懒人福音!谷歌AI整理房间、收盘子、叠罗汉,样样拿手!

??新智元报道??
??新智元报道??
编辑:Q
【新智元导读】谷歌AI研究院的研究人员提出了 「Transporter Network」,用全新方式实现3D理解,可以让机械臂更好更快的进行操作。
重新排列物体(比如整理书架上的书籍,移动餐桌上的餐具,或者推一堆咖啡豆)是机械臂一项基本技能,它可以让机器人与我们多样化、非结构化的世界进行身体互动。
?
尽管对于人们来说很容易,但是对于具身机器学习系统(embodied machine learning systems)来说,完成这些任务仍然是一个开放的研究挑战,因为它需要高水平和低水平兼备的感知推理。例如,当堆叠一堆书时,你可以考虑书应该堆放在哪里、以何种顺序,同时确保书的边缘彼此对齐形成一堆整齐的书。
?

在机器学习的许多应用领域中,模型结构中的简单差异可以表现出大不相同的泛化特性。因此,人们可能会问,是否有某些深层网络结构支持重新排列问题的简单底层元素。
?
例如,卷积结构在计算机视觉中很常见,因为它具有平移不变性,即使图像发生移动也会产生相同的响应,而Transformer结构在语言处理中很常见,因为它们利用自注意力来捕捉长距离的上下文相关性。在机器人技术应用中,一个常见的结构是在学习模型中使用以对象为中心的表示,例如姿势、关键点或对象描述符( object descriptors ),但是这些表示需要额外的训练数据(通常是手动注释) ,并且很难描述复杂的场景,例如变形物(例如 playdough)、液体(蜂蜜)或成堆的东西(剁洋葱)。
?
最近,谷歌AI的研究人员提出了 Transporter Network,这是一个用于学习基于视觉的重排任务的简单模型结构。
?
Transporter Network 使用一种新颖的方法来实现3D 空间理解,避免了依赖于以对象为中心的表示,使得它们对基于视觉的操作更加通用,但是比基准的端到端的替代方法更有效率。因此,它适合快速和实用的训练真正的机器人。同时研究人员还发布了一个与 Ravens 一起的 Transporter Nets 的开源实现,这是基于十项视觉的操作任务的新的模拟基准套件。
?
Transporter Network:为机器操作重新排列视觉世界
Transporter Networks 背后的关键思想是:人们可以将重新排列问题表述为学习如何移动一块三维空间。
?
3D 空间并不依赖于对象的明确定义(这一定会在捕捉所有边缘情况方面遇到困难) ,而是对可以作为被重新排列的原子单元(atomic units)的更广泛的定义,它可以广泛地包含一个对象、一个对象的一部分或多个对象等。
?
Transporter Nets 通过捕捉3D视觉世界的深层表征来利用这种结构,然后将其部分覆盖在自身上,以想象各种可能的3D空间重排。然后,它选择在训练过程中看到的最匹配的重新排列方式(如来自专家演示的结果) ,并使用它们来参数化机器人的动作。
?
这个方式允许 Transporter Nets 泛化到看不见的对象,并使它们能够更好地利用数据中的几何对称性,以便它们能够外推到新的场景配置当中去。Transporter Nets 适用于机器人操作的各种各样的重新排列任务,扩展了早期的模型,比如基于启示(affordance-based)的操作和 TossingBot,它们只关注抓取和抛掷。
?
Transporter Nets 捕捉了视觉世界的深层表征,然后将其部分覆盖在自身上,想象各种可能的3D空间重组,以找到最好的一个,并通知机器人的行动。
Ravens Benchmark
为了在一致的环境中评估 Transporter Nets 的性能,以便与基线和消融进行公平的比较,谷歌研究人员开发了 Ravens,这是一个由10个基于视觉的重排任务组成的基准测试套件。
?
Ravens 提供了一个内置随机oracle的 Gym API 来评估模仿学习方法的样本效率。Ravens 避免了不能转化为实际设置的假设: 观察数据只包含 RGB-D 图像和摄像机参数; 动作是终端执行器姿态(与逆运动学转换到关节位置)。
?
对这10个任务的实验表明,Transporter Nets 比其他端到端方法的效率高出数量级的区别,并且只需100个演示就可以在许多任务上获得90% 以上的成功率,而基线方法很难用同样数量的数据进行泛化。
?
在实践中,这使得收集足够的演示成为在真实机器人上训练这些模型的一个更可行的选择。
?
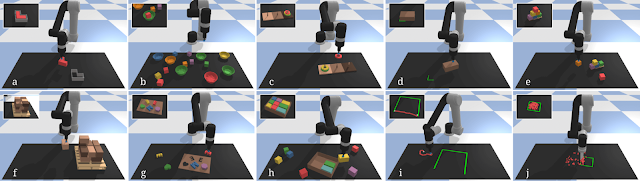
Highlights
这里给出10个例子演示,Transporter Nets 可以学习挑选和放置任务,如堆叠盘子;多模态任务,如对齐任何一个角落的一个盒子上的桌面标记,或建立一个金字塔的块。
?

?
通过利用闭环的视觉反馈,Transporter Nets 有能力学习各种多步的连续任务,并进行适度的演示: 例如汉诺塔的移动磁盘,或组装在训练期间没有看到的新物体的成套工具等。
?
这些任务具有相当的“长视野”,这意味着为了解决任务,模型必须正确地排列许多单个选择的顺序,同时策略也倾向于学习紧急恢复行为(emergent recovery behaviors)。
?

?
关于这些结果的一个令人惊讶的事情是,除了感知之外,模型还开始学习类似于高级计划的行为。例如,要解决汉诺塔问题,模型必须选择磁盘移动的下一步,这需要基于当前可见磁盘及其位置识别状态。这些行为表明,对于所有内置的不变性,模型可以将其能力集中于学习操作中更高级的模式。
?
Transporter Nets 也可以学习使用任何由两个终端执行器定义的运动原语的任务,例如将成堆的小物体推入一个目标设置中,或者重新配置一个可变形的绳子来连接一个三边形的两个端点。这表明刚性空间位移可以作为非刚性位移的有用前提。
?

?
结论
Transporter Nets 为基于视觉的操作学习提供了一种很有前途的方法,但也存在一定的局限性。例如,它们可能会受到噪声3D数据的影响,其次,只演示了稀疏的基于方向点的控制与运动原语,目前还不清楚如何超越空间行动空间的力量或基于扭矩的动作来扩展它们。
?
但是总的来说,目前研究人员对这个方向的工作感到兴奋,希望它能为讨论过的应用程序之外的扩展提供灵感。
?
?
详细讲解可以观看视频:
https://www.youtube.com/watch?v=8afHfReCfPo&feature=emb_logo
参考链接:
https://ai.googleblog.com/


关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 中共中央政治局召开会议 7904116
- 2 日本记者街头采访找不到中国游客 7809750
- 3 课本上明太祖画像换了 7714235
- 4 8.85亿人次受益后 医保又出实招 7618212
- 5 2分钟烧到100℃?警惕用电“雷区” 7520531
- 6 盒马承认生产草莓蛋糕出问题 7427401
- 7 净网:网民造谣汽车造成8杀被查处 7332934
- 8 苟仲文受贿2.36亿余元一审被判死缓 7233077
- 9 1岁多女童吊环上“开挂” 7142590
- 10 寒潮来袭 “速冻”模式如何应对 7042766