
干货 :流式计算、数据处理及相关技术
在工业界,当我们提到实时数据机器学习时,常常可以听到如下讨论:
他们希望有一个模型,这个模型利用最近历史信息来进行预测分析。举一个天气的例子,如果最近几天都是晴天,那么未来几天极小概率会出现雨雪和低温天气
这个模型还需要是可更新的。当数据流经系统时,模型是可以随之进化升级。举个例子,随着业务规模的扩大,我们希望零售销售模型仍然保持准确。
流式计算的使用场景
01
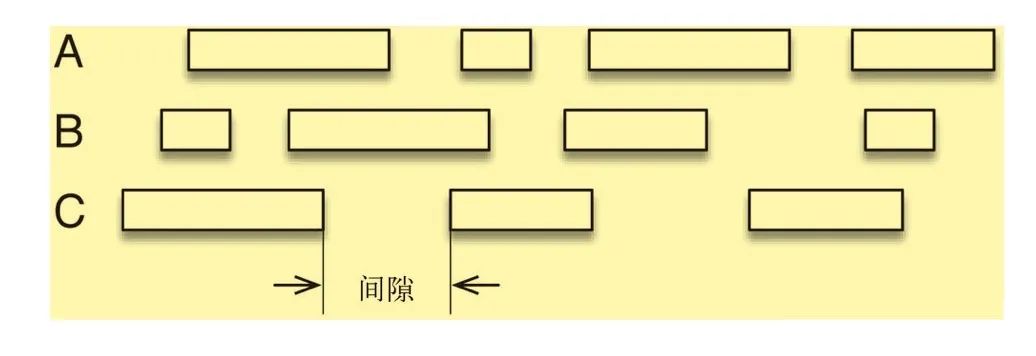
