GitHub上最火的项目到底是什么


全球最大的同性交友网站GitHub作为程序员必逛平台,其众多开源项目的关注度一直都比较高。当然有对科技的项目的关注,比如容器编排工具K8s,当然也有程序员民生项目996icu等不一而足。
那么问题来了,作为一个科技宅,足不出户,如何才能实时掌握社交网站上的动态呢?现在我们就用一个小爬虫,加上Azure上的两个大数据工具开始手把手教学指导。
首先介绍的是Azure Data Explorer(以下简称ADX),次世代的数据日志大数据分析工具。ADX是一项快速、完全托管的数据分析服务,可实时分析从应用程序、网站和 IoT 设备等流式传输的海量数据。进行提问并以迭代方式动态浏览数据,从而改进产品、改善客户体验、监视设备并帮助操作。快速识别数据中的模式、异常和趋势。探索新问题并在几分钟内获得答案。凭借优化后的成本结构,根据需要尽量多地运行查询。

在开始建立这些大数据服务之前,让我们先建立一个Storage Account,并且分配一个容器,这样之后所有Azure Event Hubs收集的数据都会沉淀到Blob Storage里,随后ADX,HDI都可以到里面去读取数据,分析结果。

建立一个Azure Event Hubs
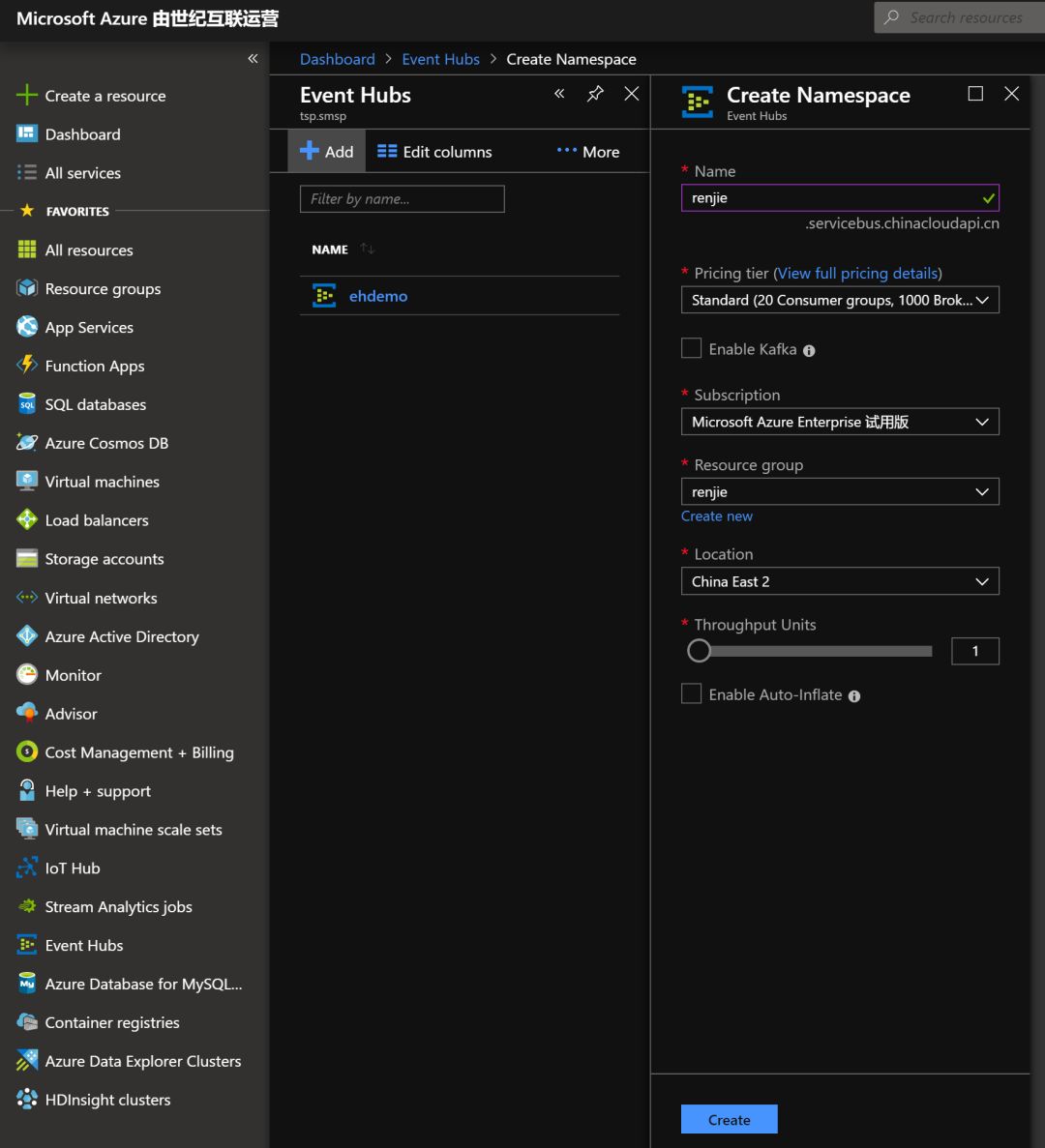
等建完之后,还需要到里面去建一个Azure Event Hubs实体。需要注意的是要打开Capture功能,这样流式数据不但可以通过Azure Event Hubs直接传递到ADX里面,同时也可以沉淀到Blob里,这样之后Spark就能从里面读取数据了

