
文本对抗综述(二)
本篇文章由ChaMd5安全团队AI小组投稿
Word-level Attack
单词级别的攻击最早作品是在2016年发表在MILCOM会议上的文章,papernot等人通过研究对抗输入序列的递归神经网络处理顺序数据,对对抗机器学习领域做出了贡献,作者通过制造对抗序列可以误导实现分类和顺序递归神经网络模型。鉴于中引入了对于深度学习分类器的攻击分类,主要方法为通过制作对抗样本使得图片的分到指定的类别或者是与原始类别不同的分离。在上述的攻击手段中,主要使用的方法为快速梯度标志方法(Fast Gradient Sign Method)和前向求导法(Forward Derivative),但是这两种方法针对的都是为了解决图像分类问题的模型。
由于在图像分类模型中的输入都是线性可微的,而文本大多都是离散的,因此作者在本文中提出一种新的对抗性样本,可以用于映射以非线性或不可微的方式对输入序列进行预处理,并且最后输入分类或者是序列的模型。这里作者使用的模型是RNN模型,并且制作了一种旨在误导RNN模型差生错误输出的对抗性序列,利用计算图展开技术,并且证明了正向导数可以适用于具有循环计算图的神经网络。


快速梯度标志法(FGSM)?近似方程(8)中的问题,方法是将模型的代价函数围绕其输入线性化,并通过代价函数相对于输入本身的梯度选择一个扰动。可以通过遵循训练过程中通常用于反向传播的步骤来计算此梯度,但是与训练过程中通常情况不同,该梯度不是计算模型参数的梯度(目的是减少预测误差),而是 针对输入进行计算。这就产生了以下对抗性样本的公式:

前向导数(Forward Derivative)是制造对抗样本的另一种手段,该方法的设计考虑了对选定的对抗目标中的样本进行错误分类的对抗威胁模型,并且该技术还可以用于实现与原始样本类别不同的任何目标类别中较弱的错误分类目标。可将前向导数定义为模型的雅可比行列式:


本文的不足之处在于可能会生成虽然能够迷惑RNN但是语意不通的句子。比如原句为 “I wouldn’t rent this one even on dollar rental night.”更改为 “Excellent wouldn’t rent this one even on dollar rental night.”
随后liang等人根据上述不足进行了补足,并设计了三种扰动策略分别是插入、修改和删除,并引入了自然语言水印技术将给定为本生成对抗样本,并非简单的将扰动和原始输入重叠。
作者使用了当时具有代表性的文本分类器DNN,一个是字符级模型,另一个是单词级的模型,之后分别从白盒以及黑盒攻击角度分别介绍不同的攻击方式。
在白盒方式下,作者指出可以使用FGSM方式制作生成文本对抗样本,也可以使用损失梯度来制作对抗样本。但是这些方式并不能直接适用于文本,原因如下图中(b)

Figure 1: FGSM生成的对抗样本
原始的句子是对一辆摩托车的简短描述,这个时候DNN模型可以将该句子争取归类为交通工具,虽然通过FSGM方式可以将预测更改为Company,但是新的文本图中(b)对人类来说都已经不可读了,虽然也可以使用一些梯度值最高的字符,但是生成的文本仍然是不可读的,如(c)中所示,所以需要更复杂的策略来为文本数据制作对抗样本。这里作者指出在百倍场景下应该先根据其损失梯度识别对分类很重要的文本项,然后利用这些项以及自然语言水印技术来决定插入、修改或删除什么、插入哪里以及如何修改。
作者进行白盒攻击的最主要在于利用损失函数来识别对对分类有重要贡献的文本项,以字符级模型为例。

