
谷歌大脑联手Hinton提出SimCLR新框架,疯狂提升自监督学习性能 | 北邮毕业生一作

??新智元报道??
【新智元导读】Hinton团队新作SimCLR似乎打开了自监督学习的大门,自监督学习的效果到底如何?最近Google发表了一篇博客,介绍了他们使用SimCLR的经验,通过图像扩增,模型扩展等手段提高了自监督和半监督模型的训练效果。「新智元急聘主笔、高级主任编辑,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」
BERT和T5之类的自然语言处理模型不断“屠榜xxx”的新闻,恐怕我们都已经看的麻木了。
实际上,自监督学习并没有那么好,为什么?
作为一种特殊的无监督学习方式,自监督学习是通过从未标记数据集中创建替代标签而将无监督学习问题转换为有监督问题。
然而,当前用于图像数据的自监督技术非常复杂,需要对体系结构或训练过程进行重大修改。
在“视觉表示对比学习的简单框架”中,Google概述了一种方法,该方法不仅可以简化而且可以改进以前在图像上进行自监督表示学习的方法。其提出的名为SimCLR的框架,极大地提高了自监督和半监督学习的技术水平,并以有限的类别标签数据达到了ImageNet图像分类的SOTA效果。
方法的简单性意味着可以轻松地将其合并到现有的有监督学习管道中。
SimCLR:一个简单的视觉表示对比学习框架
SimCLR是一个简单的视觉表示对比学习框架,它不仅比以前的工作更出色,而且也更简单,既不需要专门的架构,也不需要储存库。
SimCLR首先学习未标记数据集上图像的一般表示,然后可以使用少量标记图像对其进行微调,以实现给定分类任务的良好性能。通过采用一种称为对比学习的方法,可以通过同时最大化同一图像的不同变换视图之间的一致性以及最小化不同图像的变换视图之间的一致性来学习通用表示。利用这一对比目标更新神经网络的参数,使得相应视图的表示相互“吸引”,而非对应视图的表示相互“排斥”。
首先,SimCLR从原始数据集中随机绘制示例,并使用简单增强(随机裁剪、随机颜色失真和高斯模糊)的组合将每个示例转换两次,创建两组相应的视图。
对单个图像进行这些简单转换的基本原理是:
我们要鼓励转换后相同图像的“一致”表示;
由于预训练数据缺少标签,我们无法预先知道哪个图像包含哪个对象;
我们发现这些简单的转换足以使神经网络学习良好的表示,尽管也可以采用更复杂的转换策略。
然后,SimCLR使用基于ResNet架构的卷积神经网络变量计算图像表示。接着,SimCLR使用完全连接的网络(即MLP)计算图像表示的非线性投影,这会放大不变特征并使网络识别同一图像的不同变换的能力最大化。为了最小化对比目标的损失函数,我们使用随机梯度下降来更新CNN和MLP。在对未标记的图像进行预训练之后,我们可以直接使用CNN的输出作为图像的表示,也可以使用标记的图像对其进行微调,以实现下游任务的良好性能。

上图为SimCLR框架演示。同时训练CNN和MLP层以产生对于同一图像的增强版本相似的投影,而对于不同图像则产生不同的投影,即使这些图像是同一类对象。经过训练的模型不仅可以很好地识别同一张图片的不同变换,而且可以学习相似概念的表示(例如椅子与狗),随后可以通过微调将其与标签相关联。
框架简介
为了理解什么可以促进良好的对比表示学习,我们系统地研究了框架的主要组成部分,并表明:
在定义产生有效表示的对比预测任务时,多个数据增强操作的组成至关重要。此外,与监督学习相比,无监督的对比学习受益于更强大的数据增强。
在表示和对比损失之间引入可学习的非线性变换,可以大大提高学习的表示的质量。
具有对比交叉熵损失(contrastive cross entropy loss)的表示学习得益于规范化嵌入和合适的调整参数。
与有监督的对照组相比,对比学习受益于较大的批量和较长的训练。与监督学习一样,对比学习也得益于更深更广的网络。
我们结合这些发现,在ImageNet ILSVRC-2012上实现了自监督和半监督学习的最新技术。在线性评估方案下,SimCLR的top-1准确性达到76.5%,相对于之前的最新技术水平有7%的相对提高。如果仅使用1%的ImageNet标签进行微调,SimCLR的top-5准确性将达到85.8%,相对提高10%。当在其他自然图像分类数据集上进行微调时,SimCLR在12个数据集中的10个数据集上的表现与强监督基线相当或更优。
SimCLR为何能有这么好的效果?
尽管SimCLR 很简单,但是它极大地提高了 ImageNet 上自监督和半监督学习的SOTA效果。基于 SimCLR 学习的自监督表示学习训练的线性分类器可以达到76.5% / 93.2%的 top-1 / top-5的准确率,而之前的最好的模型准确率为71.5% / 90.1%。与较小的的监督式学习模型ResNet-50性能相当,如下图所示
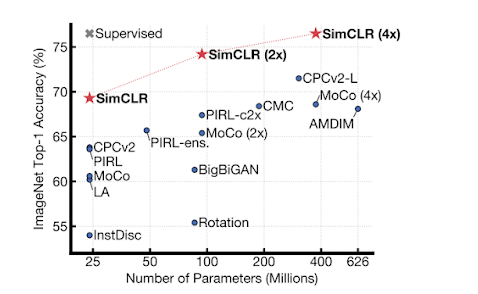
基于不同自监督方法训练的线性分类器的 ImageNet top-1精度(在 ImageNet 上预先训练)。灰色十字表示有监督的 ResNet-50
当只对1% 的标签进行微调时,SimCLR 达到了63.0% / 85.8% 的 top-1 / top-5准确率,而之前表现最好的(CPC v2)的准确率为52.7% / 77.9% 。令人惊讶的是,当对100% 的标签进行微调时,经过预先训练的SimCLR模型仍然可以明显优于从头开始训练的有监督基线模型,例如,基于SimCLR预先训练的 ResNet-50(4x)经过微调 ,在训练30个epoch时达到了80.1%的top-1准确率,而从头开始训练的模型在90个epoch才能到78.4%。
与以前的方法相比,SimCLR 的改进并不是因为某个单独的设计,而是它们的组合。
多种图像转换组合对生成对比视图是至关重要的
由于 SimCLR 通过最大化同一图像的不同视图的一致性来学习表示,因此不能只用单一的模式进行图像扩增,比如颜色直方图,组合各种图像变换方法很重要。为了更好地理解这一点,我们探索了不同类型的转换,如下图所示

