 大数据文摘授权转载自AI科技评论
大数据文摘授权转载自AI科技评论
作者:耳洞打三金
大家好,我是三金。
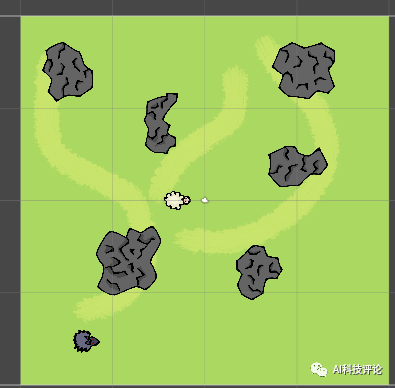
前几天我在上班摸鱼的时候,发现朋友圈好多人都在转一个狼吃羊的AI智障游戏,是在讲狼发现自己吃不到羊的情况下直接选择自杀:
自杀的场景大概如下:
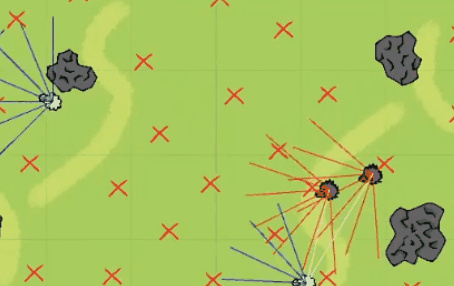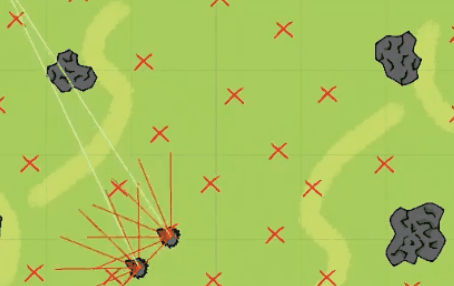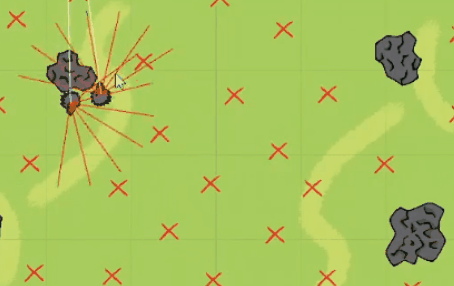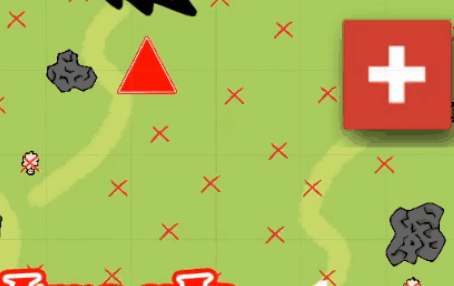
事情是这样的,就在前几天,微博上一位网友@二雨TR发文称 “听我老师给我讲他搞游戏ai的事情他妈笑死我了 。”
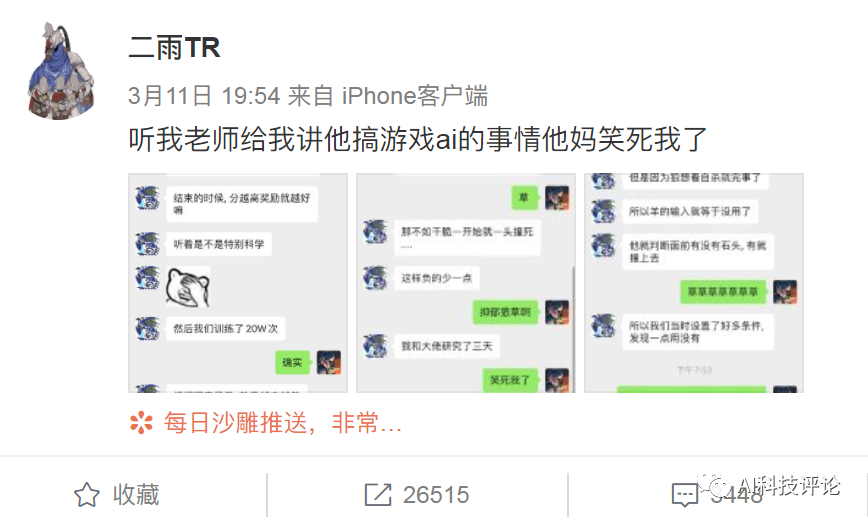
目前这条微博已经有两万多转发、三千多评论,并且这条微博上的三张图已经火出了圈,在朋友圈、知乎、豆瓣等很多平台都能见到它的身影。
下面就来看一下这三张图都讲了啥吧:
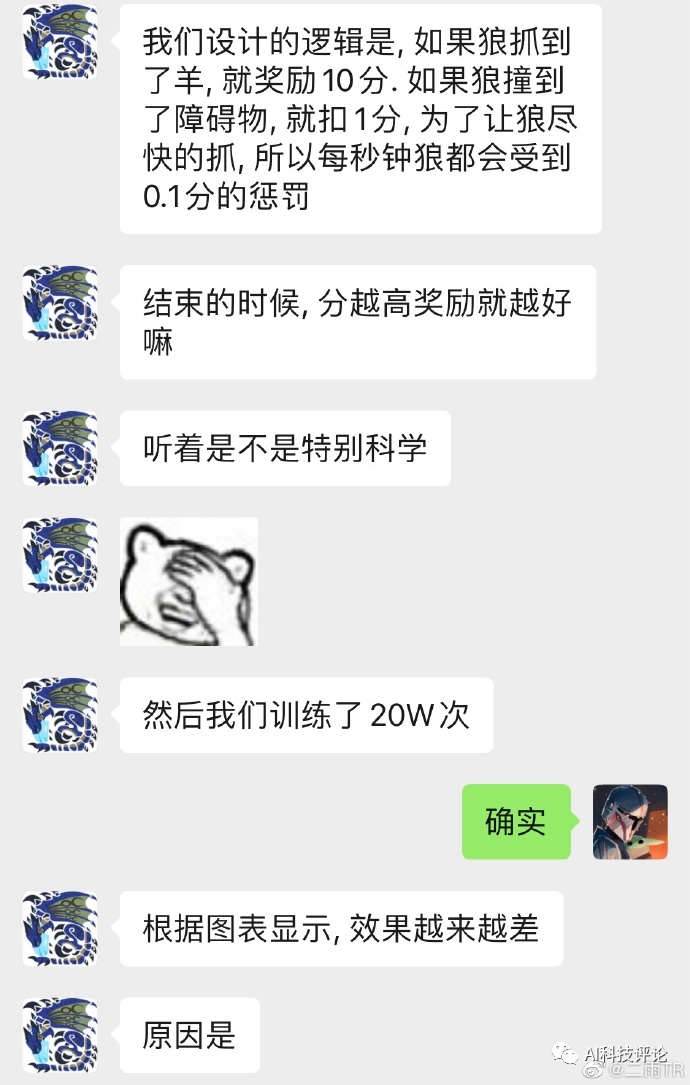


狼为什么会选择直接撞死呢?
因为自杀分数最高:
如果抓羊,在狼学会躲避障碍物之前它是碰不到羊的。假设前5w次狼做了一些绕开障碍的尝试但是都死了。
那他通过这5w次学到的东西就是——
原地站着15秒得-1.5分;
一头扎死得-1.1分;
所以由于狼根本没有吃到过羊,因此狼在-1.1到-2.4分之间选择了-1.1,也就是自杀。网友们眼很尖心很细,把AI狼自杀和内卷联系到了一起:- 狼就是打工人...每秒扣的是青春和时间,羊永远达不到的“升职、加薪、迎娶白富美、走上人生巅峰”。