之后把维度最高最大的字符称为热字符,随后通过简单扫描就可以识别出包含三个以上热字符的热点词,如果所有相邻的词都是热点词,则将它们组合成一个热点短语,未组合的热点词也将被视为热点短语。
最后,对于所有的训练样本,将之前获得的热点短语按照样本的标签收集在一起。从这些短语中,我们确定了最常用的短语,称为热训练短语(Hot Training Phrases )。以Building类为例,下图展示了它的前10个htps。单词级DNN的HTPs可以用类似的方法获得,只是例子中热短语是通过寻找具有最大最大梯度的词向量直接识别的。
但是HTPs只指出了插入什么单词,但是插入、移除以及修改的位置仍然不清楚,但是这类信息类似于识别htp,在给定文本样本的情况下,仍然采用反向传播算法来定位对当前分类有重要贡献的热短语,并将这些短语识别为热样本短语(Hot Sample Phrases (HSPs).HSP用来表示在哪里进行操纵,以制造出有效的对抗样本。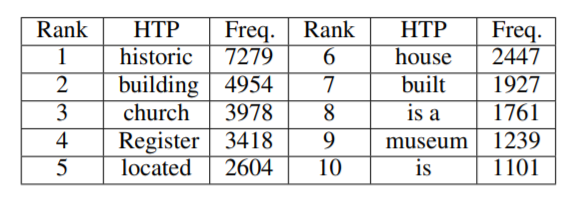
Figure 2: Building类的前十个HTPs
作者可以利用上述方式对抗样本的制作并且可以控制样本选择任意感兴趣的一个类作为目标类进行攻击,而不是任意输出不属于原始类的类别。
插入策略对于一个给定的文本t,如果F(t)=c,则该策略的目标是在t中插入一些新的文本项(攻击有效载荷),这可以有效地提升t对感兴趣的类c'的分类置信度(c′≠c),并且相对应的可以降低对原始类别c的置信度。如下图插入historic后可以将原本属于Company的类别分到Building类别。

Figure 3: 插入一个HTP后又99.7%的Company类别被分到Building
因为在实践中经常需要多次插入,但是直接在文本中插入多个htp可能会损害文本的实用性和可读性。为了解决这一问题,作者引入了自然语言水印技术。该技术可以通过语义或句法操作,比如用同义词或拼写错误替换单词,偷偷地将所有权水印嵌入到纯文本中,作者借用了这一思路制作对抗样本。作者还扩展了插入预设和语义空白短语的思想,以扰乱目标文本样本,简单说来就是在文本中通过插入一句携带有HTPs的事实或者伪造的事实,在每句语义和原始文本主题不变的情况下使得样本分类错误。
修改策略是通过略微操控输入中的一些HTPs来影响模型输出,主要方法为增加损失函数J(F,t,c),同时减少损失函数J(F,t,c),并且为了在不引起人类观察者注意,修改的方向应该是沿着损失函数J(F,t,c)的梯度。主要的修改方式有两种,第一种是用常见的拼写错误替换正确的词汇film改成flim,第二种是将单词中的一些字符改编成视觉上外观相似的错误拼写,比如将小写字母“i”改成数字“1”。
删除策略主要是删除单词,但是该方式只能在很大程度上降低分到原始类别的置信度但是预测类别不会发生变化。
而黑盒攻击的主要方式为使用白盒中的策略进行fuzzing查找漏洞,但是与白盒策略不同的是,黑盒的时候并不知道训练的数据库,于是采用了对一段话中每个单词都挨个遮挡的方式制作出来可以用于fuzzing的种子文件,之后挨个进行测试比较原始测试样本和种子文件的分类结果,通过对比遮住每一个单词造成的偏差找到HTPs,偏差越大,对应的词对模型的正确分类重要度越高,接着找出来造成偏差最大的单词确定为种子文件的热敏感因子,最后找出热点单词,然后利用上述做法制作对抗样本。
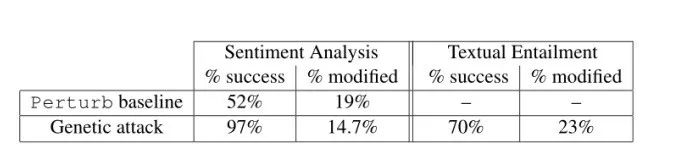
关于实现情感分类的NLP模型,Alzantot等人也通过使用黑盒攻击方式利用基于群体的优化算法来生成语义和语法上相似的对抗样本,利用这些样本来攻击训练良好的情感分析和文本蕴涵模型的成功率分别为97%和70%。
作者设计了一种构造对抗样本的算法,旨在最大程度地减少原始示例和对抗示例之间的修饰词数量,但仅执行保留与原始和句法连贯语义相似性的修饰。为了实现这些目标,我们开发了一种攻击算法,而不是依靠基于梯度的优化,而是通过遗传算法来利用基于种群的无梯度优化。使用无梯度优化的另一个好处是可以在黑盒中使用,依赖于梯度的算法在这种情况下不适用,因为它们依赖于模型是可区分的并且内部是可访问的,也就是仅限于白盒攻击。基于以上原因,作者选择使用遗传算法来之制作对抗样本。
遗传算法的灵感来自自然选择的过程,将一系列候选解决方案迭代发展为更好的解决方案。在遗传算法中的每次迭代的总体称为一代,在每一代中,使用适应度函数评估人口成员的质量,更有可能选择“更合适”的方案来培育下一代。下一代则是是通过交叉和突变相结合而产生的,交叉是获取多个父解决方案并从中生成子解决方案的过程,它类似于繁殖和生物交叉;突变是为了增加种群成员的多样性并更好地探索搜索空间。众所周知,遗传算法在解决组合优化问题方面表现出色,由于采用了大量的候选解,这些算法可以找到成功的对抗性示例,且修饰较少。
该算法应用在文本对抗主要为子程序扰动(Perturb Subroutine)和过程优化(Optimization Procedure)两个步骤。

