
推荐 :基于新闻标题的股价走势分析(附链接)
作者:??Ronil Patil??翻译:王闯 (Chuck)。校对:詹好
“不要在草堆里找一根藏针,而是要买下整个草堆!”
数据集介绍
标签为1–股价上涨。
标签为0–股价持平或下跌。
开始
首先引入相关库
import pandas as pdfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import classification_report,confusion_matrix,accuracy_score
读取数据集
df = pd.read_csv('F:Stock-Sentiment-Analysis-master/Stock News Dataset.csv', encoding = "ISO-8859-1")
将数据集划分为训练集和测试集
train = df[df['Date'] < '20150101']test = df[df['Date'] > '20141231']
特征工程
# Removing special charactersdata=train.iloc[:,2:27]data.replace("[^a-zA-Z]"," ",regex=True, inplace=True)# Renaming column names for better understanding and ease of accesslist1= [i for i in range(25)]new_Index=[str(i) for i in list1]data.columns= new_Indexdata.head(5)

# Convertng headlines to lower casefor index in new_Index:data[index] = data[index].str.lower()data.head(1)
根据索引来合并所有新闻标题:
headlines = []for row in range(0,len(data.index)):headlines.append(' '.join(str(x) for x in data.iloc[row,0:25]))

应用CountVectorizer和RandomForestClassifier方法
## implement BAG OF WORDScountvector=CountVectorizer(ngram_range=(2,2))traindataset=countvector.fit_transform(headlines)## implement RandomForest Classifier
randomclassifier=RandomForestClassifier(n_estimators=200,criterion='entropy')randomclassifier.fit(traindataset,train['Label'])
在测试集上进行预测
## Predict for the Test Datasettest_transform= []for row in range(0,len(test.index)):test_transform.append(' '.join(str(x) for x in test.iloc[row,2:27]))test_dataset = countvector.transform(test_transform)predictions = randomclassifier.predict(test_dataset)
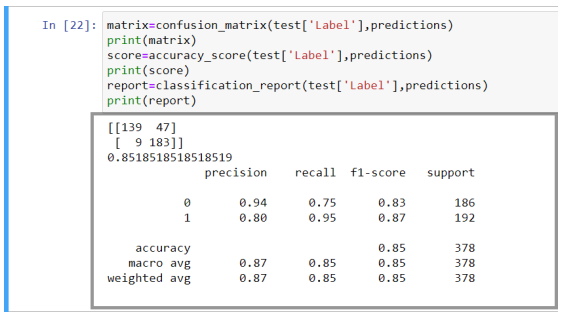
最后,检查准确性?
matrix = confusion_matrix(test['Label'],predictions)print(matrix)score = accuracy_score(test['Label'],predictions)print(score)report = classification_report(test['Label'],predictions)print(report)
关于作者
Ronil?Patil
https://www.linkedin.com/in/ronil08/
原文标题:
Stock Price Movement Based On News Headline
原文链接:
https://www.analyticsvidhya.com/blog/2021/05/stock-price-movement-based-on-news-headline
译者简介:王闯(Chuck),台湾清华大学资讯工程硕士。曾任奥浦诺管理咨询公司数据分析主管,现任尼尔森市场研究公司数据科学经理。很荣幸有机会通过数据派THU微信公众平台和各位老师、同学以及同行前辈们交流学习。
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675