- 面对不合理的KPI和奖惩机制,连ai展现出了令人类叹为观止的尊严。
- 为了激励狼快点抓羊而倒扣分是错误的,相反,应该激励狼活下去而每秒加0.1分。想要最高分当然会尽量抓羊,抓不到羊还撞障碍物扣分已经很劝退了,只有加分才能激励狼活下去。太现实了,只有活着本身就是一种奖励,人才愿意活下去。要不然真的不如一头撞死。
- 请给狼加一个参数:生命成本。这个参数的定义是我活这么大不容易随便死了太不值了。每次抓不到羊挫败-0.1,但每多活一天就累积+1,降到0才执行自杀,你就收获了一群要死不死的社畜狼了。
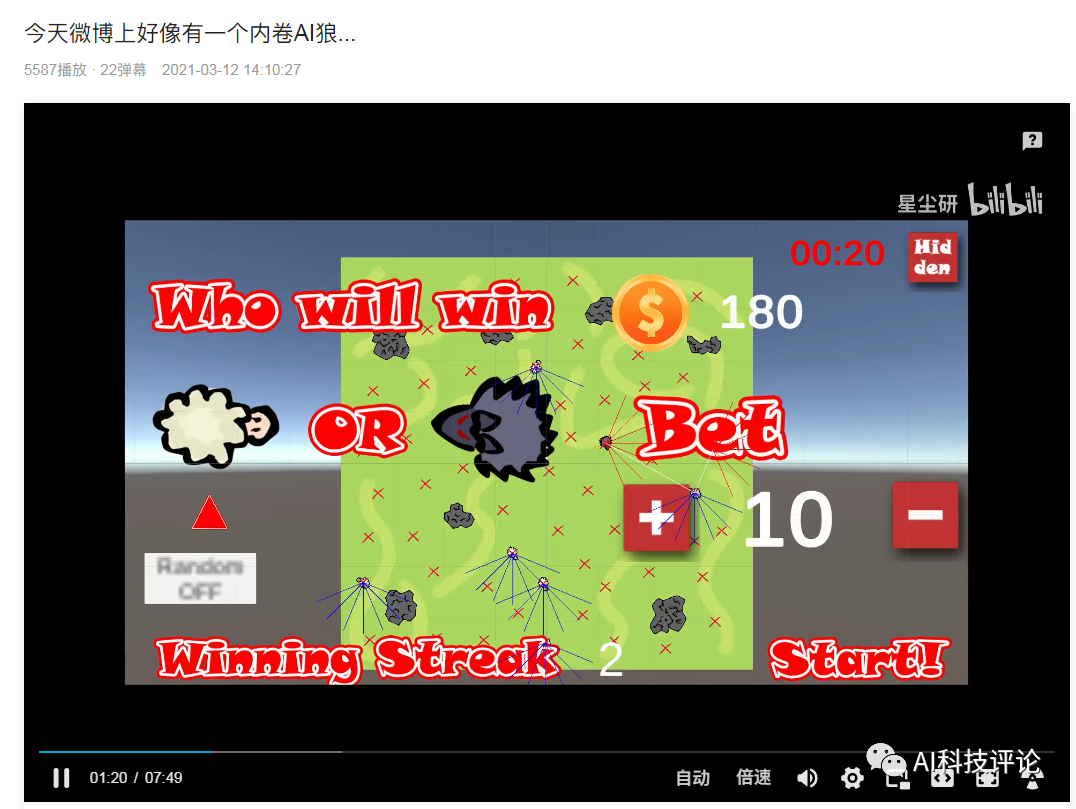
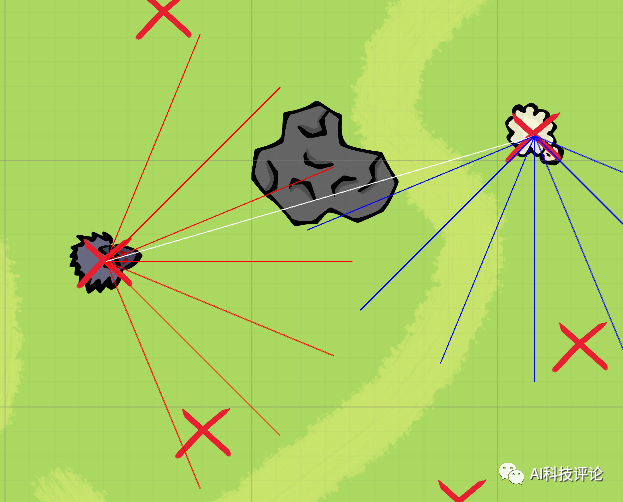
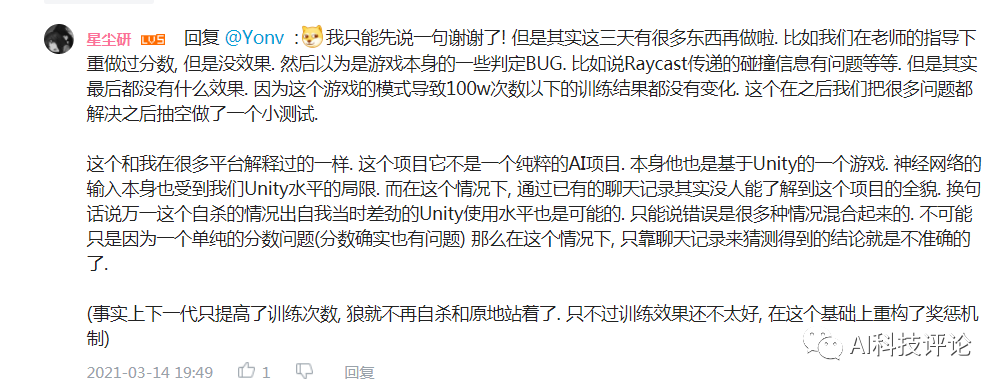
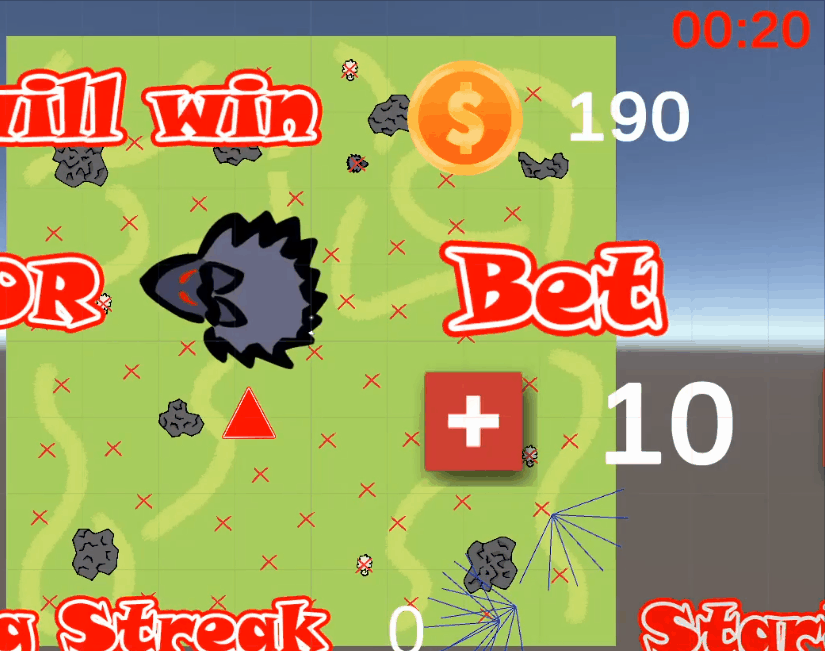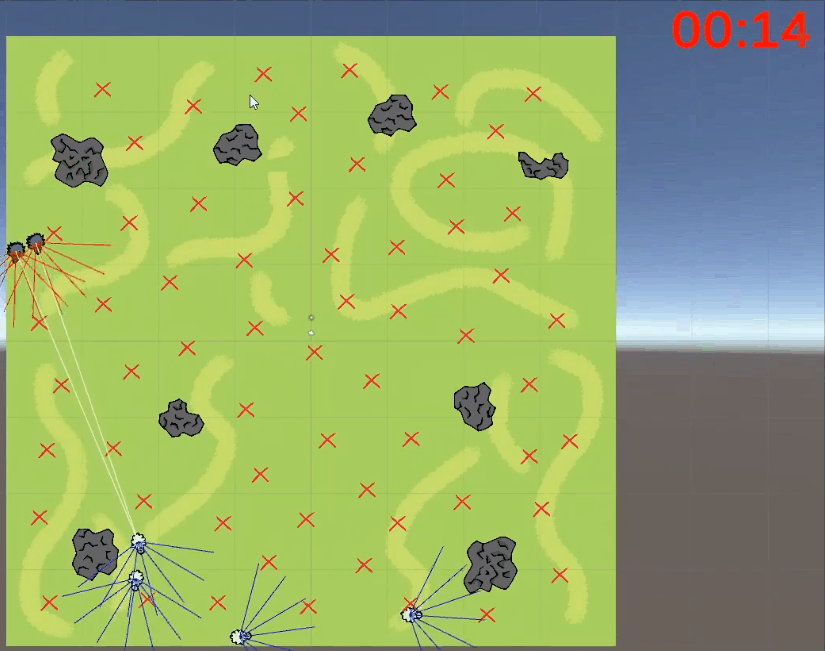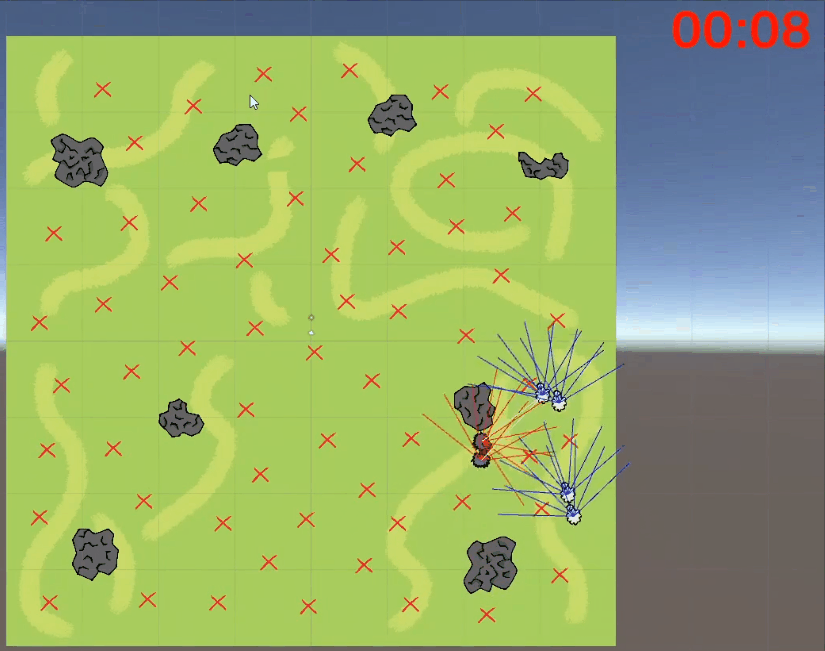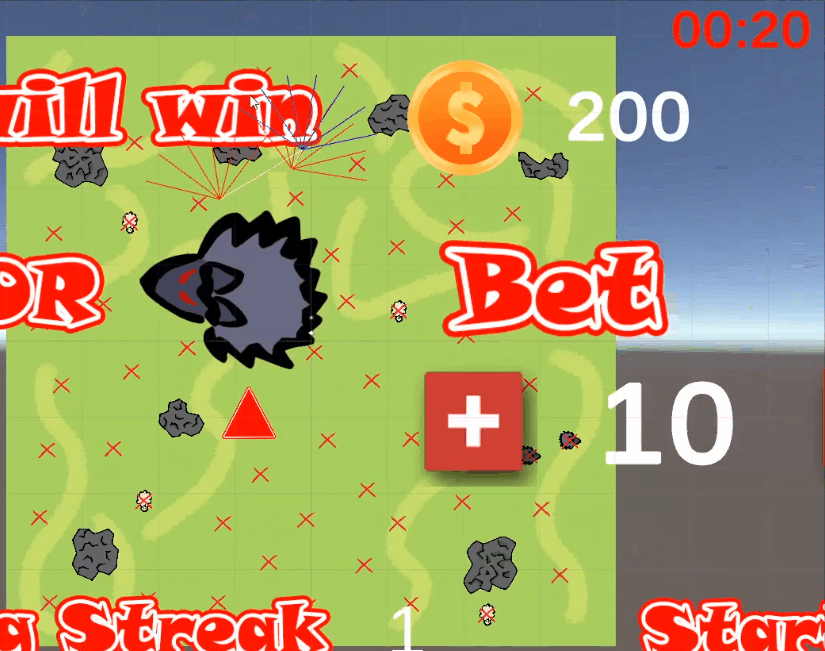
关于以上网友的发言,尽管和强化学习不沾边,但是我们也可以看着乐一乐,某些玩笑话或许在冥冥之中还是有某些道理的。有网友直言这是强化学习的奖励函数机制做的不合理,碰撞的惩罚太大了且死亡的惩罚应该给到负无穷大,让狼知道痛的滋味和代价,这样狼就不会选择自杀了:这个狼自杀的事虽然是因为奖励机制设置不合理的原因导致的,但总归还是很有意思的,所以三金我决定深入事件背后一线吃瓜 。据了解,文章开头发三张聊天截图的网友@二雨TR 并不是程序猿而是一位游戏绘画师,而她口中的老师是墨尔本的一位在读研究生。