大数据文摘授权转载自数据实战派
原文:High Performance Deep Learning
作者:Gaurav Menghani(谷歌研究院 | 软件工程师)
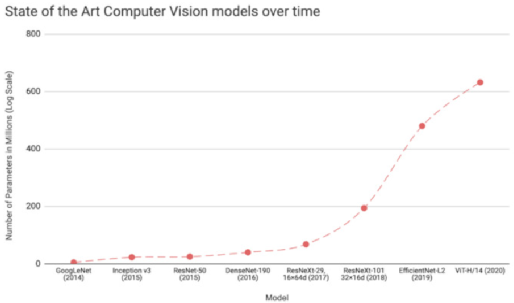
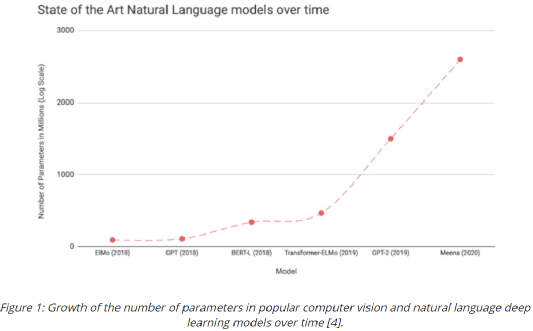
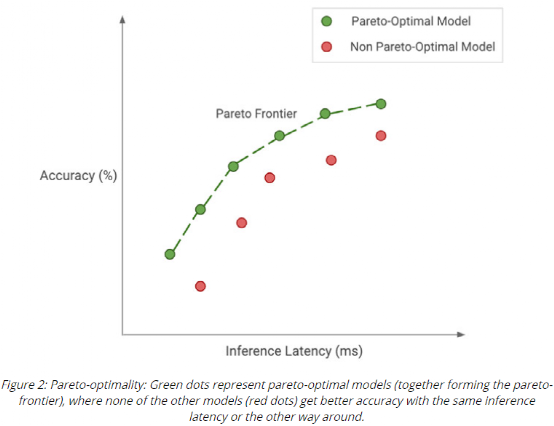
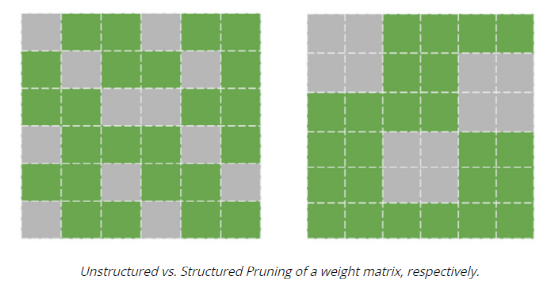
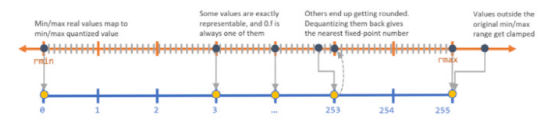
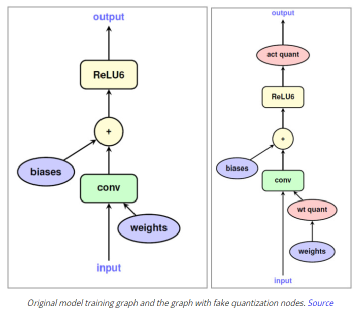
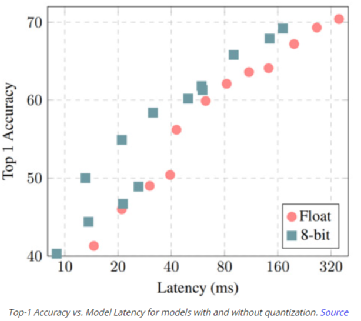
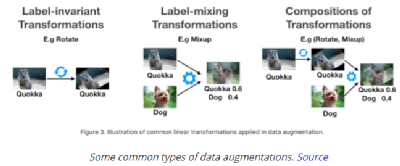
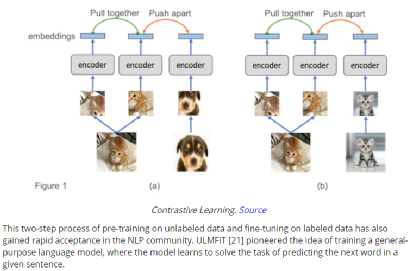
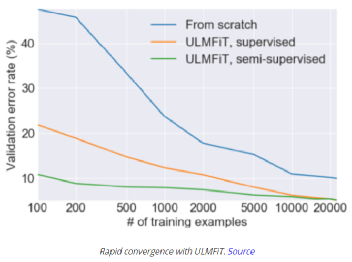
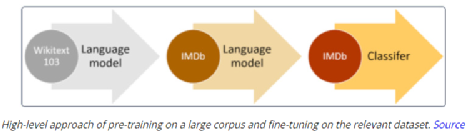
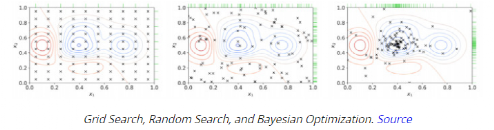
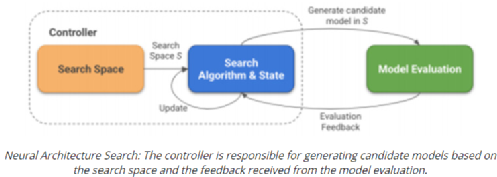
深度学习技术的突破性进展彰显了其令人难以置信的潜力,提供了让人兴奋的新的 AI 增强软件和系统。但是,从财政、计算再到环境等几个角度上考虑,训练最强大的模型是极其昂贵的。提高这些模型的效率会在很多领域产生深远的影响,因此,基于这一需求,未来所开发的模型只会有助于进一步扩大深度学习所提供的范围、适用性和价值。本文将基于 arxiv 论文 Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better,首先展示深度学习领域模型的快速增长,及其在继续扩大规模的阶段激发了对效率和性能的需求。随后将给出一个基本框架,介绍实现高效深度学习的可用工具和技术,并进一步为每个重点领域提供详细的示例,盘点工业界和学术界迄今为止的重要探索。如今,无数应用中都有着机器学习的身影。过去十年中,采用神经网络的深度学习一直是训练新机器学习模型的主要方法。它的崛起通常要归功于 2012 年举办的 ImageNet 竞赛。就在同年,多伦多大学的一支团队提交了一个名为 AlexNet (以首席开发人员 Alex Krizhevsky 命名)的深度卷积网络(deep convolutional network),比接下来提交的最好成绩还要高出 41%。在此之前,人们曾尝试过深度和卷积的网络,但不知为何从未兑现承诺。90 年代,卷积层的概念最早由 LeCun 等人提出。类似地,若干神经网络也在 80 年代、90 年代陆续地进入大众视野。究竟是何原因让深度网络花费如此长的时间才超越手工调优的特征工程(feature-engineered)模型呢?1. 计算(Compute):AlexNet 是早期依赖图形处理单元(GPU, Graphics Processing Units)进行训练的模型之一。2. 算法(Algorithms):采用 ReLU 作为激活函数,使得梯度反向传播地更深。先前的深度网络迭代采用的是 Sigmoid 或 Tanh 激活函数,除了很小的输入范围外,在 1.0 或 - 1.0 处达到饱和。因此,改变输入变量会导致非常微小的梯度,而当存在很多层时,梯度基本上就消失了。三个激活函数的图像如下所示:简言之,ReLU 不会出现梯度消失的问题,而且从计算的角度上看,Sigmoid 和 Tanh 激活函数均需要计算指数,复杂度高,而 ReLU 通过简单的阈值便可得到激活值。3. 数据(Data):ImageNet(全球最大的图像识别数据库)包含有 > 1M 的数千个类型、数百张有标注的图像。随着互联网产品的出现,从用户行为中收集标注数据的成本也不断降低。鉴于这一开拓性的工作,人们竞相使用越来越多的参数来创建更深层的网络。如 VGGNet、Inception,、ResNet 等模型架构,在随后的几年里相继打破了以往 ImageNet 的竞赛记录。如今,这些模型也已在现实世界中进行了部署。我们在自然语言理解(NLU, Natural Language Understanding)领域也看到了类似的效果,Transformer 架构在 GLUE 任务上显著优于之前的基准测试。随后,BERT 和 GPT 模型都演示了在 NLP 相关任务上的改进,并且 BERT 衍生了几个相关的模型架构,对其各个方面进行了优化。而 GPT-3 只需要给定的提示便可续写生动逼真的故事,作为最强的文本生成模型成功地引发了人们的关注。在谷歌搜索引擎(Google Search)中使用 BERT 可以提高结果的相关性,而 GPT-3 可作为 API 供感兴趣的用户使用。