
数据搜索的新战场,我们为什么需要向量数据库?

提到搜索引擎,大家首先想到的一般是ElasticSearch。在文本作为信息主要载体的阶段,ElasticSearch技术栈是文本搜索的最佳实践。然而目前搜索领域的数据基础发生了深刻的变化,远远超过文本的范畴。视频、语音、图像、文本、社交关系、时空数据等非结构化数据构筑了更加“立体”的语义基础。
传统的文本搜索技术与实践方法很难套用到新兴的数据搜索场景上。主要的原因是,在非结构化数据中含有大量隐式的语义信息,而这些信息没办法通过语言文字进行准确的描述。例如,商品识别、人脸匹配、药物筛选、用户偏好与内容推荐等。对于这样的搜索场景,目前的主流做法是通过神经网络对数据中的语义进行提取。但这些提取出来的信息并不以文字的方式进行描述,而是表示为具有隐式语义的高维向量。
向量数据库以这些具有隐式语义的向量作为数据基础,向上层应用提供搜索服务。在AI作为搜索主要驱动力的新阶段,向量数据库是构成非结构化数据搜索技术栈的重要基础软件。
以下,我们从基本模型的角度出发,具体聊一聊为什么文本搜索技术难以适用到更加广泛的数据搜索场景,并对向量搜索的基本模型进行介绍。

向量空间中的文本搜索
对于非结构化数据的语义,常见的做法是在高维空间内对其进行描述。整个空间定义了所有可能的语义范围。在这个空间内,语义相似度通过距离来度量。每个在实际业务中出现的非结构化数据被映射到这个空间内的一个点(或称为一个高维向量),两个非结构化数据的相似度即是这两个点间的距离。不论是面向文本的TF-IDF向量,还是基于神经网络构造的embeddings,其语义相关性分析都是遵循这个思路。
为了方便理解,我们先从大家熟悉的文本搜索聊起。
考虑以下三段文本:
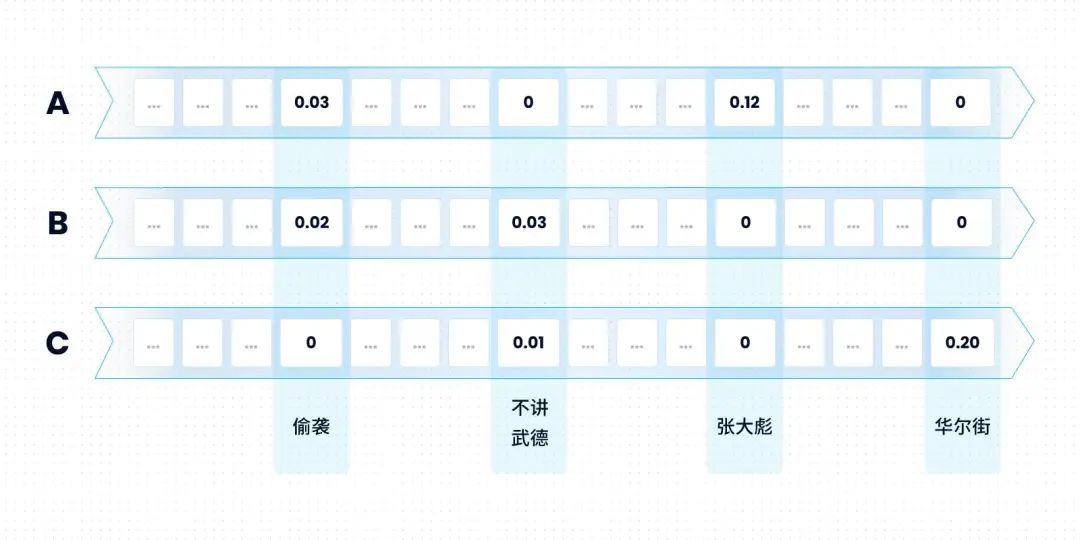
A:”......第一次偷袭,是在淮海战场之上,张大彪建议先打就近的敌暂七师......“
B:”......这两个年轻人,不讲武德,来骗!来偷袭!打我69岁的老同志。这好吗?这不好......“
C:”......华尔街不讲武德,WSB散户被拔网线......“
从精简的模型上看,ElasticSearch(或Lucene)中的每一份文本都可以用一个高维向量来表示。向量的维度是词典中所包含的词的总数,每个维度对应一个词,而各维度上的值为这些词的TF-IDF分数(一个考虑了词频与逆文本频率的分数,如果一个词在文本中未出现,该分数为0)。
那么上面三个文本对应的向量大概长这个样子:
如果一个查询请求是:
Q:"偷袭" and "不讲武德"
这个查询请求也会被映射到同样的向量空间中。其对应的向量为:

“距离”的度量方式为:
$ f(Q,x)=\left{ \begin{aligned}&cos(Q, x),\ \ if\ 偷袭\in x\ and\ 不讲武德\in x\ \ \ \ (1)\ &0,\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if\ 偷袭\notin x\ or\ 不讲武德\notin x\ \ \ \ \ \ \ (2)\end{aligned} \right. $
这个值越大,x 与 Q 越相似。本例中,与查询语句最相似的文本为B。Lucene在工程实现层面对上述模型做了大量优化。如我们所熟知的倒排索引作用于上式的条件(2),这类似一个剪枝的过程:如果一个必要的关键字没有出现,那么该文本与查询语句的相似度为0。既然一定不会出现在最终的搜索结果中,那就没有必要进行后续的距离计算。
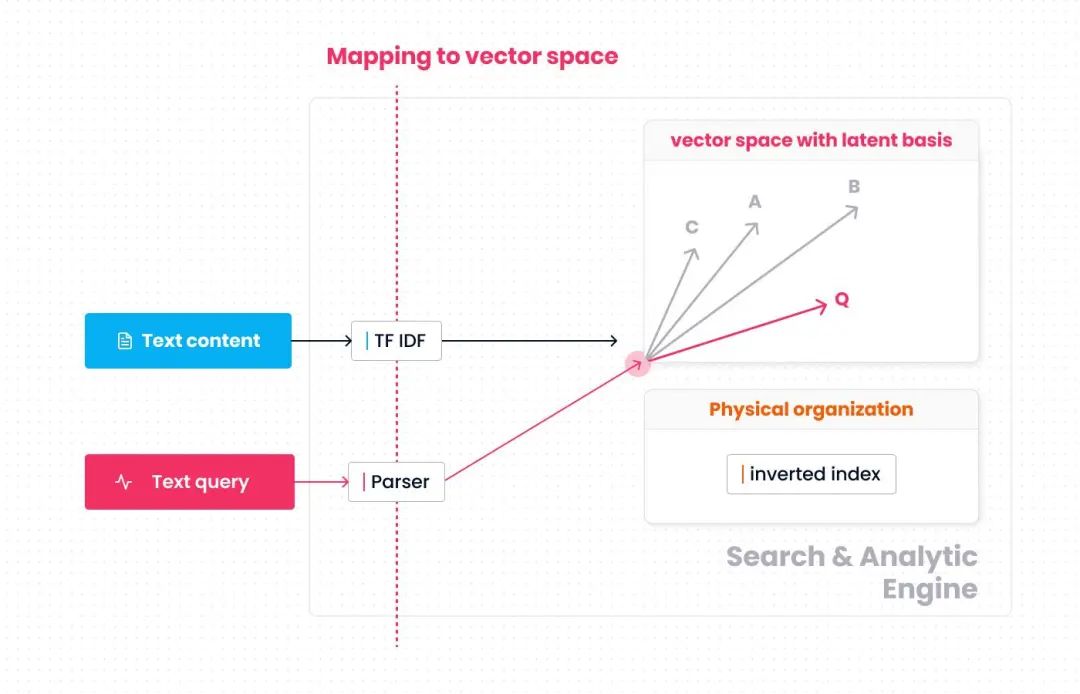
上图总结了这个简化的模型,向量空间以各词语 (term) 作为坐标基。关键字搜索分为两个阶段。首先是原始数据到向量空间的映射过程。文本按词语统计词频 (TF)、逆文档频率 (IDF),并计算各词语上的TF-IDF值。查询语句则按谓词中出现的词语 (如"偷袭"、"不讲武德") 映射至向量空间。其次是相似性分析,基于倒排索引加速向量空间内的搜索过程和距离计算过程,找出与查询语句向量相似的数据向量。
模型的基础部分面向文本搜索进行了特化设计,包括:
向量空间:维度与词语一一对应;
数据到向量空间的映射:基于TF-IDF、谓词;
相似性搜索:以倒排索引进行数据组织。