等待实体建立好之后,需要到访问控制里面去新建一个访问策略。并记下连接串,以及密钥。随后是需要在爬虫程序里面填入相关的信息的。

接下来我们打开爬虫的文件,填入需要修改的连接串,以及密钥。其中有两个地方需要修改。一个是你的GitHub的token,用来调用api抓取数据,如果不用这个的话,你的ip可能很快就被封锁。另外一个地方就是Azure Event Hubs的链接地址,以及相对应的token。

回到Azure的Azure Event Hubs的界面上,就能看到有源源不断的数据进入到Azure Event Hubs
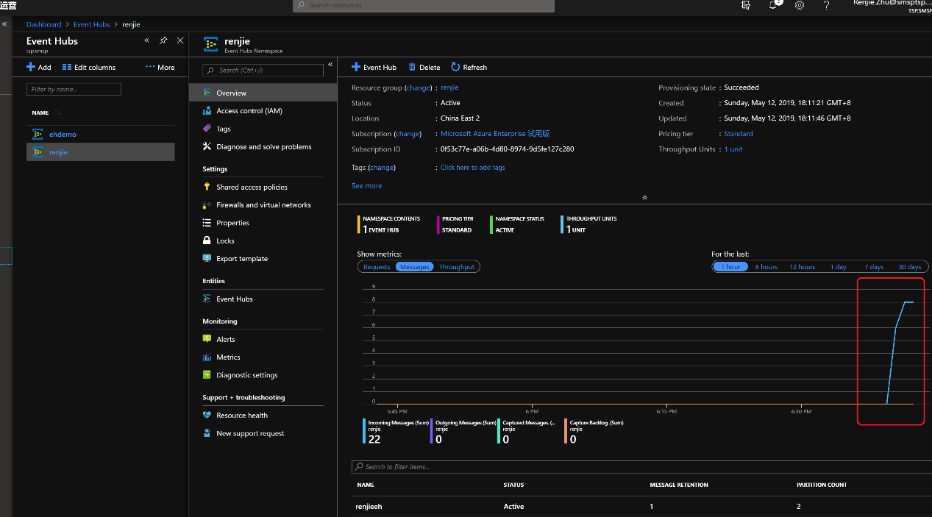
再到我们刚在建立的blob容器中也去检查一下,是不是Azure Event Hubs把所有的数据发送了过去。这里你会发现Azure Event Hubs capture的数据格式是比较流行的avro文件,之后我们就可以用spark来分析他们啦。
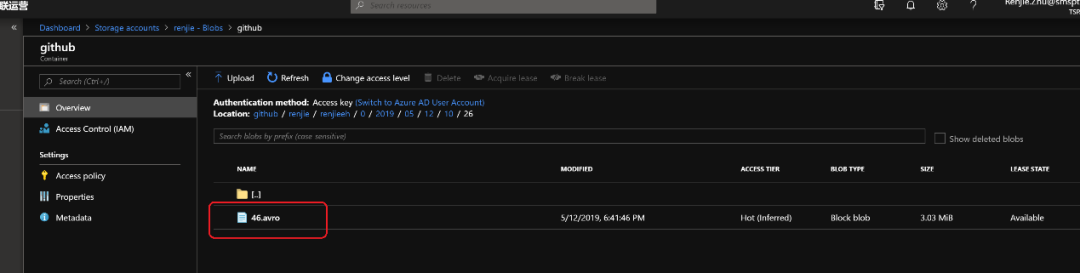
首先,建立一个ADX集群

接着,在ADX中建立一个数据库,以及表格,使表格和GitHub上传递来的数据匹配。
a)???? 新建一个数据表

b)? ??把数据字段做匹配

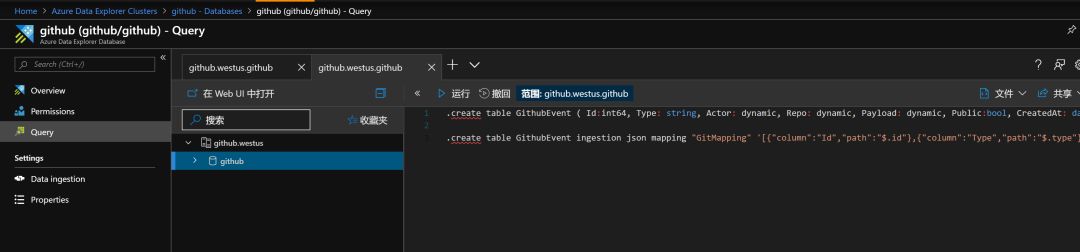
然后到数据导入的地方,把Azure Event Hubs的相关链接数据填入,就此,数据就能愉快的,持续不断的导入到ADX中了。