为了挑选最合适的替换词,扰动应该遵守如下步骤:

作者在上面的步骤中也排除了常用冠词或者介词被替换的可能性。
过程优化优化算法首先通过调用Perturb子程序S次以创建一组对原始句子的不同修饰来创建大小为S的初代P0,然后,计算当前世代中每个种群成员的适应度,作为作为查询被攻击模型函数f得到的target标签预测概率。如果一个种群成员的预测标签与target标签相等,则优化完成。否则,将以与它们的适应度值成正比的概率随机采样当前一代的成对种群成员。然后,通过使用均匀分布从两个父句中独立采样,从一对父句中合成一个新的子句。最后,将Perturb子程序应用于结果子代。
具体算法Alogrithm 1所示:

由于在单词级别的攻击中会出现很多语义不同的句子,zhang等人指出即使是遗传算法的攻击方式,生成的对抗样本也免不了出现语句不流畅的现象,而且由于抛弃了梯度,这种方式的对抗样本制作也是低效的。于是便从文本流利度的角度考虑对抗样本的制作。在zhang等人的论文中,提出了一种Metropolis-Hastings attack(MHA)算法,且MHA算法是基于M-H抽样的算法。作者在文中提出了MHA算法的两种不同攻击方式,即黑盒MHA攻击(b-MHA)和白盒MHA攻击(W-MHA)。与以往使用M-H的语言生成模型相比,b-MHA的平稳分布具有一个语言模型项和一个对抗性攻击项,这两个术语使对抗性例子的生成流畅有效,同时w-MHA在提案分配中加入了对抗性梯度,以加速对抗性例子的生成。
作者指出,M-H算法是一种经典的马尔可夫链蒙特卡罗采样方法。给定平稳分布(π(x))和跃迁建议,M-H能够从π(x)生成理想的例子。具体来说,在每次迭代中,基于提议分布(g(x‘|x))做出从x跳到x’的建议,该建议被接受的概率为:
一旦被接受,该算法就会跳到x'否则就保持在x。
作者选择进行攻击的模型依然是文本分类器,在黑盒攻击(b-MHA)中,作者希望对抗样本能够满足以下三个要求:(a)流畅阅读;(b)能够愚弄该分类器;(c)尽可能少地调用分类器。
固定分布?为了能够满足上述要求,设计如下的平稳分布:

过渡提议?共有三个但自己的转换操作,分别是替换,插入和删除。
遍历索引?用于选择要对其执行操作的单词,假设MHA在第t个建议中选择第i个单词wi,然后再第t+1个建议中选择单词为:




同时作者表示,白盒攻击与黑盒攻击之间的唯一区别在于与预选器。与黑盒攻击不同的是,白盒攻击的预选器将梯度引入预选分数。

除此之外,文本分类模型的对抗攻击还有基于概率加权词显着性(PWWS)的贪婪算法,且PWWS会最大程度地降低分类准确性,并保持非常低的单词替换率,作者的主要攻击思路如下:
给定一个经过训练的NLP文本分类器F,它可以根据最大后验概率,正确地将原始输入文本x分类为标签ytrue,如下


为了使干扰小到人类无法察觉,对抗样本需要满足词汇、语法和语义方面的限制。词法约束要求输入样本中的正确单词不能被更改为常见的拼写错误单词,因为在分类器输入之前进行拼写检查可以很容易地消除这种干扰。此外,被扰动的样本必须语法正确,且根据语义约束的要求,对原始样本的修改不应导致语义的显著变化。
根据上述约束,我们用同义词在输入文本中放置单词,用相似的命名实体(NEs)替换原始的NEs来生成对抗样本。NE是指在样本文本中具有特定含义的实体,如人名、位置、组织或专有名词等。用一个相似的NE替换原始文本中的一个NE会在语义上产生轻微的变化,但不会引起词汇或语法上的变化。因此假设当前输入样本属于ytrue类,且字典Dytrue?D包含所有出现在文本中且属于类别ytrue的NEs,则我们可以在补集字典D?Dytrue中使用最常见的命名实体NEadv作为替代词,此外替代词NEadv必须与原始NE的类型一致。
作者介绍而PWWS的单词替换策略如下,对于x中的每个单词wi,使用WordNet为其构建一个同义词集Li?D,该同义词集中包含wi的所有同义词。如果wi是一个命名实体(NE),且NEadv与Li具有类型一致的wi,那么每一个wi′∈Li都是wi的候选词,接着从Li中挑选任意一个wi′来代替一个欲替换词wi?,其中欲替换词wi?在替换后可引起分类概率发生最大变化。替代词的选择方式R(wi,Li)如下


此外,在文本分类任务中,输入样本中的每个单词可能对最终分类产生不同程度的影响。因此作者将单词显著性加入到算法中来确定替换顺序。单词显著性是指当一个单词被设置为未知(即在词汇表外)时,分类器输出概率的变化程度。单词的显著性S(x,wi)计算方法如下

这里的?(S(x))i是softmax函数

PWWS算法的实现如下Algorithm 1

Figure 5: Algorithm 1
除了对文本分类模型的攻击以外,ACL会议上也有关于单词级别样本攻击的其他方向文章,主要攻击的模型也比原来有所变化,目标模型从原本的文本分类任务转向神经网络模型推理(NLI)系统,Glockner等人发表了这个方向的论文,主要贡献在于创建了一个新的NLI测试集,且利用SNLI数据集训练的系统在该测试集上结果明显不理想。
SNLI数据集是Stanford大学创建的自然语言推理(SNLI)数据集,全称The Stanford Natural Language Inference (SNLI) Corpus,是专门训练实现自然语言推理功能的模型,这一项任务与识别前提句子是否与假设句子存在蕴含、中立或者矛盾关系。作者创建的NLI测试其中包含了捕捉各种词汇知识的示例,比如说香槟是一种酒(上下义关系),萨克斯和电吉他是不同的乐器(上下义关系)。举例如下图所示

