坐拥270亿参数!阿里达摩院发布超大规模语言模型PLUG,上能写诗词歌赋、下能对答如流

作者 | 马超
出品 | CSDN(ID:CSDNnews)
日前,阿里达摩院发布了最新中文预训练语言模型 PLUG,在 PLUG 生成的各种诗歌与小说中,不时灵光闪现式的金句、妙语令人啧啧称奇。
但是以笔者从业多年的经验看,这些 PLUG 的金句虽然值得细细口味,但此时更应该关注的还是 PLUG 如何介绍自己,于是我就在“自由创作”的试用栏目输入了“自然语言处理模型 PLUG ”的题目,虽然受到算力限制,PLUG 并没有生成出完整的结果,但是这也已经有点上道的意思。
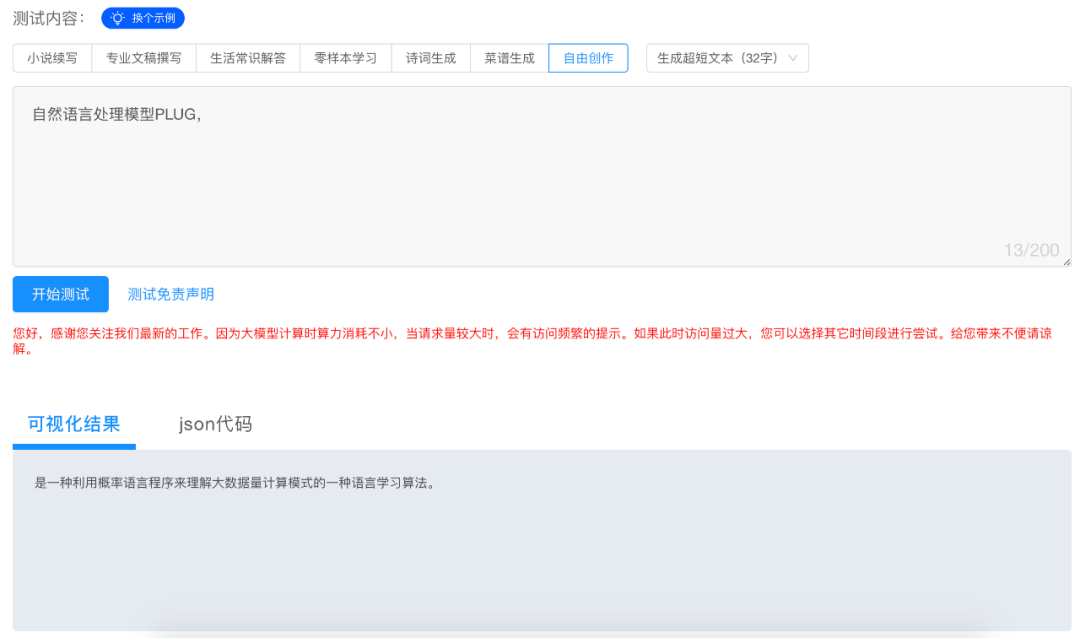
我们知道评价智能化程度的重要指标,就是智能体是否具有认知能力,从目前 PLUG 的理解与生成情况看,未来 PLUG 的进化终极体会不会直接把文科生的饭碗“抢”了,其实也未尝不可能。
从技术角度看,PLUG(Pre-training for Language Understanding and Generation)最令人瞩目的是参数规模达到 270 亿,虽然还比不上 GPT-3 模型 1750 亿的参数量,但在中文社区的纯文本预训练语言模型中,这已是目前为止最大规模,算是不错的成就。接下来,PLUG 会将参数规模扩大到 2000 亿,并进一步提高文本生成质量。
不同于 GPT-3 单向生成模型,PLUG 集合了达摩院 NLU 语言模型 StructBERT 与 NLG 语言模型 PALM 两大自然语言模型的优势,并通过构建输入文本双向理解能力,显著提升了输出文本的相关性。在语言理解任务上,PLUG 以 80.614 分刷新了 CLUE 分类榜单纪录;在语言生成任务上,PLUG 多项应用数据较业内最优水平提升了 8% 以上。