可以推断,深度学习研究一直关注于改善现有的技术水平,因此,我们看到了在图像分类、文本分类等基准上的不断优化。神经网络的每一次新突破都会导致网络复杂性、参数数量、训练网络所需的训练资源数量以及预测延迟等方面的增加。现在,诸如 GPT-3 的自然语言模型仅训练一次迭代都要花费数百万美元,而且其中还不包括尝试不同的超参组合(微调)或手动 / 自动运行调试模型架构的成本。毫不夸张地说,这些模型的参数数量高达数十亿甚至数万亿。与此同时,这些模型令人难以置信的性能也催生出将其应用于新任务的需求,力求突破现有的技术瓶颈。这就产生了一个有趣的问题,这些模型的传播速度会受其效率的限制。更具体地说,随着深度学习新时代的到来,以及模型变得越来越大并在不同的领域传播,我们难免会面临着以下问题:1. 可持续的服务器端扩展(Sustainable Server-Side Scaling):训练和部署大型深度学习模型的成本很高。虽然训练可能只是一次性成本(如果使用预训练的模型可能是免费的),但是部署和让推理持续很长时间段仍可能很昂贵。此外,对用于培训和部署这些大型模型的数据中心的碳足迹(carbon footprint),也是一种非常现实的担忧。像谷歌、Facebook、亚马逊等大型组织每年在其数据中心上的资本支出高达数十亿美元。因此,任何效率的提高都是非常显著的。2. 启用设备部署(Enabling On-Device Deployment):随着智能手机和物联网设备(IoT devices)的出现,其上部署的应用程序必须是实时的。因此,对设备上的 ML 模型便产生了一定的需求(其中模型推理直接发生在设备上),这就使得优化它们将要运行设备的模型成为当务之急。3. 隐私和数据敏感性(Privacy & Data Sensitivity):当用户数据可能对处理 / 受到各种限制(如欧洲 GDPR 法律)敏感时,能够使用少量数据进行训练是至关重要的。因此,用一小部分数据有效地训练模型就意味着需要更少的数据收集。类似地,启用设备上的模型意味着模型推理可以完全在用户的设备上运行,而无需再将输入数据发送到服务器端。4. 新应用程序(New Applications):效率还可以启用在现有资源约束下无法执行的应用程序。5. 模型爆炸(Explosion of Models):通常,在同一设备上可能并发地提供多个 ML 模型。这便进一步减少了单个模型的可用资源。这可能发生在服务器端,其中多个模型可能位于同一台机器上,也可能位于用于不同功能的不同模型的应用程序中。我们所确定的核心挑战是效率。效率可能是一个看似宽泛的术语,我们此处明确了需要重点调查研究的两个方面。1. 推理效率(Inference Efficiency):这主要处理部署用于推理的模型(依据给定输入计算模型输出)的人可能会提及的问题。比如,这种模型小吗?快不快?具体来说,这个模型包含多少参数?磁盘大小、推理阶段的 RAM 消耗、推理延迟各为多少呢?2. 训练效率(Training Efficiency):这涉及到训练模型的人可能提问的问题,比如模型训练需要多长时间?训练需要多少设备?模型能适应内存吗?此外,还可能包括以下问题,模型需要多少数据才能在给定任务上实现预期的性能呢?如果在给定的任务上有两个同样出色的模型,可能想要选择其中一个更好地、更为理想的模型,在上述两个方面都可以做到最佳。如果要在推理受到限制的设备(如移动和嵌入式设备)或昂贵的设备(云服务器)上部署模型,则需要注意推理效率。同样地,如果一个人要用有限或昂贵的训练资源上从头开始训练一个大型模型,那么开发旨在提高训练效率的模型将会有所帮助。无论优化的目标是什么,我们都希望达到最佳效果。这意味着,选择的任何模型对于所关注的权衡而言都是最好的。作为图 2 中的一个例子,绿点表示帕累托最优(pareto-optimal)模型,其中没有其他模型(红点)在相同推理延迟或相反的情况下获得更高的准确性。与此同时,帕累托最优模型(绿点)形成所谓的帕累托边界。根据定义,帕累托边界模型比其他模型更有效,因为它们在给定的权衡下表现最好。因此,当寻求效率时,更应该将帕累托相关的最新发现和进展放在考虑范围之内。反过来,高效的深度学习可被定义为一组算法、技术、工具和基础结构的集合,它们可以协同工作,允许用户训练和部署帕累托最优模型,这些模型只需花费更少的资源来训练和 / 或部署,同时实现类似的结果。在关注模型质量的同时,其效率方面也不容忽视。当一个组织开始考虑构建高效的深度学习模型,以通过方案提高交付能力时,这些执行方案所需的软件和硬件工具便是实现高性能的基础。接下来,本文将大致分为以下两部分进行介绍:首先是建模技术的四大支柱 ——?压缩技术(Compression Techniques)、学习技巧(Learning Techniques)、自动化(Automation)、高效模型的架构和层(Efficient Model Architectures & Layers),然后是已有的基础设施与硬件基础。