Figure 6: 新的NLI测试集示例
为了分离词汇知识方面,作者构建的例子只包含出现在训练集和预训练嵌入中的单词,并且与训练集中的句子相差一个单词。新测试集的性能在不同的系统中要差得多,这表明SNLI测试集本身不足以衡量语言理解能力。作者在构建NLI数据集时,所有的前提均取自SNLI训练姐,对于每个前提,作者通过用不同的词替换前提中的一个词来产生几个假设,也会使用一些由多个单词的名词短语(“electric guitar”)来产生假设,并且会删除限定词和介词。作者只关注生成的有蕴含或者矛盾关系的例子,而中性的例子仅仅作为副产品存在。蕴含示例是通过用同义词或上位词替换一个单词而生成的,而矛盾示例是通过用互斥的同形异义词和反义词替换单词而生成的,生成的方式具体如下。
替换词?首先作者使用在线英语学习资源收集了替换单词,新引入的单词都存在于SNLI训练集中:从单个训练示例(“Portugal”)到多次出现的示例(“man”)。这些单词也可以在预先训练的嵌入词汇表中找到。这种约束的目标是隔离词汇知识方面,并评估模型对已知单词进行归纳和新推理的能力。之后替换词也被分为如下图所示的不同的主题类别,在这几个类别中,作者应用了附加处理,以确保示例确实是互斥的、局部相似的和在上下文中可以互换的。作者使用GloVe将词性相同且余弦相似度评分高于阈值的WordNet反义词纳入其中。在国籍和国家方面,关注的是地理上相关的国家(Japan、 China)或文化上相关的国家(Argentina、Spain)。
句子对为了避免引入训练数据中不存在的新信息,作者从包含在列表中的单词的SNLI训练集中采样前提,并通过替换所选单词生成假设,在这过程中可能会产生一些不合语法或毫无意义的句子,例如,在讨论迈克尔·乔丹(Michael Jordan)的句子中,用Syria代替Jordan。为了避免出现这种情况,作者使用维基百科的bigrams4来抛弃那些被替换的单词只出现了少于10次的bigram的句子。
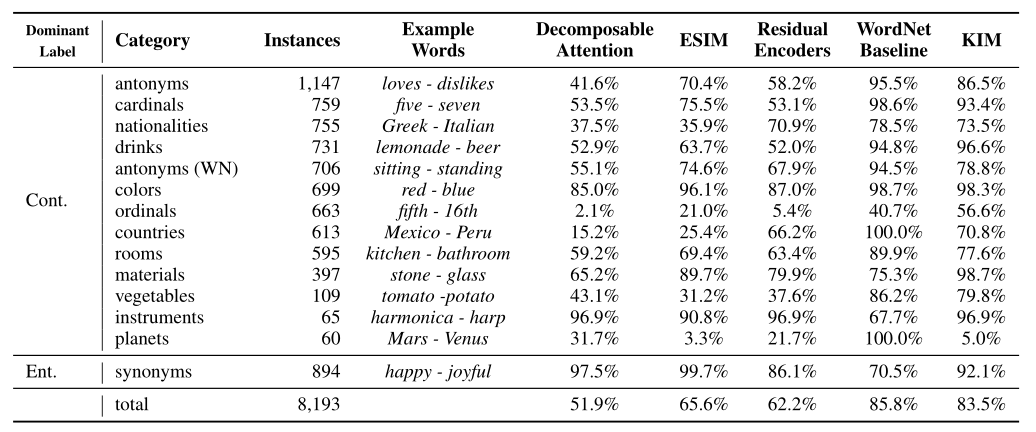
Figure 7: 每个模型实现的实例数量和每种主题类别的准确性
作者使用了众包的方式手工验证自动构建的示例的正确性,将测试集命名为BreakingNLI
之后通过一系列证明了尽管测试集的结构比SNLI简单得多,并且没有引入新的词汇,但是最新的系统在其上的表现很差,表明它们的泛化能力有限。该测试集可在将来用于评估NLI系统的词汇推断能力,并弄清其他性能非常相似的系统的性能。
除了文本分类器的样本对抗攻击以外,Cheng等人对神经机器翻译(NMT)也进行了样本对抗攻击。对于NMT模型来说,扰动主要来自于两个来源:1.注释中的自然噪声,2.攻击模型产生的人为偏差,作者在论文中不区分扰动的来源。作者提出了一种基于梯度的算法AdvGen,NMT模型中干净输入的最终翻译损失为指导来构造对抗例子。AdvGen应用于编码和解码阶段:1.通过生成对训练损失敏感的敌对源输入来攻击NMT模型;2.利用对抗性目标输入对NMT模型进行防御,以减少对抗性源输入的预测误差。
作者的贡献有三方面:
提出了一种用于非机器翻译对抗例生成的白盒方法。我们的方法是一种以翻译损失为指导的基于梯度的方法。
我们提出了一种新的方法来提高具有双重对抗性输入的NMT鲁棒性。编码器中的对抗性输入的目标是攻击NMT模型,而解码器中的输入则能够防御预测中的错误。 在两个常见的翻译基准测试上,作者的方法比以前最先进的transformer模型取得了显著的改进。