三金与二雨TR口中的老师 @星尘研 取得了联系,在联系之后,星尘研表示狼自杀的错误是很多东西共同影响产生的,最主要的一个错误是迭代次数太少,20W次完全不够学,后面提高到100W次起步, 效果直线上升。另一个就是奖励分数设置有问题,最后他们控制在了-2到1之间,效果也很好。大概在第十九代狼的时候就差不多可以用了,但是因为项目时间问题就没再接着往后训练了, 狼还是有点蠢。更巧的是星尘研刚好把这个事情的大概经过以及狼抓羊的游戏录制了一个说明视频放在了B站上面:据星尘研向三金介绍,他目前研究生专业是“动画,游戏和交互”,本科时候的专业是游戏和图形编程Games and Graphics Programming, 这个狼抓羊的项目是他本科最后一年的AI课和泰国的一位同学合作完成的,这时当时课程其中的一个作业,要求仅是【使用神经网络和强化学习、遗传算法等配合制作一个AI相关的游戏】。星尘研表示他只是AI的初学者、门外汉,也是第一次接触强化学习,懂得不多,一切都是摸索着来的。“这个项目一共4-5个星期,决定做什么, 然后怎么设计这套东西就花了一个星期, 再弄环境和开始的碰壁也花了不少时间,所以最后实际用在调算法bug的时间并不是很多。”游戏整体都是在Unity上面开发的,开发语言是C#,算法主体是基于Unity上封装好的一个强化学习包——MLAgent,GPU用的是他朋友淘汰的2手1080 Ti ?。我们最初的一个目标是让狼学会判断他要抓的是羊,并且学会去抓,这里的区别点在于狼要能认识到他要去吃羊,而不是我直接把羊的位置给他, 让狼自己去追。比如下面这是我们最开始的训练场景,在前几千次训练的时候, 狼都不知道要去吃羊,每次训练狼有大概5秒钟的时间在这个场地上面方向随机的乱跑乱逛 。在这个过程中, 狼可能会无意中吃到羊,并发现, 这一次的得分也许比之前要高,那么狼就可以靠得到更多分的奖励来慢慢学习抓羊。