大规模自然语言模型简史
2019 年在《权力的游戏》结局烂尾之际,OpenAI 的超大规模预训练语言模型 GPT 系列成功上位,有热心网友使用 GPT-2 来重写权游剧本的结局。网友普遍反应 AI 改写的新结局比电视剧的版本强太多,一时之间 GPT 各种喜提热搜,而抱得大名。

去年 GPT-3 又横空出世,这是一个只要你会简单的英语,并能大概描述需求,它就能给你生成前端的代码的强力模型,像笔者这种在 IT 界摸爬滚打十几年的老程序员,在试用了 GPT-3 网站之后,也惊得说不出话来,瞬间感觉程序员这行也没那么香了。
自此以后,中文领域的自然语言模型进展也备受业界关注,正如前文所说阿里达摩院本次发布的 PLUG,让我觉得码字的文职岗位可能也要凉了….经过不断的进化,未来 PLUG 这类超大语言模型将泛应用于文本生成领域,成为“万能写作神器”。
更重要的是,PLUG 等模型展现出了极强的通用性与适应性,这才是未来真正有可能改变世界的关键点。接下来笔者从技术角度,向大家介绍一下达摩院的 PLUG 为什么如此之强。

PLUG 为何如此之强?
PLUG 采用了 1TB 以上高质量中文文本训练数据,依托阿里云 EFLOPS 高性能 AI 计算集群训练模型,强大的算力支撑肯定肯定是阿里训练 PLUG 的核心竞争力之一,而一方面 NLU 语言模型 StructBERT 与 NLG 语言模型 PALM 两大自然语言模型的共同加持也同样功不可没。
我们知道目前自然语言处理的模型中有自编码和自回归两大流派,而 StructBERT 和 PALM 就分别是这两大流派的优秀代表:
自编码模型:StructBERT 就属于典型的自编码模型。这是一项由词嵌入技术发展而来的技术流派。而以 BERT 为代表的自编码模型发展了词嵌入这思想,他们把句子中的单词加上掩码(mask)并通过 AI 模型将 mask 还原,以此完成对于每个字的编码的建模。
比如这个句子:我爱北京天安门,天安门上太阳升。
按照 BERT 的训练方式,它会随机将每个字替换为 mask:
我 [mask] 北京 [mask]安门,天安门上太[mask]升。
然后将 mask 还原回来,通过以上训练方式我们也可以知道自编码模型特别能挑出错字,也就比较适合用于 NLU 也就是自然语言理解的任务。StructBERT 在 BERT 的基础上,特别加强句子级别(Sentence Structural Objective)和词级别(Word Structural 两个层次的建模工作。按照笔者的理解这也就是说,StructBERT 针对词与句子多做了两层的 mask。还拿“我爱北京天安门,天安门上太阳升”这句话来举例。句子级别的建模加强了 BERT 原有的 NSP 任务,需要模型能分辨“我爱北京天安门,天安门上太阳升”是一个正确的语序而“天安门上太阳升,我爱北京天安门”是颠倒的两句话。词级别的建模引入了 tri-gram 的语序还原,比如“我爱北京门天安”的正确语序是“我爱北京天安门”。
自回归模型:PLAM 是典型的自回归模型,其实通俗来看,自回归就是使用自身做回归变量的过程,比如在见到“我爱北京天安?”这段语义集的时候,模型将“?”处预测为“门”的概率就会特别大。
假设我们 I、love、you 三个单词分别对应向量:X_1、X_2、X_3,那么如果我们要建模 ”I love you” 这句话,其实就要通过贝叶斯公式解出,在自然语言这个序列出现的联合概率分布 P(X_1,X_2,X_3)。
由于词语之间不是独立的,我们仅统计 P(X_1)、P(X_2)、P(X_3)三个概率是不够的。因为 X_1 还依赖于其它变量存在条件分布 P(X_2|X_1) 和 P(X_3|X_1)。对于 X_2 和 X_3 也是一样,我们可以将这三个模型组合起来获得期望联合分布 P(X_1,X_2,X_3)=P(X_1)P(X_2|X_1)P(X_3|X_1,X_2)
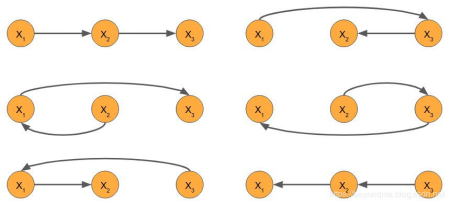
在自回归模型中都考虑了顺序信息,也就是说他看到 I Love 之后极有可能续写出后面的 “you” 来,这样的条件概率算法是自回归模型的基础。
而 PALM 模型的 encoder-decoder 范式也属于自回归模型的范畴。不同的是,PALM 的 encoder 建模阶段保留了 StructBERT 的训练目标,从而具备更强的文本建模能力,并使得模型能够保留在 NLU 任务上的良好表现。
达摩院团队汲取自编码与自回归两大模型的所长,进行自然语言理解与生成的联合训练。因此能够开看对于 GPT 系列模型的优势。据悉接下来 PLUG 将扩大参数规模至 2000 亿级,以进一步提升文本生成质量。
而笔者认为,如果像 PLUG 这么高端的模型也能飞入寻常百姓家为大众所广泛使用,全面推广的话,那也一定是借了云平台的风,PLUG 的发布还开启了 AI 云计算的新篇章。