低延迟:近实时的数据处理能力
高吞吐:能处理大批量的数据
可以容错:在数据计算有误的情况下,可容忍错误,且可更正错误
流式处理框架
02
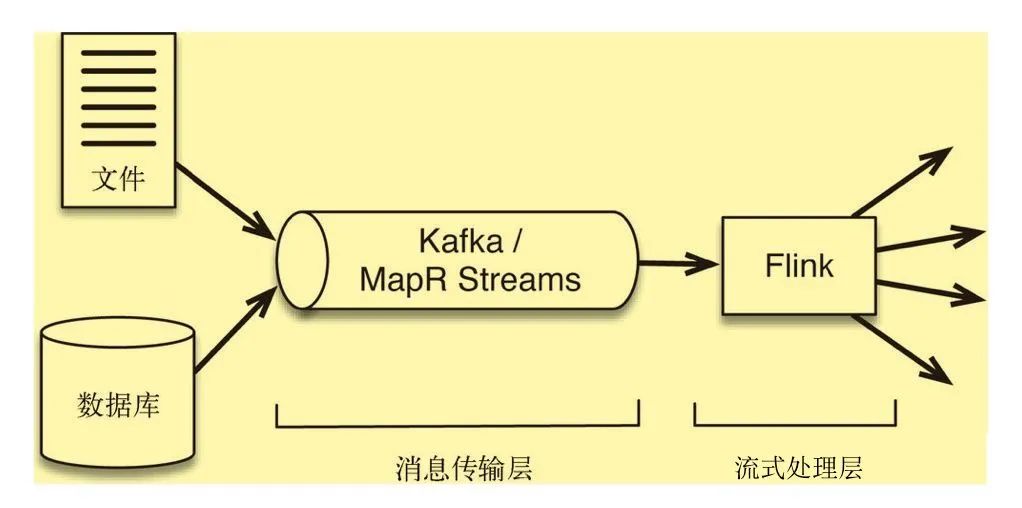
消息传输层的引入流处理层提供了以下支持:
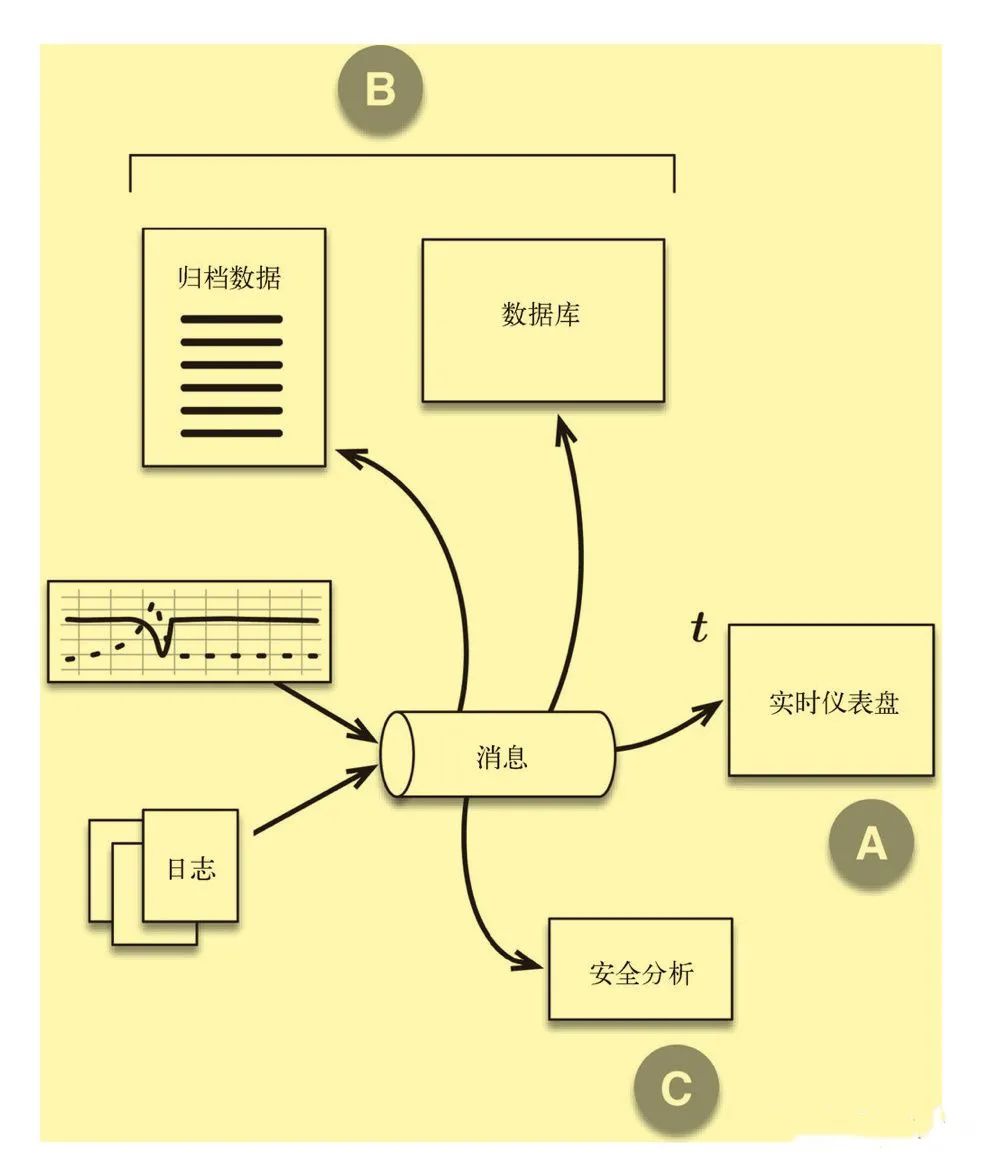
消息传输层的一个作用是作为流处理层上游的安全队列,它相当于缓冲区,可以将事件数据作为短期数据保留起来,以防数据处理过程发生中断