如先前所述,压缩技术作为通用技术可以帮助神经网络实现一层或多层的更有效表示,但可能会在质量上有所取舍。效率可以来自于改进一个或多个足迹指标,如模型大小、推理延迟、收敛所需的训练时间等,以尽可能换取少的质量损失。通常,模型可能被过度参数化(over-parameterized)。在这种情况下,这些技术还有助于改进对未知数据的泛化。(1)剪枝(Pruning):这是一种流行的压缩技术,我们可以对无关紧要的网络连接进行剪枝,从而使网络变得稀疏。LeCun 等人在其所发表的题为 “最优脑损伤”(OBD, Optimal Brain Damage)的论文中,将神经网络中的参数(层间连接)减少了 4 倍,同时还提高了推理速度和泛化能力。Hassibi 等人和 Zhu 等人在 OBD 方法的基础上提出了 Optimal Brain Surgeon 工作,这是一种性能较好的网络剪枝技术,利用误差函数的二次导数信息,解析预测权值扰动对函数的影响程度,以自顶向下的方式削弱或消除部分连接权,实现网络的结构化。这些方法采用预训练到合理质量的网络,然后迭代删除显著性得分最低的参数,显著性得分用于衡量特定连接的重要性,这样对验证损失的影响就会最小化。一旦剪枝结束,网络就会用剩余的参数进行微调。重复这个过程,直到网络被剪枝到所需的级别。l 显著性(Saliency):这是决定应该剪枝哪个连接的启发式方法。这可以基于连接权相对于损失函数的二阶导数,连接权的大小等等。l 非结构化 v/s 结构化(Unstructured v/s Structured):非结构化剪枝是剪枝方法中最灵活的一种,对于所有给定的参数都是 “一视同仁”。而在结构化剪枝中,参数在 size> 1 的块中进行修剪(例如在权矩阵中进行 row-wise 修剪或在卷积滤波器中进行 channel-wise 修剪)。结构化剪枝允许在大小和延迟方面更容易地利用推理时间,因为这些修剪后的参数块可以被智能地跳过以进行存储和推理。l 分布(Distribution):可以在每层设置相同的剪枝预算,或者在每层的基础上进行分配。经验直觉告诉我们,某些层相对来说更容易剪枝一些。例如,通常情况下,前几层如果足够小,则无法容忍显著的稀疏。l 调度(Scheduling):然而,额外的标准是该剪枝多少以及何时进行呢?我们是想在每轮中修剪等量的参数,还是在剪枝开始时较快,然后逐渐放慢呢?l 再生(Regrowth):在某些情况下,允许网络再生剪枝的连接,这样网络就会以相同百分比的连接剪枝不断运行。就实际使用而言,具备有意义的块大小的结构化剪枝可以辅助提高延迟。在保留相同 Top-1 精度的情况下,Elsen 等人构建的稀疏卷积网络使用约 66% 的参数,比稠密网络高出 1.3 - 2.4 倍。他们通过其库将 NHWC(输入数据格式:channels-last)标准密集表示转换为特殊的 NCHW(channels-first)“块压缩稀疏行” (BCSR, Block Compressed Sparse Row)表示,这适用于使用其高速内核在 ARM 设备、WebAssembly(相对 JavaScript 而言的另一种可以在浏览器中执行的编程语言)等上的进行快速推理。尽管他们也引入了一些约束以限制可加速的稀疏网络类型,但总的来说,这是朝着实际改进剪枝网络的足迹指标迈出的有希望的一步。(2)量化(Quantization):量化是另一种非常流行的压缩技术。它沿用了这样一种思路,即典型网络中几乎所有权值都是 32 位浮点值,如果我们愿意降低一些模型质量的话,如准确率、精度、召回率等指标,便可实现以较低精度的格式(16 位、8 位、4 位等)来存储这些值。例如,当模型持久化时,以将权值矩阵(weight matrix)中的最小值映射为 0,而将最大值映射为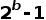 (其中 b 是精度位数),并线性地将它们之间的所有值外推(extrapolate)为整数。通常,这足以减少模型的大小。例如,如果 b = 8,则将 32 位浮点权值映射为 8 位无符号整数(unsigned integers),该操作可以将空间减少 4 倍。在进行推理(计算模型预测)时,我们可以使用数组的量化值和最小 & 最大浮点值恢复原始浮点值(由于舍入误差)的有损表示(lossy representation)。鉴于要量化模型的权重,于是此步被称为权重量化(Weight Quantization)。由于大量的参数,有损表示和舍入误差对于内置冗余的大型网络可能问题不大,但对于小型网络而言,由于其对误差的敏感性强,可能会降低精度。可以以实验的方式模拟训练过程中权重量化的舍入行为来解决这个问题。通过在模型训练图中添加节点来量化和反量化(dequantize)激活函数和权重矩阵,这样神经网络操作的训练时间输入看起来与推理阶段相同。