最开始的训练没有使用障碍物的原因, 就是要让狼先学到抓到羊,不然游戏没法继续。之后刚把障碍物加入时, 狼会特别完美的躲开障碍物,但是把障碍物稍微挪一下, 或者换一个形状,就不行了,原因就是狼只是记住了哪些点不能碰,而不是真正学会了识别障碍物。1. 狼游荡了10秒, 什么都没碰 -> 得-0.6分。2. 狼游荡了10秒, 什么都没碰,并且吃了羊 -> 得0.4分。3. 狼花了3秒, 碰了一个障碍, 但是吃到了羊 -> 得0.72分。可以看出这时狼即使撞了石头也还是有一个不错的得分的。1、开局两只狼(训练时其实是一只)、六只羊,位置随机,石头位置随机 ,地图上带 X的符号就是狼和羊可能随机出现的位置。2、狼和羊的感知范围由坐标面前的射线所定义,狼面前的6根线是会和障碍物以及地图边界碰撞的,碰撞的时候会返回一个坐标。3、狼和羊之间的白线是狼和最近的羊之间连接,狼每次优先去吃离它最近的羊。4、最开始把羊固定了位置,狼学会抓羊之后,才让羊动。5、羊撞到石头不会死,羊的高分条件只有一个:存活时间尽量长。羊没有说被训练成要故意躲着狼,羊被吃没有直接惩罚,也不会主动躲避石头。
。据了解,文章开头发三张聊天截图的网友@二雨TR 并不是程序猿而是一位游戏绘画师,而她口中的老师是墨尔本的一位在读研究生。三金与二雨TR口中的老师 @星尘研 取得了联系,在联系之后,星尘研表示狼自杀的错误是很多东西共同影响产生的,最主要的一个错误是迭代次数太少,20W次完全不够学,后面提高到100W次起步, 效果直线上升。另一个就是奖励分数设置有问题,最后他们控制在了-2到1之间,效果也很好。大概在第十九代狼的时候就差不多可以用了,但是因为项目时间问题就没再接着往后训练了, 狼还是有点蠢。