AI 云大幕开启
从目前 AI 的发展趋势来看,最新的人工智能模型对于算力的要求越来越高,自上一代自编码模型 Google T5 开始,主流自然语言处理模型的参数数量就突破了百亿大关,甚至谷歌科学家直接在 T5 的论文指出:“越大的模型往往表现更好。这表现扩大规模可能仍然是实现更好性能的方式。“像 GPT-3 参数量更是突破了千亿大关,而 GPT-3 的变种那个可以通过语言描述生成绘画的 DALL.E 参数量更是突破了两千亿。这样的模型训练成本之高,小型的初创公司只能望而却步。
从另一个角度讲,这样的趋势也推进了 AI 与云的结合,只有将 云、人与智能终端结合到一起,才能降低门槛,促进行业创新发展。而这种结合实际与全场景栈 AI 是同一概念,也只有做好 AI 云,才能让 AI 充分发挥威力,体现价值。
此次达摩院在 PLUG 刚刚训练完成之时,就通过阿里云对学术界提供测试体验端口的做法,值得我们点赞,开源共享的做法就是云计算的时代精神。本次达摩院发布的大规模模型一方面将从数据驱动(Data-driven)逐步发展到知识驱动(Knowledge-driven),探索数据和知识深度融合的预训练语言模型;另一方面将不仅仅追求模型参数规模扩大,而会更关注超大模型的落地应用实践。
与 PLUG 发布同步,达摩院宣布近期将开源阿里巴巴深度语言模型体系大部分重要模型。阿里达摩院语言技术实验室负责人司罗表示,“达摩院 NLP 团队将进一步攻克自然语言处理领域科研难题,完善中文及跨语言人工智能基础设施,让 AI 没有难懂的语言,并探索通用人工智能之路。”
声明:本文为作者独立观点,不代表 CSDN 立场。


☞程序员吞噬零售业,成也中台败也中台 | 零售十年变迁路
☞顶配售价 18499 元,用上 M1 的 iPad Pro 性能与价格“直逼”电脑,这届苹果发布会有你喜欢的吗?
☞等待十年,史上第一个 64 位版 Visual Studio 将于今夏公开首个预览版!
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 三个关键词看习主席俄罗斯之行 7904377
- 2 央行证监会等将重磅发声 7809249
- 3 斯凯奇宣布退市 7712867
- 4 外贸企业如何突出重围 7619464
- 5 刘强东回应“凑76个鸡蛋上大学” 7519723
- 6 中欧全面取消交往限制 7428183
- 7 默茨当选德国总理 7330724
- 8 北约12国1.6万兵力直逼俄边境 7234247
- 9 河南老人强拦婚车讨喜烟 被特警驱离 7136137
- 10 年轻人开始租三金结婚 7041122