这种节点称为伪量化(Fake Quantization)节点。这种训练方式使得网络对推理模式下的量化行为具有更强的鲁棒性。请注意,现在正在训练中进行激活量化(Activation Quantization)和权重量化。Jacob 等人和 krishnamoori 等人详细描述了训练时间模拟量化这一步骤。由于权值和激活都是在模拟的量化模式下运行的,这意味着所有层接收的输入都可以以较低的精度表示,在模型经过训练后,它应该具备很强的鲁棒性,能够直接在低精度下执行数学运算。例如,如果我们训练模型在 8 位域中复制量化,则可以部署该模型对 8 位整数执行矩阵乘法和其他操作。在诸如移动、嵌入式和物联网设备之类的资源受限的设备上,使用 GEMMLOWP 等库可以将 8 位操作提速 1.5 - 2 倍,这些库依赖于硬件支持,如 ARM 处理器上的 Neon intrinsic。此外,Tensorflow Lite 等框架允许用户直接使用量化操作,而不必为底层实现而烦恼。除了剪枝和量化,还有其他一些技术,如低秩矩阵分解、K-Means 聚类、权值共享等等,这些技术在模型压缩领域也十分活跃。总的来说,压缩技术可以用来减少模型的足迹(大小、延迟等),同时换取一些质量(准确性、精度、召回率等)的提升。(1)蒸馏(Distillation):如前所述,学习技术尝试以不同的方式训练模型,以获得最佳性能。例如,Hinton 等人在其开创性工作中探索了如何教会小型网络从大型网络 / 大型网络的集合中提取暗知识(dark knowledge| Hinton said: “Dark knowledge is the most of what deep learning methods actually learn”)。他们使用一个更大的教师模型(teacher model)在现有标签数据生成软标签。软标签为原始数据中的每个可能的类别分配概率,而不是硬二进制值。直觉上,这些软标签捕获了模型可以学习的不同类之间的关系。例如,卡车更像汽车而非苹果,这一模型可能无法直接从硬标签中学习。学生网络(student network)学习最小化这些软标签的交叉熵损失(cross-entropy loss),以及原始真实的硬标签。损失函数的每个权重可以根据实验结果进行缩放。Hinton 等人曾在论文中表示,能够用一个蒸馏模型来接近 10 个模型集成的语音识别任务的准确性。其他综合研究表明,小型模型质量有着显著提高。简单举个例子,Sanh 等人能够蒸馏一个学生模型,该模型保留了 BERT-Base 97% 的性能,同时在 CPU 上的占用率要少 40%,而速度上快约 60%。(2)数据增强(Data Augmentation):通常对于大型模型和复杂任务来说,拥有的数据越多,改进模型性能的机会就越大。然而,常常采用 “人在回路”(human in the loop)的解决办法,所以获取高质量的标记数据通常既缓慢又昂贵。监督学习就是从这些人工标注的数据中学习。当有资源支付标注费用的时候,它非常有效,但我们能够且应该做得更好。数据增强主要指在计算机视觉领域中对图像进行数据增强,从而弥补训练图像数据集不足,达到对训练数据扩充的目的,进而提升模型的性能。通常,它涉及到对数据进行转换,这样就不需要重新标注,该过程成为标签不变转换(label-invariant transformations)。例如,如果您正在教神经网络对包含狗或猫的图像进行分类,旋转图像将不会改变标签。此外,其他的转换形式还有水平 / 垂直翻转、拉伸、裁剪、添加高斯噪声等。类似地,如果您正在检测给定文本的情感倾向性,引入拼写错误可能不会改变标签。这种标签不变转换已经在流行的深度学习模型中广泛使用。当您有大量的类和 / 或特定类的示例很少时,它们尤其方便。还有其他转换方式,如 Mixup,它以加权的方式混合来自两个不同类的输入,并将标签视为两个类的类似加权组合。其思想是,模型应该能够提取出与这两个类相关的特性。这些技术将数据效率引入到 pipeline 中。这和教孩子在不同的上下文中识别现实生活中的物体实质上没有太大的区别。(3)自监督学习(Self-Supervised Learning):在邻近的领域有了快速的进展,我们可以学习一些通用模型,这些模型完全不需要使用标注来从数据中提取意义。采用对比学习(contrastive learning)这样的方法,我们可以训练一个模型,使它学习输入的表示,这样类似的输入将有类似的表示,而不相关的输入会生成明显差异的表示。其中,这些表示是 n 维向量(embeddings),在我们可能没有足够的数据来从头训练模型的其他任务中,它可以作为有用的特征。我们可以把使用未标注数据的第一步看作是预训练,下一步视为微调。这种对未标注数据进行预训练和对标注数据进行微调的两步过程也迅速得到了 NLP 社区的认可。ULMFiT 率先提出了训练通用语言模型的想法,该模型学习如何解决预测给定句子中的下一个单词的任务。