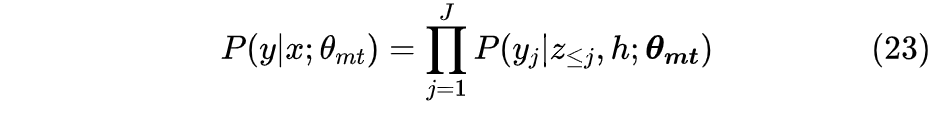
这里的θmt为一组模型的参数,z≤j是部分目标输入,则训练损失S定义为:

形式上可以通过求解一个优化问题,对一个训练样本(x,y)生成一组对抗样本Z(x,y)。
先前的论文中给出了对抗样本的生成等式,如下

此处J(?)用于衡量样本具有对抗性的可能性,是用于表示对抗性示例x′输出最可能的目标类别y′(y1≠y)的函数。而R(x′,x)则表示对扰动的不敏感程度。
给定一个句子对(x,y)带入上式子,可以得到等式

这里的gxi是梯度向量,x∈νx是源语言的词汇表,sum(?,?)表示计算两个向量的余弦相似度函数。接着,令Q(xi,x)∈R|V|表示句子x的第一个单词的似然度,定义Vxi=top_n(Q(xi,x))为Q(xi,x)前n个得分中n个最有可能的单词集合。
这里给出AdvGen函数的伪代码,其中的Eq.(5)为等式(12),该算法利用输入语句s生成对抗语句,其中Q为相似度函数,Dpos表示单词样本的分布,L指的是翻译损失。

