盗版资源变少?这个比人还“眼尖”的 NLP 模型立下汗马功劳





盗版搜索结果分析
1、?用户搜索盗版影片示例
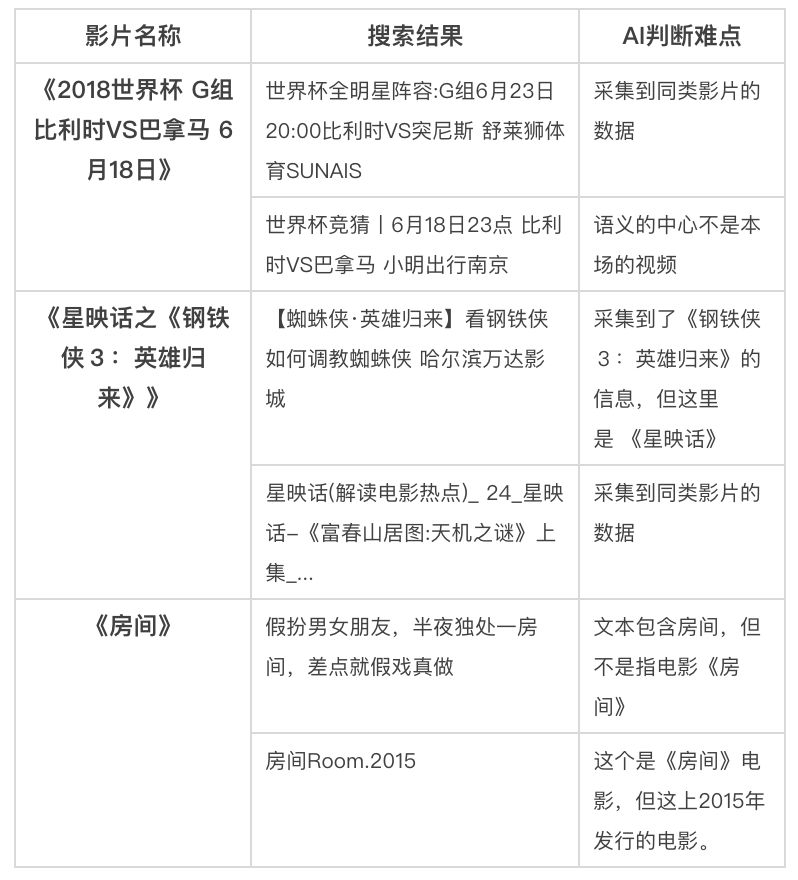 ?2、?“判断难点“分析
?2、?“判断难点“分析1)??归类“判断难点”
(1)?名称近似类:系列类影片、名称包含类影片;
(2)?主题不相关类:结果是资讯、新闻、彩票、广告等信息;
(3)?同名影片类:相同影片的歌曲、游戏、戏剧、通用名词等有歧义的信息;
(4)?变换类:?影片名称缩写、人工故意添加的干扰信息。

2)?自然语言识别中怎样处理这几种情况?
(1)?名称近似类:?

文本预处理:清洗样本,并将文本格式、符号转化为统一的形式; 特征计算:?将文本转化为数字。这一步可以使用特征工程,或者词袋(oneHot)、文本嵌入(word embedding)模型、深度Transformer模型; 模型训练/预测:选择合适的模型算法,训练模型。模型方面可以使用决策树类型(例如:XGBoost、LightGBM、Deep Forest等等),也可以使用深度网络(例如:LSTM、BERT、Transformer-XL等等)。当然也可以使用多个模型(一个模型的输出,作为一个模型的输入)。




总结
?以太坊2.0、分片、DAG、链下状态通道……概述区块链可扩展性的解决方案!

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

![谭小灵 你喜欢甜的 又拒绝不了辣的 那我只好两个都占[害羞]](https://imgs.knowsafe.com:8087/img/aideep/2024/2/15/222349870ec9e5956df2f89b602822a3.jpg?w=250)




 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 中央经济工作会议在北京举行 7904582
- 2 中央定调明年继续“国补” 7809014
- 3 断崖式降温!今冬最强寒潮来了 7714694
- 4 “九天”无人机成功首飞 7617086
- 5 紧急提醒:请在日中国公民进行登记 7520866
- 6 中央经济工作会议释信号:3件事不做 7427816
- 7 网警:男子AI生成车展低俗视频被拘 7327475
- 8 4人喝近120瓶啤酒惊呆老板 7238541
- 9 人民空军中日双语发文:大惊小怪 7135385
- 10 寒潮来袭 “速冻”模式如何应对 7040862