我们发现,虽然没有一个单独的转换可以产生最佳的表示,但是随机剪裁和随机颜色失真非常有效,虽然裁剪和色彩失真本身都不会提高太多性能,但组合这两种转换可以达到SOTA效果。
为什么随机裁剪和随机颜色失真相结合是很重要?考虑一下在同一图像的两个剪裁视图之间最大化一致性的过程。自然包含了两种类型的预测任务: 左侧的情况要从全局预测局部视图,而右侧的都要预测近邻视图。
同一图像的不同剪裁视图在色彩空间中看起来非常相似, 如果颜色保持完整,模型可以通过匹配颜色直方图来最大化视图之间的一致性。在这种情况下,模型可能只关注颜色而忽略其他更通用的特性。通过独立地扭曲每种视图的颜色,浅层的特征将被去除,模型只能用可概括的颜色特征来表示一致性。
非线性投影很重要
在 SimCLR 中,在计算对比学习目标的损失函数之前,采用基于 MLP的非线性投影,有助于识别每个输入图像的不变特征,最大限度地提高网络识别同一图像不同变换的能力。在我们的实验中,我们发现使用非线性投影有助于提高表示的质量,将一个SimCLR学习到的表示输入给线性分类器,效果提升达到10%以上。
有趣的是,MLP 投影前的表示在线性分类器中反而比投影后的表现更好,而我们对比目标的损失函数是基于投影后的表示,我们猜想我们的目标会导致网络的最后一层(可能对下游任务有用的)特征不可变,而使用额外的非线性投影模块时,投影之前的表示可以保留更多有用的图像信息。
模型扩展可以显著提高性能
我们发现在同一批次中处理更多样本,使用更大的网络,以及训练更长的时间会带来显着的性能提升。尽管这些手段显而易见,但对于SimCLR而言,这些改进似乎比对监督学习的改进大。例如,我们观察到有监督的ResNet的性能在ImageNet上训练90到300个epoch会达到峰值,但是SimCLR即使经过800个epoch仍可以继续改善。当我们增加网络的深度或宽度时,也是这种情况– SimCLR的性能持续增长,而对于有监督模型则会停滞。
无监督学习已经超越有监督学习?
我们来看一些相关的报道。
“如今,在 ImageNet 上的图像识别准确率的性能提升每次通常只有零点几个百分点,而来自图灵奖获得者 Geoffrey Hinton 等谷歌研究者的最新研究一次就把无监督学习的指标提升了 7-10%,甚至可以媲美有监督学习的效果。”
“在 ImageNet 上,SimCLR 方法训练出的线性分类器与有监督的 ResNet-50 性能相匹配,达到了 76.5% 的 top-1 准确率。”
媒体报道给我的感觉是无监督能够做到跟有监督差不多好了,情况果真如此乐观了吗?我仔细看了一下论文。
SimCLR在无监督情况下top-1的accuracy是这么得到的:
1、backbone:ResNet-50(4x),即网络宽度是ResNet-50的4倍;
2、测试方式:linear evaluation protocol, where a linear classifier is trained on top of the frozen base network, and test accuracy is used as a proxy for representation quality,也就是说最后一层linear classifier其实是supervised learning训练得到的。
即媒体说的SimCLR可以媲美有监督的ResNet-50,有两个隐含条件:
1、网络参数更多;
2、在SimCLR无监督学习得到的网络之上使用有监督学习的方式训练了一个linear classifier。
SimCLR的效果当然很好,但是无监督跟有监督的差距还是蛮大的,情况没那么乐观。为了更直观地比较无监督和有监督,其实可以这样做:
1、使用相同网络;
2、直接用无监督学习得到的网络作为一个特征提取器,然后在验证集/测试集上通过检索的方式来获取类别,得到分类accuracy。
但是从特征提取器的角度来说,无监督学习的确取得了长足的进步,跟有监督学习的差距越来越小。
本节内容授权自知乎用户mileistone
https://zhuanlan.zhihu.com/p/107269105
SimCLR作者介绍
SimCLR一作是北邮毕业的Ting Chen,2019年3月获得加州大学洛杉矶分校计算机科学系的博士学位。

目前在Google Brain担任研究科学家,研究兴趣主要是深度学习和人工智能。
Ting Chen的个人主页:
http://web.cs.ucla.edu/~tingchen/

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675