从”显式“与“可解释性”,到“隐式”与”准确性“
可以明显看出,文本搜索以“显式”的语义为基础,模型层面和工程层面大体上都基于“词”这个概念进行构建。这对于文本搜索是自然的,整个搜索过程对于“人”也是好理解的。但相同的模型很难适用于更广泛的非结构化数据搜索。其中面临的问题主要有两个:
一方面,在众多非结构化数据中,很大一部分都不具有“显式”的语义单元。例如,很难将一段视频、一张照片、一个高分子化合物、一段用户行为分解为类似“词”这种显式的、细小的语义单元。
另一方面,在实际的搜索业务中往往希望引入多个维度的非结构化信息,从而能够更加立体地描述业务对象。以视频推荐为例,其搜索的输入是用户特征,而搜索的结果是最符合用户当前浏览偏好的一组视频。搜索结果的好坏很大程度上依赖于对“用户观看偏好”的理解。但用户偏好是一个复杂的概念,难以用单一维度的信息进行准确描述。实际业务中,参考的特征来源丰富:包括视频分类、标签、时长、语言、用户浏览历史、搜索历史、用户地理位置、年龄、性别、语言等。
由多个维度的非结构化数据所驱动的数据搜索已经变得越来越普遍。在用户的业务中,我们观察到越来越多的搜索场景都需要解决好上述两个问题,除了上面提到的视频推荐,还包括药物筛选、人脸识别、辅助设计、商品推荐等。
为了在这些搜索场景上获得更好的效果,新兴的搜索技术在可解释性与准确性之间给出了新的权衡。以神经网络、embedding为代表的新技术更多考虑了后者。
这些技术在主体思路上与文本搜索一致,都是将查询的输入与搜索内容映射至具有相同语义的向量空间,并在这个空间内根据距离进行相似度分析。而差异在于,向量空间所对应的是隐式语义,向量空间着重于对语义相似性的准确刻画,但不再具有易解读的性质。
对应视频推荐的例子,典型的做法是将不同维度的特征进行汇总,并基于这些信息训练神经网络,分别以神经网络的中间层参数、中间层输出作为视频embedding、用户embedding。基于数据训练得到的神经网络对应着用户、视频两类对象到向量空间的映射函数,这个映射函数的训练目标是最小化语义相似性的误差,但不论是映射函数还是向量空间,都不具有良好的可解释性。