更巧的是星尘研刚好把这个事情的大概经过以及狼抓羊的游戏录制了一个说明视频放在了B站上面:据星尘研向三金介绍,他目前研究生专业是“动画,游戏和交互”,本科时候的专业是游戏和图形编程Games and Graphics Programming, 这个狼抓羊的项目是他本科最后一年的AI课和泰国的一位同学合作完成的,这时当时课程其中的一个作业,要求仅是【使用神经网络和强化学习、遗传算法等配合制作一个AI相关的游戏】。星尘研表示他只是AI的初学者、门外汉,也是第一次接触强化学习,懂得不多,一切都是摸索着来的。“这个项目一共4-5个星期,决定做什么, 然后怎么设计这套东西就花了一个星期, 再弄环境和开始的碰壁也花了不少时间,所以最后实际用在调算法bug的时间并不是很多。”游戏整体都是在Unity上面开发的,开发语言是C#,算法主体是基于Unity上封装好的一个强化学习包——MLAgent,GPU用的是他朋友淘汰的2手1080 Ti ?。我们最初的一个目标是让狼学会判断他要抓的是羊,并且学会去抓,这里的区别点在于狼要能认识到他要去吃羊,而不是我直接把羊的位置给他, 让狼自己去追。比如下面这是我们最开始的训练场景,在前几千次训练的时候, 狼都不知道要去吃羊,每次训练狼有大概5秒钟的时间在这个场地上面方向随机的乱跑乱逛 。在这个过程中, 狼可能会无意中吃到羊,并发现, 这一次的得分也许比之前要高,那么狼就可以靠得到更多分的奖励来慢慢学习抓羊。最开始的训练没有使用障碍物的原因, 就是要让狼先学到抓到羊,不然游戏没法继续。之后刚把障碍物加入时, 狼会特别完美的躲开障碍物,但是把障碍物稍微挪一下, 或者换一个形状,就不行了,原因就是狼只是记住了哪些点不能碰,而不是真正学会了识别障碍物。1. 狼游荡了10秒, 什么都没碰 -> 得-0.6分。2. 狼游荡了10秒, 什么都没碰,并且吃了羊 -> 得0.4分。3. 狼花了3秒, 碰了一个障碍, 但是吃到了羊 -> 得0.72分。可以看出这时狼即使撞了石头也还是有一个不错的得分的。