我们发现,使用大量预处理但未标注的数据,如 WikiText-103(源自英文维基百科页面),是预训练步骤的一个不错的选择。这就足以让模型学习语言的一般属性。此外,对于二进制分类问题,微调这种预训练模型只需要 100 个标注示例,而相比之下,其他情况则需要 10000 个标注的示例。该想法也在 BERT 模型中进行了探索,其中预训练步骤涉及学习双向掩码语言模型(Masked Language Model),使得模型必须在句子中预测缺失的单词。总的来说,学习技术有助于我们在不影响足迹的情况下提高模型质量。这可以用于改进部署的模型质量。如果原始模型的质量令人满意的话,你还可以通过简单地减少网络中的参数数量来交换新获得的质量收益,以改进模型大小和延迟,直到回到最低可行的模型质量。有了正确的软件、硬件和技术以后,有效地开发高性能模型的能力,现在取决于如何利用自动化来加速实验过程,并构建最高效的数据模型架构。如果让自动化帮助网络设计和调优,它将大大减少人类的参与成本和随之而来的偏见。然而,其随之而来的代价是计算成本增加。(1)超参数优化(Hyper-Parameter Optimization):属于此类工作的常用方法之一是超参数优化(HPO, Hyper-Parameter Optimization)。调整超参数(如初始学习率,权值衰减等)对于加快收敛速度至关重要。当然,还有一些决定网络架构的参数,比如全连接层的数量,卷积层中的过滤器数量等等。虽然我们可以通过实验建立直觉思维,但找到最佳超参数值需要手动搜索能够优化给定目标函数的准确值,往往是验证集上的损失值。如果用户之前对超参数调优有经验,那么可以使用网格搜索算法(Grid Search,也称为参数扫描)来自动化 HPO。在这种情况下,根据用户提供的每个参数的有效范围搜索给定超参数的所有独特且有效的组合。例如,如果学习率(lr, learning rate)的可能值为 {0.01,0.05},权重衰减(weight decay)的可能值为 {0.1,0.2},则有 4 种可能的组合:{lr=0.01, decay=0.1}、{lr=0.01, decay=0.2}、{lr=0.05, decay=0.1} 和 {lr=0.05, decay=0.2}。以上每种组合都是一次试验,然后每次试验都可以并行运行。一旦所有试验完成,超参数的最优组合便被找到。由于该方法会尝试所有可能的组合,尝试总数增长非常快,因此遭受维度的诅咒。另一种方法是随机搜索(Random Search),其中从用户提供的可能值范围所构建的搜索空间中进行随机采样试验。类似于网格搜索,每个试验仍然是独立并行运行。然而,鉴于试验独立同分布(iid, ?independently and identically distributed)的特点,随机搜索很容易根据可用的计算能力进行扩展,从而找到最优试验的可能性随着试验次数的增加而增加。如果到目前为止最好的试验足够好,这就允许预先搜索。整个超参搜索的过程可视为一个在有限资源限制下的优化问题,在资源分配方面,类似于随机搜索的典型算法有 SHA(succession Halving)和 HyperBand,可以把更多的资源分配给精度更高或者优化速度更快的算法。基于贝叶斯优化(BO, Bayesian Optimization)的搜索是一种更好的调优方法,它保留了一个单独的模型以用于预测给定的试验是否有可能改进到目前为止发现的最佳试验。该模型学会根据过去试验的表现来预测可能性。BO 优于随机搜索,因为前者具有一定的导向性。因此,需要更少的试验就可以达到最佳。由于试验的选择依赖于过去试验的结果,因此该方法是顺序的。然而,与纯粹逻辑的 BO 相比,可以在同一时间并行地产生多个试验(基于相同的估计),这可能引发更快的收敛,其代价可能是一些浪费的试验。在实际使用方面,HPO 可以通过几个软件工具包提供给用户,这些工具包包括算法本身以及一个易于使用的界面(指定超参数及其范围),包括 Vizier [8](一个内部谷歌工具,也可以通过谷歌云进行黑箱调优)。亚马逊提供了 Sagemaker,其功能类似,也可以作为 AWS(Amazon Web Services)服务访问。NNI、Tune 和 Advisor 是其他可以在本地使用的开源 HPO 软件包。这些工具包为不乐观的早期停止策略提供了一个选项。Vizier 使用中位数停止规则,如果一个试验在时间步长 t 上的性能低于所有试验运行到该时间点的中位数性能,则终止试验。(2)神经架构搜索(NAS, Neural Architecture Search):可以把 NAS 看作是 HPO 的扩展版本,在其中搜索改变网络架构本身的参数。NAS 可考虑由以下部分组成:丨搜索空间(Search Space):卷积、全连接、池化等操作及其相互连接是图中允许的神经网络操作。这都是由用户提供的。