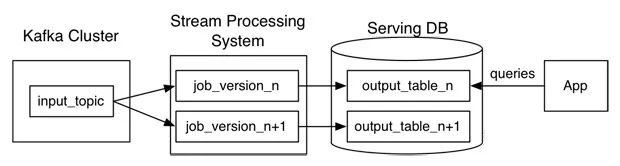
具有持久性的好处之一是消息可以重播。实现时间穿梭
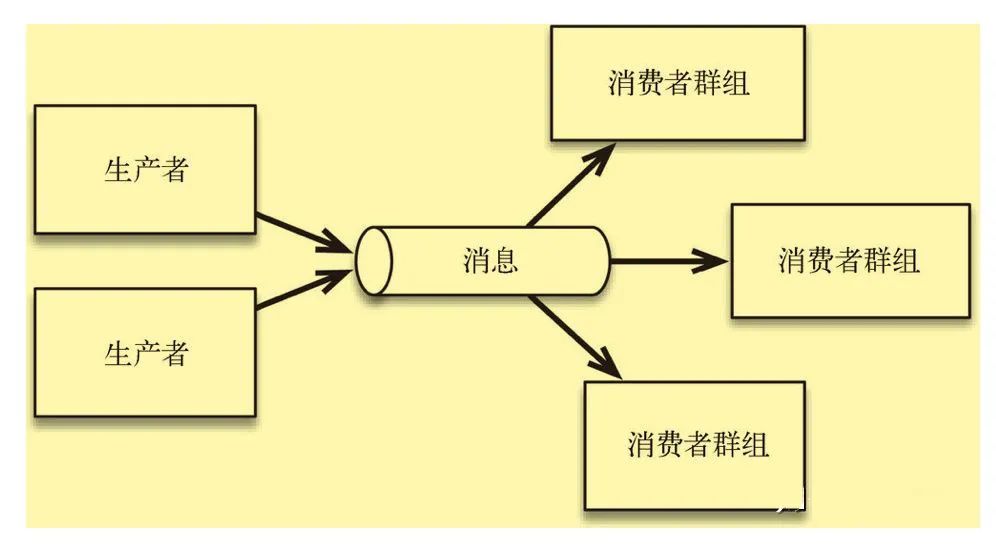
生产者和消费者解耦
Lambda架构
基于Lambda架构,实现了离线计算的精确性的同时,且获得了流式数据处理的实时性。但是,由于要开发同样逻辑的代码,开发、维护成本高

spark streaming
基于小批量进行数据处理
Flink
以上几种技术中,flink既可以实现低延迟、高吞吐,还可以实现容错。