1、开局两只狼(训练时其实是一只)、六只羊,位置随机,石头位置随机 ,地图上带 X的符号就是狼和羊可能随机出现的位置。2、狼和羊的感知范围由坐标面前的射线所定义,狼面前的6根线是会和障碍物以及地图边界碰撞的,碰撞的时候会返回一个坐标。3、狼和羊之间的白线是狼和最近的羊之间连接,狼每次优先去吃离它最近的羊。4、最开始把羊固定了位置,狼学会抓羊之后,才让羊动。5、羊撞到石头不会死,羊的高分条件只有一个:存活时间尽量长。羊没有说被训练成要故意躲着狼,羊被吃没有直接惩罚,也不会主动躲避石头。- 狼吃到羊的数量越多越好:抓羊的奖励是每只=1/羊的数量,抓到所有羊奖励为1。
- 吃到羊所用时间越短越好:表现在狼多花费一秒则每秒惩罚0.06,撞到石头扣0.2。
7、狼和羊是有面积大小的,地图大小在Unity里是80X80 。而星尘研他们在发现狼自杀后的三天内也不是什么都没做:星尘研的解释是“只是为了加快训练时间,因为在狼学会吃到羊之前它可能只会打转会原地不动来等时间消耗,大大增加了训练所花费的时间。”
当然游戏因为各种原因还是存在缺陷的,比如两只狼还是会偶尔撞石头而死:狼吃羊的游戏先演示到这里,想看到更多的案例可以移步原视频。而关于强化学习更多的知识,建议大家阅读强化学习领域圣经之书——《强化学习导论》第二版。那么除了这个狼吃羊的游戏之外,AI出Bug或者说AI智障的例子还多吗?https://www.zhihu.com/question/448931860
-----------------------------------------那难道就没有那种表现聪明的、行为成熟的、多智能体合作的强化学习 AI 吗?当然也有,这里不得不提一下Open AI的AI玩捉迷藏游戏:这个强化学习游戏项目的参与者有毕业于姚班现又回姚班教学的吴翼。