泛化的非结构化数据搜索
一个具有泛化能力的非结构化数据搜索系统应该具备两个特征:
能够应对非结构化数据的多样性;
能够充分发挥神经网络等新型模型对语义的刻画能力。
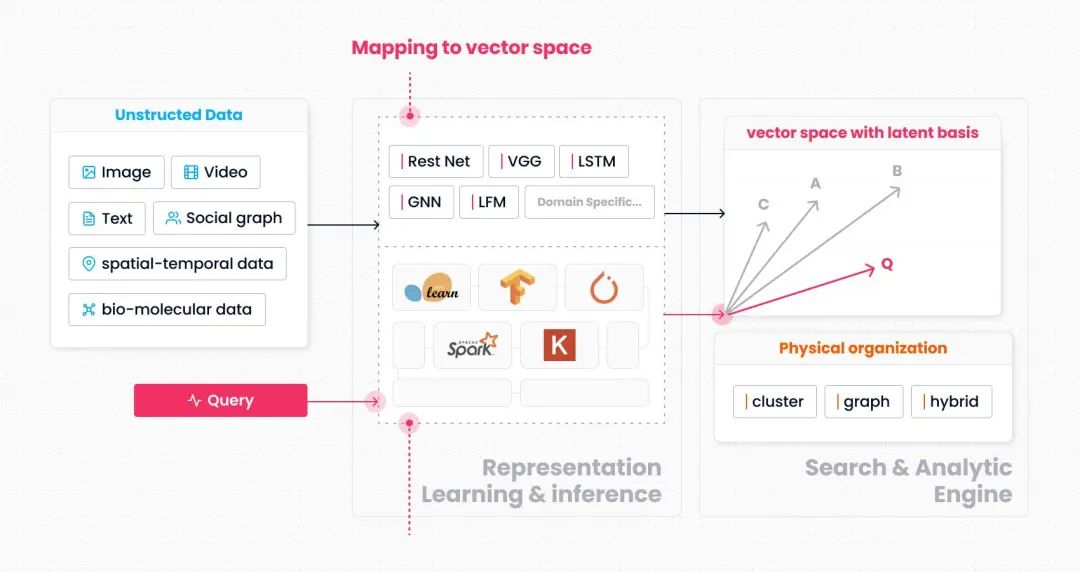
我们给出的泛化模型如上图所示。与前面讲到的文本搜索模型相比,这个模型在结构上的明显区别是将“数据到向量空间的映射函数”从搜索引擎内移到了搜索引擎外。即图中“Mapping to vector space”的这部分(一般对应机器学习领域的encoder)。
这个选型的背后原因主要来自于工程层面。首先需要考虑的问题是数据类型爆炸。与传统的数值类型不同,当前的非结构化数据大多与业务场景直接相关,且数据类型的抽象程度非常低。这就造成了一个问题,即非结构化数据的种类是随着各个领域的数字化程度加深而与日俱增的。如果将映射函数内置于搜索引擎,就意味着搜索引擎在设计上需要考虑各类非结构化数据的具体语义。这一点所引发的系统复杂性增长,几乎是致命的。我们在项目早期尝试过将一些典型场景下的典型数据类型引入搜索引擎,但依然发现这在工程层面非常困难,很难通过一套简洁的框架来处理这些语义迥异但抽象程度又较低的数据类型。
其次需要考虑的问题是数据到向量空间的映射多样性。由于现在的搜索场景越来越复杂,所引入的数据处理方法与模型也越来越丰富。所需要的函数能力远超搜索引擎内置函数或自定义函数插件的能力范围。目前常见的做法是依靠大数据处理与AI两个生态上的工具来完成原始数据到向量空间的映射,如Spark、Pytorch、Tensorflow、Keras等。因此,将映射函数移至搜索引擎外,实际上决定了搜索引擎与大数据系统生态、AI系统生态的对接关系。
值得注意的是,虽然映射的部分有丰富的系统生态做支撑,但在应对具体的搜索问题时,仍然需要做很多定向的开发。这一点,并没有像搜索引擎的内置函数或UDF那样便利。以我们目前的经验来看,垂直领域内的典型场景是可以抽象出很多公共的处理流程的。我们也高兴的发现,当前一些开源项目已经着手补全这些拼图,如JINA等。
在剥离出“数据到向量空间的映射函数”后,搜索引擎的数据类型变得非常简洁,在传统的抽象类型之上,我们只需增加一类抽象类型 --- 向量。在搜索引擎内部,主要考虑向量空间上的操作,包括向量的存储、距离的计算、搜索过程的优化。由于映射过程完全透明,搜索引擎不依赖“映射语义”(如文本搜索中某个词会被映射至某个维度)对搜索过程进行优化。所采用的思路是直接基于“相似性语义”构建索引系统。以向量间的两两“距离”作为度量,搜索引擎将向量按聚类或图组织成索引。相应的搜索过程对应着聚类的部分遍历或图的部分遍历。
总结下来,泛化的模型的主要特点如下:
向量空间:维度与隐式的语义相对应,
数据到向量空间的映射:基于神经网络或垂直领域的定制模型、与搜索引擎充分解耦,
相关性搜索:以聚类或图进行数据组织。

小结
我们从向量空间的角度出发,分析了文本搜索模型,并结合当前的搜索场景,讨论了搜索能力泛化所需解决的问题,最后给出了泛化的非结构化数据搜索模型。
致谢
感谢吴一凡同学的精美配图,以及易小萌博士、星爵同学对文章的修改建议。
作者简介:郭人通,ZILLIZ合伙人,系统架构师。华中科技大学计算机软件与理论博士。


?新iPhone有望首次加入屏下指纹解锁;小米 11推送“降温”补丁;McAfee杀毒软件创始人死于巴塞罗那监狱中|极客头条
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675