Flink概况
03
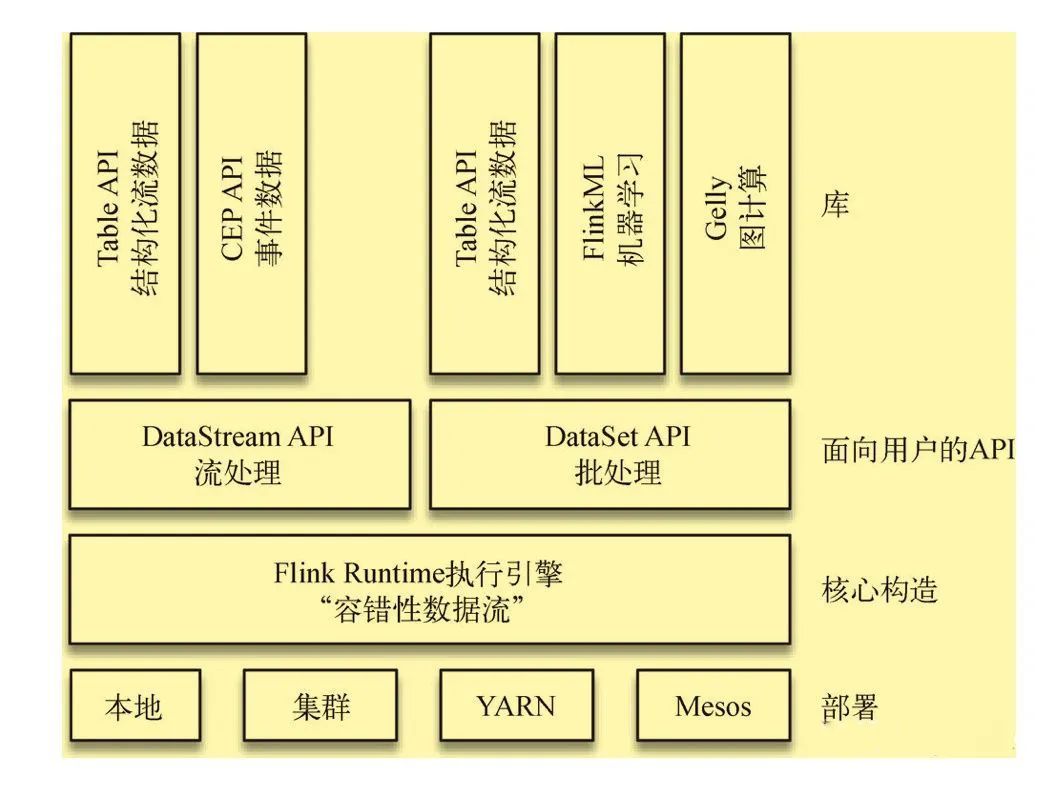
总体来说,Flink的主要特性:
符合产生数据的自然规律:支持流式数据处理
发生故障后仍保持准确:具体容错机制(exactly once)
及时给出所需结果:低延迟、实时性强
时间概念
事件时间:即事件实际发生的时间。更准确地说,每一个事件都有一个与它相关的时间戳,并且时间戳是数据记录的一部分(比如手机或者服务器的记录)。事件时间其实就是时间戳。处理时间,即事件被处理的时间。