现在,我们需要快速的用KQL语句来对最流行的项目做一个查询。发现最近不论watch,还是issue,微软的build大会上发布的全能Terminal最近风靡GitHub,当然还有已经毕业的开源项目K8s,同时发现微软的文档的关注量也不断上升。不过需要注意的是,GitHub 项目排名实时更新,本文结果不能代表最新数据哦,欢迎大家动手实践。

这个部分,我们首先构建一个HDInsight集群,注意选择Spark, 以及在容器那里选择之前创建的那个,以便之后方便读取Azure Event Hubs沉淀下的数据

当集群建立之后,打开jypter notebook,就可以开始使用spark进行大数据计算了

在Jupyter notebook中,首先我们要先配置读取avro文件的模块。

然后就可以把所有的avro文件读入,之后变成Json格式的dataframe。把dataframe中的项目,按照人们对项目的watch,issue等操作,做了一个一个加权统计,就能得出最近最火热的项目了。可以看到,第一名是微软的Terminal项目。

对于爬虫,或者物联网等流式数据来说,Azure Event Hubs是一个很好的接入云端,并且进行数据吞吐,流式数据存储分发的好产品。因为你不需要管理一个Kafaka集群,不用担心如何分区,如何扩容,如何做高可用。另外最方便的一点是可以简单的与其他Azure上的PaaS做集成,比如这个例子当中的ADX,HDInsight,并且所有的数据可以规整到数据存储池里,这样就可以作为其他数据分析工具的数据来源,真正做到一起数据不需要经过抽取,直接现在数据湖里存储暂存。
本例中的两个数据分析工具,先来看看Azure Data Explorer,这个工具听起来似乎很陌生,但是据我所知,微软内部很早就在使用这个数据日志分析工具,之前的名字很特别,叫做Kusto。之前一直作为内部的数据分析工具,很多微软的工程师都用这个来分析Azure平台的运行数据哦,为保障Azure固若金汤的运行立下了汗马功劳。在本例中,大家也许发现ADX运行的特别快,其实比Spark要快不少,主要就得益于他独有的的KQL查询语句,对于非结构的数据,他的查询效率适合结构化的类似的,所以本例中对Json类的非结构文本查询的时候,基本可以做到秒级的查询。这样的话,对实时性高的的业务分析,将会起到很好的效果,比如物联网,实时监控类的场景。
那么另外的一个我们用来分析的工具是HDInsight Spark集群,这是一个Azure上老牌的产品了,那么提供的用户体验就是用户只需要一键建立Spark集群后,就不需要去维护了。那么对于那些熟悉开源Spark的开发人员来说,代码迁移,以及学习成本其实可以认为就是没有的。同时,如果觉得集群效率不够,可以动态的扩展集群,增快计算时间,反之亦然。当然,当你不用计算的时候,就可以把集群关闭,但是那些计算的数据,以及结果会被继续存在Blob存储当中,这一点简直是把云计算的灵活性以及经济型使用到了极致。
所以,整个例子,你只需要用半天时间,就能在Azure上用两种不同的方法,达到同样的目标。没错,Azure就是这样神奇的存在,就像背了一下魔法口诀一样轻盈。
福利赠送:GitHub代码传送门
https://GitHub.com/jurejoy/ADX-Spark
[1] Azure Data Explorer(Azure数据资源管理器)服务详情
https://azure.microsoft.com/zh-cn/services/data-explorer/
[2]Azure HDInsight 服务详情
https://azure.microsoft.com/zh-cn/services/hdinsight/


微软作为本次世界人工智能大会的重量级“伙伴企业”,将携全球顶尖人工智能技术及解决方案亮相。本次会议极具国际性、权威性和专业性,现场将汇集多种亮眼人工智能展品,届时还会有多位行业资深专家到场。
立即扫描二维码,免费参加活动,感受现代顶尖科技风采。




叮咚!一封来自世界人工智能大会的邀请函
出海下半场,企业如何才能少交学费?
盘点你常遇到的5大职场困境
最新活动

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

![一只喵喵梓[紧急企划] NO.003](https://imgs.knowsafe.com:8087/img/aideep/2022/11/27/a6c59ea73692b584aa37a1d154861d76.jpg?w=250)




 微软科技
微软科技
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 打好关键核心技术攻坚战 7904596
- 2 在南海坠毁的2架美国军机已被捞出 7808386
- 3 立陶宛进入紧急状态 卢卡申科发声 7714661
- 4 持续巩固增强经济回升向好态势 7615831
- 5 多家店铺水银体温计售空 7523862
- 6 奶奶自爷爷去世9个月后变化 7426220
- 7 仅退款225个快递女子已归案 7328929
- 8 日舰曾收到中方提示 7234765
- 9 中国中冶跌10.03% 7137317
- 10 我国成功发射遥感四十七号卫星 7044632