丨搜索算法和状态(Search Algorithm & State):这是控制架构搜索本身的算法。通常,适用于 HPO 的标准算法(网格搜索、随机搜索、贝叶斯优化和进化算法等)也同样可用于 NAS,以及强化学习(Reinforcement Learning)和梯度下降(Gradient Descent)。丨评估策略(Evaluation Strategy):这定义了用于评估模型适合的度量指标。它可以是简单的常规度量,如验证损失(validation loss)、准确性(accuracy)等;或者也可以是一个复合度量(compound metric),如 MNasNet,可以根据精度和模型延迟创建单一的定制度量指标。具有搜索空间和状态的搜索算法可被视为生成样本候选网络的 “控制器”。评估阶段对生成的候选进行适合的训练和评估,然后将这个适应值(fitness value)作为反馈传递给搜索算法,该算法将使用它来生成更好的候选对象。Zoph 等人在 2016 年发表的论文中证明,端到端神经网络架构可以通过强化学习生成。在这种情况下,控制器本身就是一个递归神经网络(RNN, Recurrent Neural Network),它一次生成一层前馈网络的架构超参数,如滤波器数量、步幅、滤波器大小等。训练控制器本身很昂贵(需要 22400 个 GPU 小时),因为整个候选网络必须从头开始训练,才能实现单一的梯度更新。在后续论文中,作者改进了搜索空间以搜索单元(cells):一个 “正常单元”(Normal Cell),可以接收输入,处理并返回相同空间维度的输出。“缩减单元”(Reduction Cell)处理其输入并返回其空间维度按比例缩小 2 倍的输出。每个单元都是
(其中 b 是精度位数),并线性地将它们之间的所有值外推(extrapolate)为整数。通常,这足以减少模型的大小。例如,如果 b = 8,则将 32 位浮点权值映射为 8 位无符号整数(unsigned integers),该操作可以将空间减少 4 倍。在进行推理(计算模型预测)时,我们可以使用数组的量化值和最小 & 最大浮点值恢复原始浮点值(由于舍入误差)的有损表示(lossy representation)。鉴于要量化模型的权重,于是此步被称为权重量化(Weight Quantization)。由于大量的参数,有损表示和舍入误差对于内置冗余的大型网络可能问题不大,但对于小型网络而言,由于其对误差的敏感性强,可能会降低精度。可以以实验的方式模拟训练过程中权重量化的舍入行为来解决这个问题。通过在模型训练图中添加节点来量化和反量化(dequantize)激活函数和权重矩阵,这样神经网络操作的训练时间输入看起来与推理阶段相同。这种节点称为伪量化(Fake Quantization)节点。这种训练方式使得网络对推理模式下的量化行为具有更强的鲁棒性。请注意,现在正在训练中进行激活量化(Activation Quantization)和权重量化。Jacob 等人和 krishnamoori 等人详细描述了训练时间模拟量化这一步骤。由于权值和激活都是在模拟的量化模式下运行的,这意味着所有层接收的输入都可以以较低的精度表示,在模型经过训练后,它应该具备很强的鲁棒性,能够直接在低精度下执行数学运算。例如,如果我们训练模型在 8 位域中复制量化,则可以部署该模型对 8 位整数执行矩阵乘法和其他操作。在诸如移动、嵌入式和物联网设备之类的资源受限的设备上,使用 GEMMLOWP 等库可以将 8 位操作提速 1.5 - 2 倍,这些库依赖于硬件支持,如 ARM 处理器上的 Neon intrinsic。此外,Tensorflow Lite 等框架允许用户直接使用量化操作,而不必为底层实现而烦恼。除了剪枝和量化,还有其他一些技术,如低秩矩阵分解、K-Means 聚类、权值共享等等,这些技术在模型压缩领域也十分活跃。总的来说,压缩技术可以用来减少模型的足迹(大小、延迟等),同时换取一些质量(准确性、精度、召回率等)的提升。(1)蒸馏(Distillation):如前所述,学习技术尝试以不同的方式训练模型,以获得最佳性能。例如,Hinton 等人在其开创性工作中探索了如何教会小型网络从大型网络 / 大型网络的集合中提取暗知识(dark knowledge| Hinton said: “Dark knowledge is the most of what deep learning methods actually learn”)。他们使用一个更大的教师模型(teacher model)在现有标签数据生成软标签。软标签为原始数据中的每个可能的类别分配概率,而不是硬二进制值。直觉上,这些软标签捕获了模型可以学习的不同类之间的关系。例如,卡车更像汽车而非苹果,这一模型可能无法直接从硬标签中学习。学生网络(student network)学习最小化这些软标签的交叉熵损失(cross-entropy loss),以及原始真实的硬标签。