处理时间:其实就是处理事件的机器所测量的时间
摄取时间:也叫作进入时间。它指的是事件进入流处理框架的时间

Flink允许用户根据所需的语义和对准确性的要求选择采用事件时间、处理时间或摄取时间定义窗口
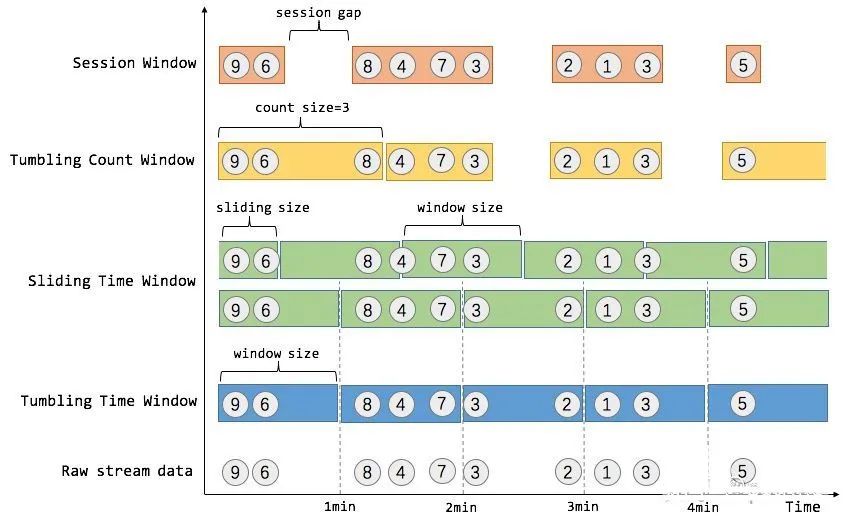
窗口
窗口是一种机制,它用于将许多事件按照时间或者其他特征分组,从而将每一组作为整体进行分析(比如求和)
时间穿梭
水印
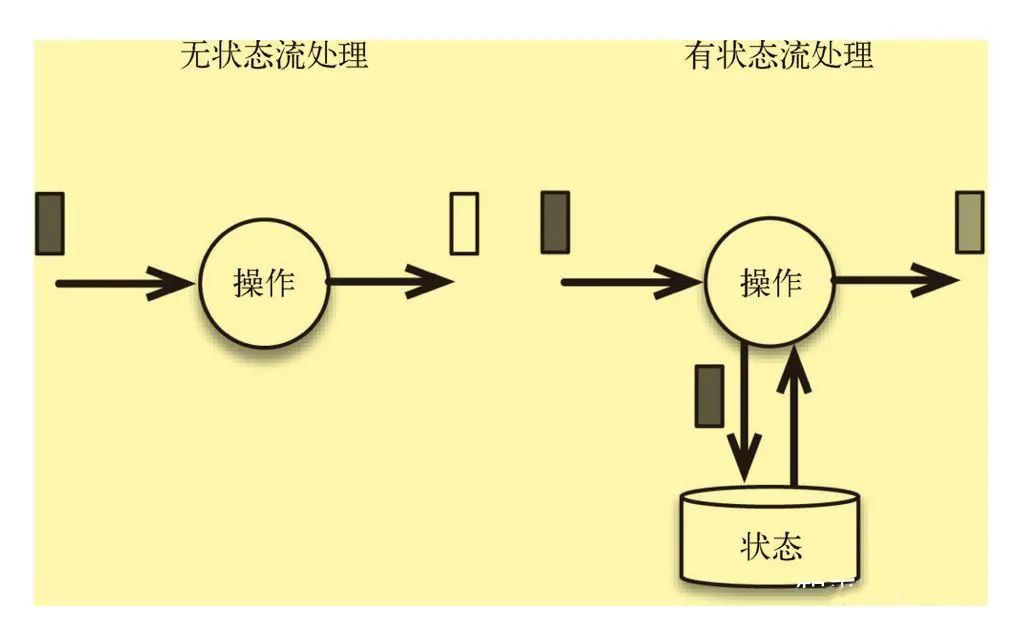