吴翼师从人工智能泰斗、加州伯克利大学 Stuart Russell 教授,其论文 Value Iteration Network 荣获 NIPS 2016 年度最佳论文奖;多次在 ACM-ICPC 竞赛中取得好成绩,两次参加全球总决赛获得一枚银牌一枚铜牌。具体而言,研究者在这个项目中创造了一个模拟环境,环境中有许多物体,例如箱子、梯子以及小蓝人和小红人。小蓝人代表捉迷藏游戏中的“藏匿者”,小红人代表游戏中的“寻找者”。小红人的目的就是为了抓住小蓝人,当然,捉迷藏游戏总是要给藏匿者提供准备时间,所以在游戏开始的一段时间,小红人(寻找者)需要等在原地不能动让小蓝人(藏匿者)做好准备。经过强化学习和多智能体的自博弈,发现藏匿者和寻找者之间生成了很多种策略和反策略。在训练最初阶段的策略是:小红人追着小蓝人跑,小蓝人只能四处逃窜。起初,AI们完全不知道自己能做什么,只是出于“本能”逃跑、追逐。但是在2500万次游戏训练之后,小蓝人学会了通过移动箱子,来建造把自己藏起来的庇护所。道高一丈魔高一尺。又经过了7500万次训练之后,小红人在没有任何人指导的情况下全凭自己学会了将斜坡移动到小蓝人用箱子搭建的“城堡”旁边,然后借助斜坡闯进“城堡”!小蓝人在这样输了1000万次之后,竟学会了提前把斜坡给搬进城堡让小红人无坡可爬。当然不是,仔细观察后很容易发现,小蓝人之间自主地学会了很有策略性的团队配合:在3.8亿次游戏训练之后可以看到,在小蓝人把所有的斜坡都给锁住、并且把自己给保藏起来之后,小红人竟然自主地学会了移动箱子到锁住的斜坡旁边,然后通过斜坡跳到箱子上,然后踩着箱子移动,就好像在冲浪一样,一路来到了小蓝人旁边并跳到里面抓住了小蓝人。而据研究者爆料,其实“踩着箱子移动”是系统设定产生的“bug”,小红抓住并利用上了这个bug !可真是太鸡贼了,且稍微有些反人类直觉。最后在将近5亿次训练之后,针对小红人的鸡贼,小蓝人直接放大招!