或者guest。其中,domain0是一个特殊的domain,它包含所有控制硬件的驱动,同时包含控制管理虚拟机的工具集。
除了domain0之外,其它的虚拟机就是我们熟悉的guest,大致分为两种类型:Paravirtualization(PV)半虚拟化 和 Full Virtualization(HVM)全虚拟化。
PV是由XEN引入的,后来被其它虚拟化平台采用。半虚拟化是一种高效、轻量的虚拟化技术,它不需要物理机CPU含有虚拟化扩展,但却需要一个Xen-PV-enabled内核和PV驱动,说白了就是需要修改虚机系统的内核,好在Linux、BSD、OpenSolaris等提供了该内核,但是Windows就不行了,因为只有微软可以修改它的内核。
HVM使用了物理机CPU的虚拟化扩展来虚拟出虚拟机。该技术需要Intel VT或者AMD-V硬件扩展。Xen使用Qemu来仿真PC硬件,包括BIOS、IDE硬盘控制器、VGA、USB控制器、网卡等等。由于使用虚拟机硬件扩展来提高仿真性能,所以HVM不需要修改内核,因此其上可以运行Windows系统。技术揭秘现在我们大致了解了这三漏洞有啥危害了,下面我们跟着官方的漏洞通告和补丁文件,来具体分析下这些漏洞。
1、CVE-2014-7154
CVE-2014-7154说的是在HVMOP_track_dirty_vram里面存在竟态条件,HVMOP_track_dirty_vram是一个用来控制脏显存跟踪设置的函数。下面是官方给出的补丁:
从上面可以看出,XEN hypervisor直接运行在硬件之上,负责处理CPU、内存、中断等。它是运行完bootloader之后第一个运行的程序。在hypervisor之上允许虚拟机,在XEN里面,一个虚拟机实例被称为domain或者guest。其中,domain0是一个特殊的domain,它包含所有控制硬件的驱动,同时包含控制管理虚拟机的工具集。
除了domain0之外,其它的虚拟机就是我们熟悉的guest,大致分为两种类型:Paravirtualization(PV)半虚拟化 和 Full Virtualization(HVM)全虚拟化。
PV是由XEN引入的,后来被其它虚拟化平台采用。半虚拟化是一种高效、轻量的虚拟化技术,它不需要物理机CPU含有虚拟化扩展,但却需要一个Xen-PV-enabled内核和PV驱动,说白了就是需要修改虚机系统的内核,好在Linux、BSD、OpenSolaris等提供了该内核,但是Windows就不行了,因为只有微软可以修改它的内核。
HVM使用了物理机CPU的虚拟化扩展来虚拟出虚拟机。该技术需要Intel VT或者AMD-V硬件扩展。Xen使用Qemu来仿真PC硬件,包括BIOS、IDE硬盘控制器、VGA、USB控制器、网卡等等。由于使用虚拟机硬件扩展来提高仿真性能,所以HVM不需要修改内核,因此其上可以运行Windows系统。技术揭秘现在我们大致了解了这三漏洞有啥危害了,下面我们跟着官方的漏洞通告和补丁文件,来具体分析下这些漏洞。
1、CVE-2014-7154
CVE-2014-7154说的是在HVMOP_track_dirty_vram里面存在竟态条件,HVMOP_track_dirty_vram是一个用来控制脏显存跟踪设置的函数。下面是官方给出的补丁:
p2m_type_t t; - struct sh_dirty_vram *dirty_vram = d->arch.hvm_domain.dirty_vram; + struct sh_dirty_vram *dirty_vram; struct p2m_domain *p2m = p2m_get_hostp2m(d); if ( end_pfn < begin_pfn || end_pfn > p2m->max_mapped_pfn + 1 ) @@ -3495,6 +3495,8 @@ int shadow_track_dirty_vram(struct domai p2m_lock(p2m_get_hostp2m(d)); paging_lock(d); + dirty_vram = d->arch.hvm_domain.dirty_vram; + if ( dirty_vram && (!nr ||从补丁中可以看出,在没有打补丁的代码里,系统在获取paging_lock之前,已经获取到了dirty_vram的值。这里有一个潜在的问题,两个并发的hypercall会尝试同时释放dirty_vram,那么两者中,第二个尝试进行释放的是一个野指针。另外,两个并发的hypercall也可能会尝试同时创建一个新的dirty_vram结构体,那么最先创建的那块内存会泄漏,因为第二个dirty_vram创建之后,两个指针都指向新的dirty_vram结构体。 所以修补起来也很简单,就是将获取d->arch.hvm_domain.dirty_vram的值放到获取了paging_lock之后。 2、CVE-2014-7155 CVE-2014-7155讲的是在x86的HLT、LGDT、LIDT、LMSW指令模拟时没有做特权检查,这些指令都是用来加载全局描述附表、中断描述符表或者局部描述符表等。恶意的客户机程序可以安装自己的IDT(中断描述符表),这些恶意行为会导致客户机宕机,或者进行提权。
case 0xf4: /* hlt */ + generate_exception_if(!mode_ring0(), EXC_GP, 0); ctxt->retire.flags.hlt = 1; break; @@ -3710,6 +3711,7 @@ x86_emulate( break; case 2: /* lgdt */ case 3: /* lidt */ + generate_exception_if(!mode_ring0(), EXC_GP, 0); generate_exception_if(ea.type != OP_MEM, EXC_UD, -1); fail_if(ops->write_segment == NULL); memset(®, 0, sizeof(reg)); @@ -3738,6 +3740,7 @@ x86_emulate( case 6: /* lmsw */ fail_if(ops->read_cr == NULL); fail_if(ops->write_cr == NULL); + generate_exception_if(!mode_ring0(), EXC_GP, 0); if ( (rc = ops->read_cr(0, &cr0, ctxt)) ) goto done;从补丁中可以看出,系统通过在模拟htl、lgdt、lidt、lmsw的时候,增加了generate_exception_if()宏来解决该问题。该宏对运行在非ring0模式下的htl等指令,会产生EXC_GP异常。下面是generate_exception_if的宏定义:
#define generate_exception_if(p, e, ec) \ ({ if ( (p) ) { \ fail_if(ops->inject_hw_exception == NULL); \ rc = ops->inject_hw_exception(e, ec, ctxt) ? : X86EMUL_EXCEPTION; \ goto done; \ } \ })从generate_exception_if(!mode_ring0(), EXC_GP, 0)可以看出,对运行在ring0模式的指令不做任何操作,对运行在非ring0模式的指令,执行了检查。首先看是否定义了inject_hw_exception函数,如果没有定义,则ops->injdect_hw_exception == NULL的结果为真,根据fail_if的宏定义可以发现直接产生X86EMUL_UNHANDLEABLE:
#define fail_if(p) \ do { \ rc = (p) ? X86EMUL_UNHANDLEABLE : X86EMUL_OKAY; \ if ( rc ) goto done; \ } while (0)如果在ops中定义了inject_hw_excption,则调用hvmemul_inject_hw_exceptio()函数来设置该异常的相关信息:
static int hvmemul_inject_hw_exception( uint8_t vector, int32_t error_code, struct x86_emulate_ctxt *ctxt) { struct hvm_emulate_ctxt *hvmemul_ctxt = container_of(ctxt, struct hvm_emulate_ctxt, ctxt); hvmemul_ctxt->exn_pending = 1; hvmemul_ctxt->exn_vector = vector; hvmemul_ctxt->exn_error_code = error_code; hvmemul_ctxt->exn_insn_len = 0; return X86EMUL_OKAY; }通过查看宏定义,发现X86EMUL_OKAY的值为0:
/* Completed successfully. State modified appropriately. */ #define X86EMUL_OKAY 0 /* Unhandleable access or emulation. No state modified. */ #define X86EMUL_UNHANDLEABLE 1 /* Exception raised and requires delivery. */ #define X86EMUL_EXCEPTION 2所以当inject_hw_exception不为NULL的时候,generate_exception_if在调用hvmemul_inject_hw_exception设置完相应的异常信息之后,产生X86EMUL_EXCEPTION异常。从上面的宏定义可以看出,不论是X86EMUL_UNHANDLEABLE异常还是X86EMUL_EXCEPTION异常,都会导致指令不执行。 3、CVE-2014-7156 CVE-2014-7156讲的是在x86中模拟软中断的时候,没有做特权检查,恶意的HVM客户机上面的代码能够使客户机宕机。 补丁说明只允许在实模式中进行软中断模拟,所以补丁也很简单,检测到在非实模式下模拟软中断的时候就退出:
case 0xcd: /* int imm8 */ src.val = insn_fetch_type(uint8_t); swint: + fail_if(!in_realmode(ctxt, ops)); /* XSA-106 */ fail_if(ops->inject_sw_interrupt == NULL)总结 其实我们看看3个补丁,发现貌似没做啥啊,只是换了换代码的位置,或加了一个函数或者宏。这说明XEN其实已经有解决问题的方案,只不过在某些指令的处理上,没有考虑到所有的使用场景,因此漏掉了相应的检查。那是不是其它指令在某些场景下还会有类似的问题呢?嘿嘿,我只能说漏洞时时有,这阵子特别多,所以我们多关注关注XEN的官方漏洞通告页面就知道了。 再看看IaaS云老大亚马逊AWS,不得不说他们的响应速度很快,对安全也重视,没有侥幸心理,该补的补,该重启的重启,重视安全的态度由此可见。但话说回来,出发点虽好,但是有没有更好的处理方式呢,既可以修补漏洞又可以不重启服务器的? 必须有!UCloud的内核团队这方面有很深入的研究:内核热补丁。通过该技术可以给运行中的Linux服务器打上内核补丁,既可以解决存在的问题,最重要的是不需要重启服务器。这项技术在UCloud已经广泛使用,已经免重启修复过十几个内核BUG。 本月16日在上海QCon的活动上,欢迎大家就内核相关的问题与UCloud资深工程师邱模炯进行交流。 本公众账号也将在近期推出《内核热补丁技术揭秘》,欢迎关注!
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/


![热牛奶cc 这草可真埋汰[交税] ](https://imgs.knowsafe.com:8087/img/aideep/2022/12/11/5813ae490af8840dd424db0a266e362c.jpg?w=250)



 邮箱投递
邮箱投递
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 中国经济向世界提供“机遇清单” 7904268
- 2 朱元璋换帅照后明孝陵火了 7808173
- 3 水银体温计将禁产 有网友囤货100支 7712442
- 4 2025这些“经济”持续成长壮大 7617027
- 5 近8000吨车厘子来了 7520006
- 6 老人接孙女从认不出到相拥大哭 7426793
- 7 冯提莫自曝癌症复发并转移 7330982
- 8 西班牙女员工连续提前到岗被开除 7233721
- 9 男子毒杀儿女案细节披露 7140564
- 10 寒潮来袭!多地气温将创下半年来新低 7044045