有状态的计算
无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应用程序从传感器接收温度读数,并在温度超过90度时发出警告。
有状态的计算则会基于多个事件输出结果。
数据处理容错及一致性保障
at most once:这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失
at least once:这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算
exactly once:这指的是系统保证在发生故障后得到的计数结果与正确值一致

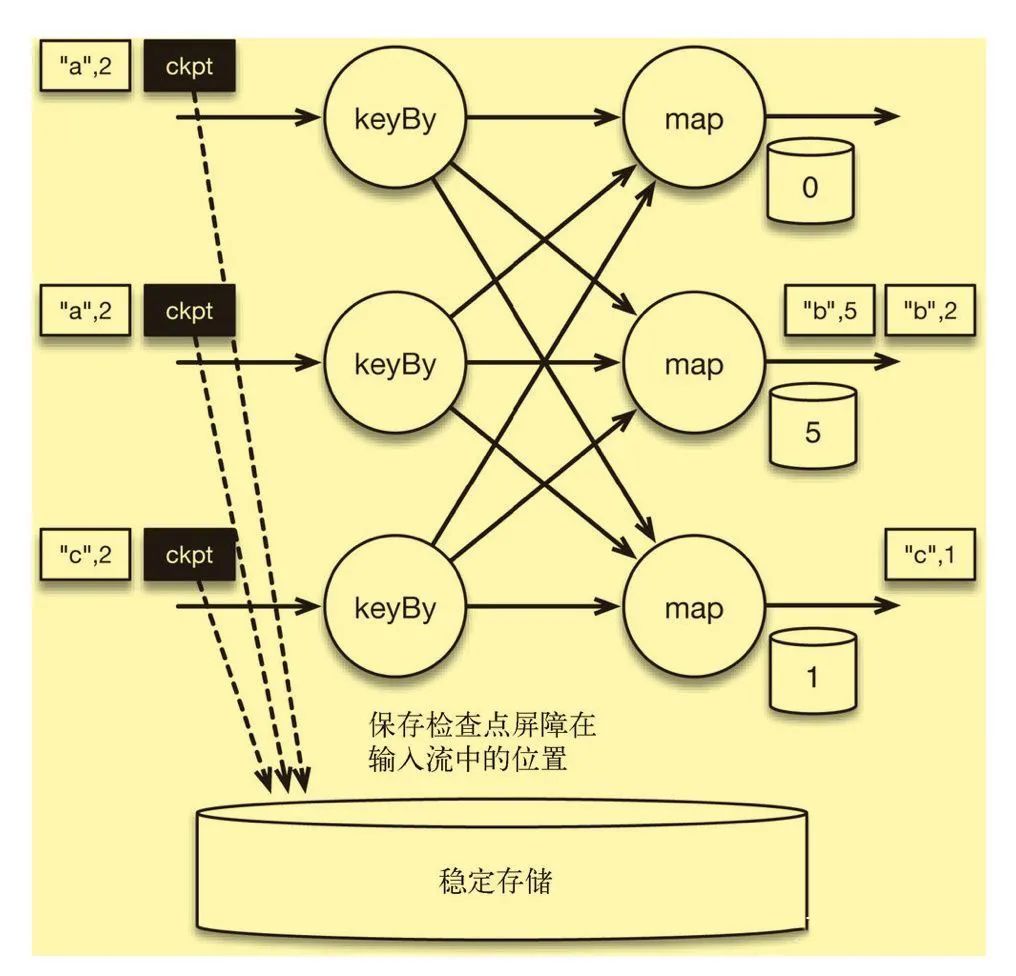

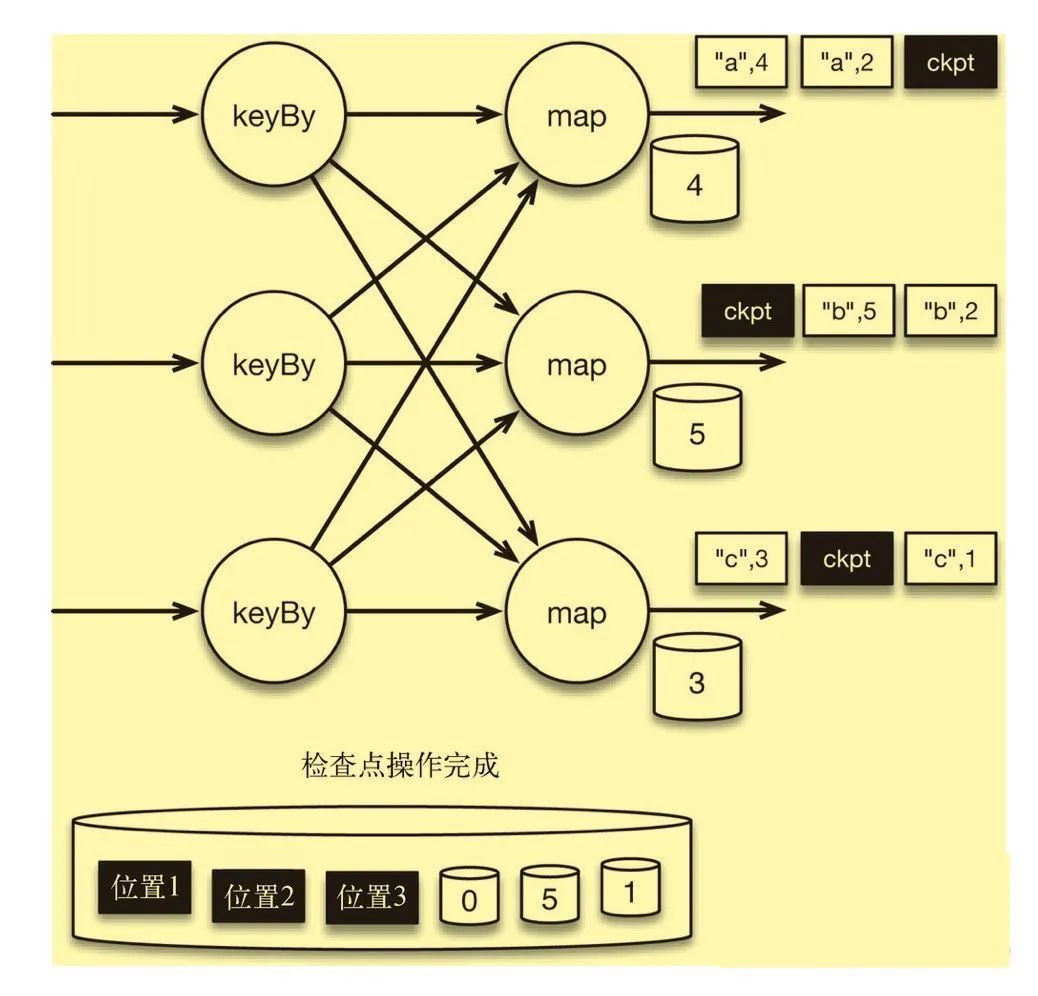
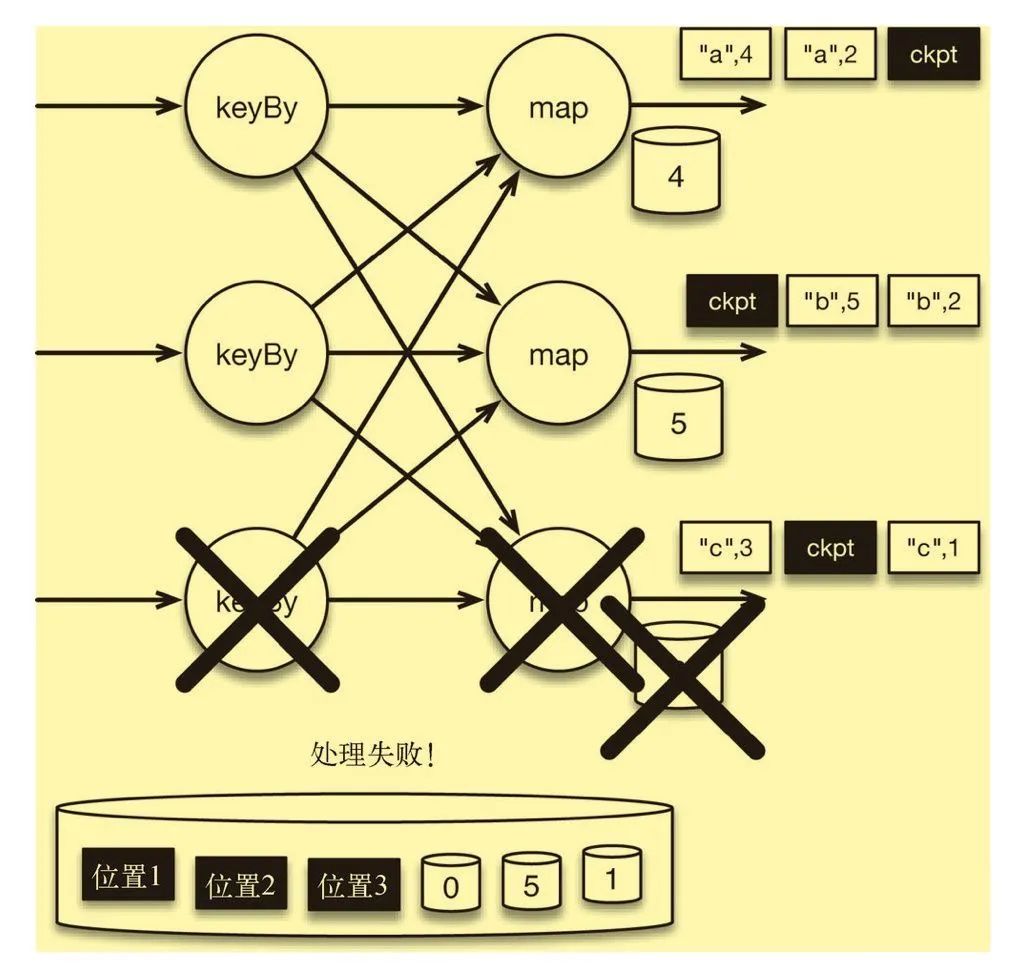
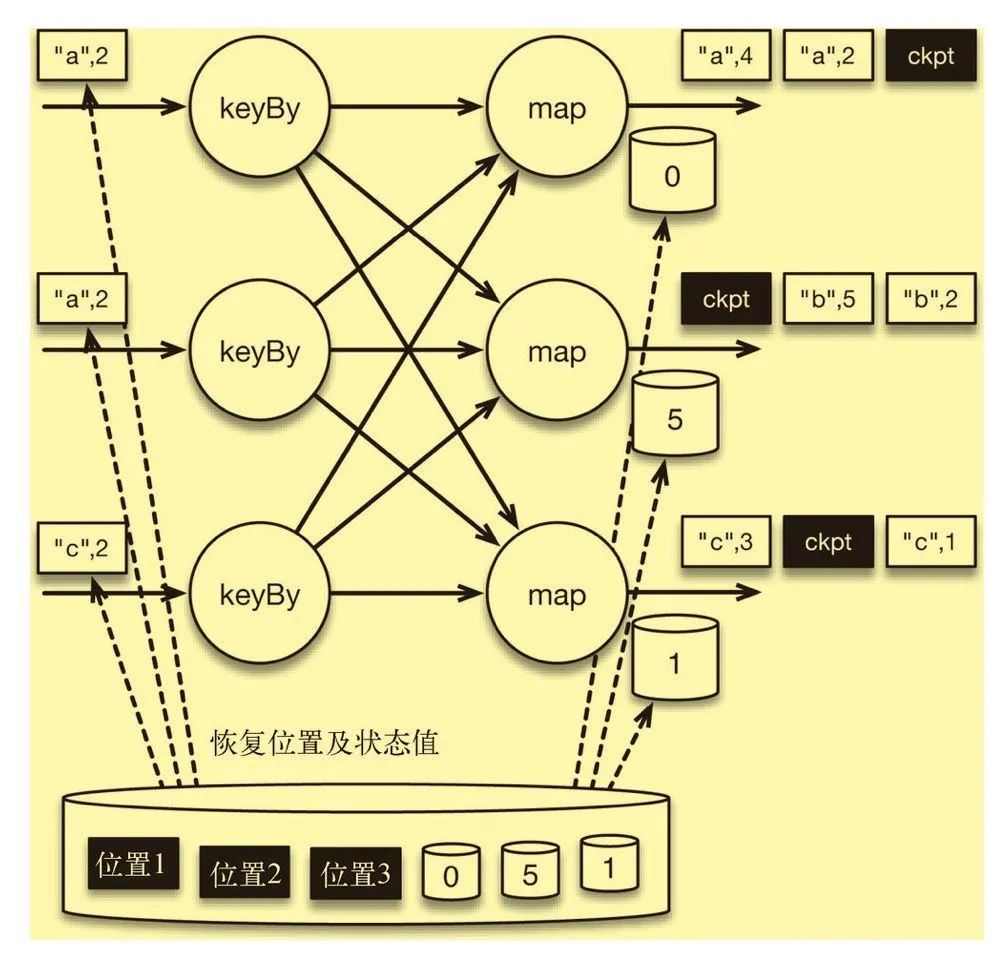
批处理

版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/


![徐莉芝潇洒是我本性 美是命中注定[来]](https://imgs.knowsafe.com:8087/img/aideep/2024/1/16/379aad45dac8d8dd10d58e7313dd6f73.jpg?w=250)



 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675