损失函数的每个权重可以根据实验结果进行缩放。Hinton 等人曾在论文中表示,能够用一个蒸馏模型来接近 10 个模型集成的语音识别任务的准确性。其他综合研究表明,小型模型质量有着显著提高。简单举个例子,Sanh 等人能够蒸馏一个学生模型,该模型保留了 BERT-Base 97% 的性能,同时在 CPU 上的占用率要少 40%,而速度上快约 60%。(2)数据增强(Data Augmentation):通常对于大型模型和复杂任务来说,拥有的数据越多,改进模型性能的机会就越大。然而,常常采用 “人在回路”(human in the loop)的解决办法,所以获取高质量的标记数据通常既缓慢又昂贵。监督学习就是从这些人工标注的数据中学习。当有资源支付标注费用的时候,它非常有效,但我们能够且应该做得更好。数据增强主要指在计算机视觉领域中对图像进行数据增强,从而弥补训练图像数据集不足,达到对训练数据扩充的目的,进而提升模型的性能。通常,它涉及到对数据进行转换,这样就不需要重新标注,该过程成为标签不变转换(label-invariant transformations)。例如,如果您正在教神经网络对包含狗或猫的图像进行分类,旋转图像将不会改变标签。此外,其他的转换形式还有水平 / 垂直翻转、拉伸、裁剪、添加高斯噪声等。类似地,如果您正在检测给定文本的情感倾向性,引入拼写错误可能不会改变标签。这种标签不变转换已经在流行的深度学习模型中广泛使用。当您有大量的类和 / 或特定类的示例很少时,它们尤其方便。还有其他转换方式,如 Mixup,它以加权的方式混合来自两个不同类的输入,并将标签视为两个类的类似加权组合。其思想是,模型应该能够提取出与这两个类相关的特性。这些技术将数据效率引入到 pipeline 中。这和教孩子在不同的上下文中识别现实生活中的物体实质上没有太大的区别。(3)自监督学习(Self-Supervised Learning):在邻近的领域有了快速的进展,我们可以学习一些通用模型,这些模型完全不需要使用标注来从数据中提取意义。采用对比学习(contrastive learning)这样的方法,我们可以训练一个模型,使它学习输入的表示,这样类似的输入将有类似的表示,而不相关的输入会生成明显差异的表示。其中,这些表示是 n 维向量(embeddings),在我们可能没有足够的数据来从头训练模型的其他任务中,它可以作为有用的特征。我们可以把使用未标注数据的第一步看作是预训练,下一步视为微调。这种对未标注数据进行预训练和对标注数据进行微调的两步过程也迅速得到了 NLP 社区的认可。ULMFiT 率先提出了训练通用语言模型的想法,该模型学习如何解决预测给定句子中的下一个单词的任务。我们发现,使用大量预处理但未标注的数据,如 WikiText-103(源自英文维基百科页面),是预训练步骤的一个不错的选择。这就足以让模型学习语言的一般属性。此外,对于二进制分类问题,微调这种预训练模型只需要 100 个标注示例,而相比之下,其他情况则需要 10000 个标注的示例。该想法也在 BERT 模型中进行了探索,其中预训练步骤涉及学习双向掩码语言模型(Masked Language Model),使得模型必须在句子中预测缺失的单词。总的来说,学习技术有助于我们在不影响足迹的情况下提高模型质量。这可以用于改进部署的模型质量。如果原始模型的质量令人满意的话,你还可以通过简单地减少网络中的参数数量来交换新获得的质量收益,以改进模型大小和延迟,直到回到最低可行的模型质量。有了正确的软件、硬件和技术以后,有效地开发高性能模型的能力,现在取决于如何利用自动化来加速实验过程,并构建最高效的数据模型架构。如果让自动化帮助网络设计和调优,它将大大减少人类的参与成本和随之而来的偏见。然而,其随之而来的代价是计算成本增加。(1)超参数优化(Hyper-Parameter Optimization):属于此类工作的常用方法之一是超参数优化(HPO, Hyper-Parameter Optimization)。调整超参数(如初始学习率,权值衰减等)对于加快收敛速度至关重要。当然,还有一些决定网络架构的参数,比如全连接层的数量,卷积层中的过滤器数量等等。虽然我们可以通过实验建立直觉思维,但找到最佳超参数值需要手动搜索能够优化给定目标函数的准确值,往往是验证集上的损失值。如果用户之前对超参数调优有经验,那么可以使用网格搜索算法(Grid Search,也称为参数扫描)来自动化 HPO。在这种情况下,根据用户提供的每个参数的有效范围搜索给定超参数的所有独特且有效的组合。例如,如果学习率(lr, learning rate)的可能值为 {0.01,0.05},权重衰减(weight decay)的可能值为 {0.1,0.2},则有 4 种可能的组合:{lr=0.01, decay=0.1}、{lr=0.01, decay=0.2}、{lr=0.05, decay=0.1} 和 {lr=0.05, decay=0.2}。