
刚刚,Google发布24个小型BERT模型,直接通过MLM损失进行预训练

??新智元原创??
??新智元原创??
编辑:鹏飞
【新智元导读】Google刚刚发布了24个小型BERT模型,使用WordPiece masking进行训练,具有更少的层数,在MLM蒸馏的更精细的预训练策略方面极具优势,适用于资源受限的场景,并鼓励构建更紧凑的模型。「新智元急聘主笔、编辑、运营经理、客户经理,添加HR微信(Dr-wly)了解详情。」
Google最新推出24个精简的BERT模型供下载,赶在白色情人节之前为广大NLP研究者送上一份厚礼。
BERT胜在模型大,也败在模型大!
BERT一出世就带着「狂破11项记录」的光环,用压倒性的参数量暴力突围。可以说,BERT的成功,成就成在模型大。但大,一方面成就了BERT,另一方面也成了它无法被更广泛应用的障碍,这体现在三个方面。
障碍一:占资源

巨大的体积使得它必须占用巨大的存储资源,而维护大量存储资源的同时也在不断消耗大量的能源。
障碍二:太耗时
BERT作者Jacob曾提到「BERT-Large模型有24层、2014个隐藏单元,在33亿词量的数据集上需要训练40个Epoch,在8块P100上可能需要1年」。
障碍三:费用高
有人曾经计算过,三大主流模型的训练成本大概是:
BERT:1.2 万美元 GPT-2:4.3 万美元 XLNet:6.1 万美元
为了解决上述问题,人们不断推出精简版BERT
Size matters。其实上述3个问题,源头就在于Size,因此大家开始不断的研究精简版BERT。在资源有限的情况下,小体积的模型有着不言而喻的优势。
DistillBERT:Hugging Face团队在BERT的基础上用知识蒸馏技术训练出来的小型化BERT。模型大小减小了40%(66M),推断速度提升了60%,但性能只降低了约3%。
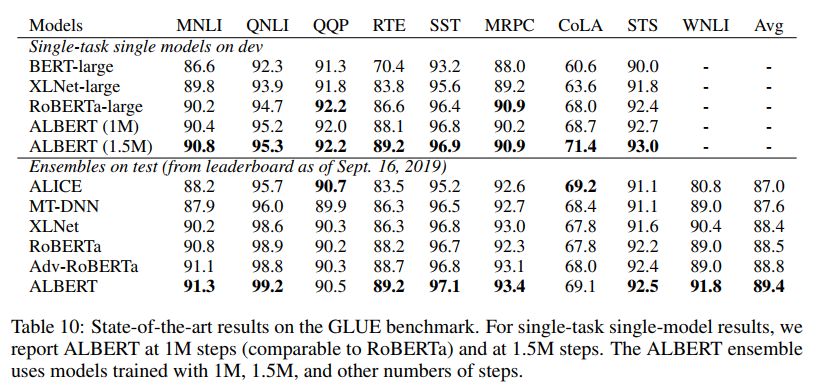
ALBERT:通过改变模型架构,极大的降低了体积。最小的ALBERT只有12M,最大ALBERT-XXLarge有233M,而BERT-Base就有110M。不过虽然体积下去了,推理速度没有太明显的提升。
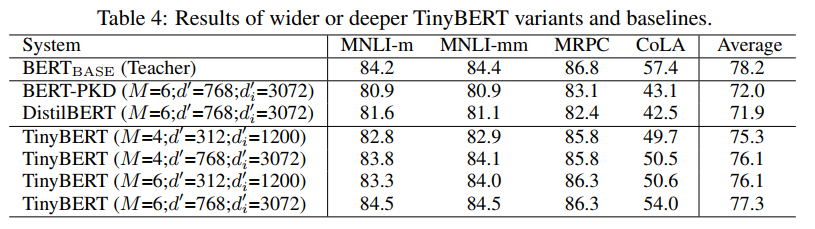
TinyBERT:用知识蒸馏的方法来压缩模型。这个模型由华中科大和华为共同出品。
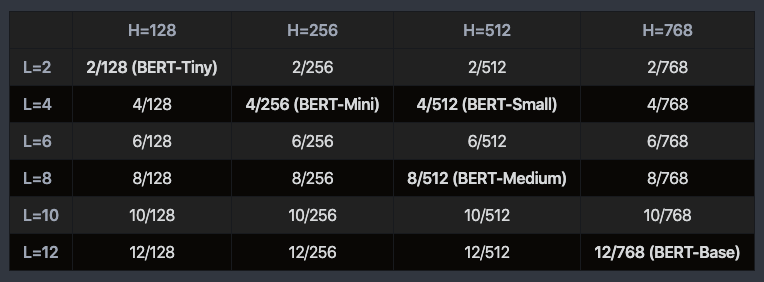
Google亲自推出更小型BERT模型
就在昨天,Google更新了BERT的GitHub仓库,发布了24个较小的BERT模型,仅限英语词汇且不分大小写。
该24个模型使用WordPiece masking进行训练,直接通过MLM损失进行预训练,可以通过标准训练或最终任务提炼针对下游任务进行微调,在MLM蒸馏的更精细的预训练策略方面极具优势。
理论指导来自论文《Well-Read Students Learn Better: On the Importance of Pre-training Compact Models》。论文地址:https://arxiv.org/abs/1908.08962
小的BERT模型只需要按照原有BERT微调方式进行微调即可,只不过在由更大、更精准的teacher制作的知识蒸馏情况下最有效。
需要注意的是,本发行版中的BERT-Base模型仅是出于完整性考虑,在和原始模型相同的条件下进行了重新训练。
GLUE分数:

24个小型BERT下载地址:https://storage.googleapis.com/bert_models/2020_02_20/all_bert_models.zip
【新智元视频直播分享|1小时逐行实现目标检测经典模型】
新智元视频直播公开课上线啦,锁定今天下午15:00-16:00,京东AI特邀专家朱利明在线分享。
【课程简介】:本课程着重讲解如何更好、更快、更强的目标检测YOLO模型,手把手教学带你详解Anchor机制,使用Pytorch逐行实现YOLO模型,让你掌握One-Stage目标检测器原理!
【讲师介绍】:朱利明,京东AI特邀专家,毕业于中国科学院研究生院,主导100+大型商业项目,近二十年算法研发经验。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675