从生物进化的角度来看,人类是一个可以不断适应新环境的物种,但人工智能却不是这样。因此,越来越多的研究者希望构建在行为、学习和进化等方面更类人的机器智能。由于捉迷藏游戏中的目标相对简单,多个智能体通过竞争性的自我博弈进行训练之后,可以学会如何使用工具和类人一样的技能取得游戏中的胜利。而在这种简单环境中以自监督的方式学到的复杂策略进一步表明,多智能体协同合作适应在将来某一天很有可能生成极度复杂和智能的行为。OpenAI 相信,这一研究会成为一个智能体开发和部署的非常有前景的方向。而DeepMind 创始人哈萨比斯对游戏AI 则是这样来看的:?游戏AI是通往通用人工智能的垫脚石。我们研究这些游戏的真正原因是,它是研究通用AI算法的一个非常方便的试验场。我们正在开发一种新算法,可以将其转化到现实世界中来,用于解决现实中真正具有挑战性的问题,并帮助这些领域的专家。
而用游戏的方式训练出可以在真实场景里应用的AI技术,可以称得上是创造了一个小世界,在这个小世界发生的魔幻的事在将来一天未必不会出现在现实生活中。最后回到狼吃羊身上,也许未来的某一天真的会“狼”来了,而人类就是那“可爱善良但不无辜”的小绵羊......https://www.bilibili.com/video/BV16X4y1V7Yu?p=1&share_medium=android&share_plat=android&share_source=COPY&share_tag=s_i×tamp=1615693913&unique_k=hUhmwF
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/































 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