以上每种组合都是一次试验,然后每次试验都可以并行运行。一旦所有试验完成,超参数的最优组合便被找到。由于该方法会尝试所有可能的组合,尝试总数增长非常快,因此遭受维度的诅咒。另一种方法是随机搜索(Random Search),其中从用户提供的可能值范围所构建的搜索空间中进行随机采样试验。类似于网格搜索,每个试验仍然是独立并行运行。然而,鉴于试验独立同分布(iid, ?independently and identically distributed)的特点,随机搜索很容易根据可用的计算能力进行扩展,从而找到最优试验的可能性随着试验次数的增加而增加。如果到目前为止最好的试验足够好,这就允许预先搜索。整个超参搜索的过程可视为一个在有限资源限制下的优化问题,在资源分配方面,类似于随机搜索的典型算法有 SHA(succession Halving)和 HyperBand,可以把更多的资源分配给精度更高或者优化速度更快的算法。基于贝叶斯优化(BO, Bayesian Optimization)的搜索是一种更好的调优方法,它保留了一个单独的模型以用于预测给定的试验是否有可能改进到目前为止发现的最佳试验。该模型学会根据过去试验的表现来预测可能性。BO 优于随机搜索,因为前者具有一定的导向性。因此,需要更少的试验就可以达到最佳。由于试验的选择依赖于过去试验的结果,因此该方法是顺序的。然而,与纯粹逻辑的 BO 相比,可以在同一时间并行地产生多个试验(基于相同的估计),这可能引发更快的收敛,其代价可能是一些浪费的试验。在实际使用方面,HPO 可以通过几个软件工具包提供给用户,这些工具包包括算法本身以及一个易于使用的界面(指定超参数及其范围),包括 Vizier [8](一个内部谷歌工具,也可以通过谷歌云进行黑箱调优)。亚马逊提供了 Sagemaker,其功能类似,也可以作为 AWS(Amazon Web Services)服务访问。NNI、Tune 和 Advisor 是其他可以在本地使用的开源 HPO 软件包。这些工具包为不乐观的早期停止策略提供了一个选项。Vizier 使用中位数停止规则,如果一个试验在时间步长 t 上的性能低于所有试验运行到该时间点的中位数性能,则终止试验。(2)神经架构搜索(NAS, Neural Architecture Search):可以把 NAS 看作是 HPO 的扩展版本,在其中搜索改变网络架构本身的参数。NAS 可考虑由以下部分组成:丨搜索空间(Search Space):卷积、全连接、池化等操作及其相互连接是图中允许的神经网络操作。这都是由用户提供的。丨搜索算法和状态(Search Algorithm & State):这是控制架构搜索本身的算法。通常,适用于 HPO 的标准算法(网格搜索、随机搜索、贝叶斯优化和进化算法等)也同样可用于 NAS,以及强化学习(Reinforcement Learning)和梯度下降(Gradient Descent)。丨评估策略(Evaluation Strategy):这定义了用于评估模型适合的度量指标。它可以是简单的常规度量,如验证损失(validation loss)、准确性(accuracy)等;或者也可以是一个复合度量(compound metric),如 MNasNet,可以根据精度和模型延迟创建单一的定制度量指标。具有搜索空间和状态的搜索算法可被视为生成样本候选网络的 “控制器”。评估阶段对生成的候选进行适合的训练和评估,然后将这个适应值(fitness value)作为反馈传递给搜索算法,该算法将使用它来生成更好的候选对象。Zoph 等人在 2016 年发表的论文中证明,端到端神经网络架构可以通过强化学习生成。在这种情况下,控制器本身就是一个递归神经网络(RNN, Recurrent Neural Network),它一次生成一层前馈网络的架构超参数,如滤波器数量、步幅、滤波器大小等。训练控制器本身很昂贵(需要 22400 个 GPU 小时),因为整个候选网络必须从头开始训练,才能实现单一的梯度更新。在后续论文中,作者改进了搜索空间以搜索单元(cells):一个 “正常单元”(Normal Cell),可以接收输入,处理并返回相同空间维度的输出。“缩减单元”(Reduction Cell)处理其输入并返回其空间维度按比例缩小 2 倍的输出。每个单元都是关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
*文章为作者独立观点,不代表 爱尖刀 立场
本文由
大数据文摘发表,转载此文章须经作者同意,并请附上出处(
爱尖刀 )及本页链接。
原文链接 https://www.ijiandao.com/2b/baijia/413411.html





 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