Figure 8: Algorithm 1
最后通过该算法生成对抗样本实现对NMT的白盒攻击。
除此之外Huang等人引入了一种强化学习的新范式,并在其环境中使用一个鉴别器作为终端信号,进一步约束语义来研究生成对抗例子来研究攻击NMT模型的问题。该范式学习在标记级别上应用离散扰动,以实现直接的平移度量退化。实验表明,该方法不仅实现了语义约束的对抗性例子,而且对机器翻译产生了有效的攻击。
上述的文本对抗方式一般都是采用了启发式规则修改单词字符的方式,或者是用同义词替换单词等,但在于在干扰率、攻击成功率以及语法正确性和语义一致性等方面仍然有很大的改进空间。因此li等人基于使用Bert攻击Bert的想法,通过使用原始的Bert模型制造对抗样本来愚弄经过了微调的Bert模型。
具体方法包括以下两个步骤:
为目标模型找到容易遭受攻击的单词(vulnerable word) 使用语义和语法相似的的那次替换这个易受攻击的词
最易受攻击的词是帮助目标模型作出判断的关键词,再找到了这些词之后,使用隐蔽语言模型(masked language model)基于该模型预测出来的Top-k词汇预测产生干扰。
寻找最易受攻击词汇在黑盒场景下,作者首先选择序列中对最终输出的logistics有重要影响的单词。令S=[w0,...,wi,...]表示输入的语句,oy(S)表示目标模型为正确标签y输出的logistics值,Iwi为单词wi对输出的重要度,并定义Iwi为
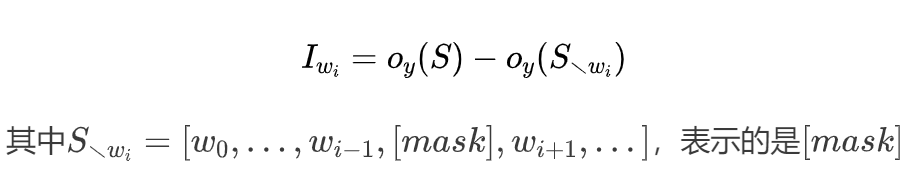
替换了wi后的句子。之后根据Iwi对所有单词的分数进行降序排名后创建单词列表L,取重要单词中的?%用来扰动。上述过程可以使用语义一致的扰动替换这些脆弱的单词。
通过Bert替换单词获得了L之后,便可以通过迭代的方式逐个替换L中的单词,一次找到可能误导目标模型的扰动。先前的方式一般是采用人工手动,为了确保生成的示例在语义上与原始示例一致且语法规则正确,并且每次替换一个单词时,都会使用传统的语言模型对添加了扰动后生成的句子进行评分。
由于上述生成替换策略并不需要了解替换位置的上下文,因此在流畅性控制和语义一致性方面不足,更重要的是耗时巨大,因此为了克服以上的上述问题,作者使用Bert模型进行此替换。Masked Language Model可以保证生成的句子相对流畅并且语法正确,还可以保留大部分语义信息,这些语义信息也可以人为确认,并且这种方式也优于简单的同义词替换。并且上下文扰动生成器(contextualized perturbation generator)不需要运行额外的DNN为句子评分,耗时部分仅仅在于访问目标模型,因此十分高效。
替换策略如图所示

Figure 9: 替换策略
首先给定要替换的单词w,之后作者应用Bert模型来预测与w相似但是可能误导目标模型的单词,以原始序列作为输出且不会掩盖w,这样可以生成更语义一致的合适替代单词。
因为Bert使用字节对编码(Bytes-Pair-Encoding)将序列S=[w0,...,wi...]标记为子词(subword)H=[h0,h1,h2,...],这里需要将选择的词与Bert中相应的子词对齐。假设M表示Bert模型,将H输入M中得到输出预测P=M(H),这里不适用argmax预测,而是在每个位置上取最可能的K个预测,K为超参数。
Bert模型使用BEP编码来构建词汇表,当大多数单词仍然是单个词的时候,稀有单词就被标记为子词,因此对单个词或者是子词的方式不同。对待单个单词wj,现场时使用相应的top-k预测候选单词的Pj,并过滤所有停用词,如果是对于情感分类的任务,,由于Bert的Masked Language Model无法区分同义词和反义词还需要过滤反义词,最后对于选定的任意候选词ck,构造扰动序列H′=[h0,...,hi?1,ck,hi+1,...],如果目标模型已经预测错误,则打破循环获得最终的样本Sadv,否则继续直到找到合适的单词。
对于在Bert被标记为子词的单词,因为无法直接得到替代词,所以利用子词组合的困惑度从预测中寻找最合适的词。这里给定词w的子词列表[h0,h1,...,ht],从M的预测P∈t×k
中列出所有可能的组合,这是Kt大小的子词组合,作者将这些组合输入Bert-MLM中,求出这些组合的困惑度, 然后对所有组合的困惑度进行排序,获得前K个组合,最后找到合适的组合。
对于给定合适的扰动,使用最可能的扰动替换原始词,然后迭代重要词排序列表重复这一过程,已找到最终的对抗样本Sadv,并且不需要使用其他检查策略对Masked Language Model进行干扰。
最后将方法用于文本分类和自然语言推理任务中测试生成的对抗样本。
References




结束
招新小广告
ChaMd5?Venom?招收大佬入圈
新成立组IOT+工控+样本分析?长期招新
欢迎联系admin@chamd5.org

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 Chamd5安全团队
Chamd5安全团队
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675