
Python实现对脑电数据情绪分析


作者|李秋键
出品|AI科技大本营(ID:rgznai100)


本次环境使用的是python3.6.5+windows平台。主要用的库有:
csv模块。CSV库在这里用来读取CSV数据集文件。其中CSV文件是逗号分隔值文件,是一种常用的文本格式,用以存储表格数据,包括数字或者字符。很多程序在处理数据时都会碰到csv这种格式的文件,它的使用是比较广泛的。
scipy模块。scipy作为高级科学计算库:和numpy联系很密切,scipy一般都是操控numpy数组来进行科学计算、统计分析,所以可以说是基于numpy之上了。scipy有很多子模块可以应对不同的应用,例如插值运算,优化算法等等。scipy则是在numpy的基础上构建的更为强大,应用领域也更为广泛的科学计算包。正是出于这个原因,scipy需要依赖numpy的支持进行安装和运行。以Python为基础的scipy的另一个好处是,它还提供了一种强大的编程语言,可用于开发复杂的程序和专门的应用程序。使用scipy的科学应用程序受益于世界各地的开发人员在软件领域的许多小众领域中开发的附加模块。
pathlib模块。该模块提供了一些使用语义表达来表示文件系统路径的类,这些类适合多种操作系统。
Pickle模块。python的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
以及其他常用模块,如OpenCV等不一一介绍了。
其中k近邻算法(k Nearest Neighbor,kNN)是一种理论上比较成熟的智能算法,最初由Cover和Hart于1968年提出。kNN算法思路简单直观:对于给定的测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。
kNN方法可以实现分类任务和回归任务。在分类任务中,一般使用“投票法”,即在k个“近邻”样本中出现最多的种类标记作为预测结果。在回归任务中,一般使用“平均法”,即将这k个样本的实值输出标记的平均值作为预测结果。在定义了相似度评价准则后,还可以基于相似度的大小进行加权投票和加权平均。相似度越大的样本权重越大。其中KNN算法分类流程如下图:

首先我们使用官方提供的EEG数据集,放置data文件夹下:

首先我们使用官方提供的EEG数据集,放置data文件夹下:
通过使用pickle实现对dat数据文件的读取,获取各个数据文件中特征向量,并在每个信道中进行fft。
其中输入:维数为N × M的通道数据,N为通道个数,M为每个通道的脑电图数据个数。
输出:维度为N x M的FFT结果。N表示信道数,M表示每个信道的FFT数据数。
关键代码如下:
for?file?in?os.listdir("../data"):
??????fname?=?Path("../data/"+file)
??????x?=?cPickle.load(open(fname,?'rb'),?encoding="bytes")
??????for?i?in?range(40):
????????????????num+=1
????????????????eeg_realtime?=?x[b'data'][i]
????????????????label?=?x[b'labels'][i]
????????????????if?label[0]?>6:
????????????????????val_v?=?3
????????????????elif?label[0]?<?4:
????????????????????val_v?=?1
????????????????else:
????????????????????val_v?=?2
????????????????if?label[1]?>?6:
????????????????????val_a?=?3
????????????????elif?label[1]?<?4:
????????????????????val_a?=?1
????????????????else:
????????????????????val_a?=?2
????????????????if?i?<?39:
????????????????????va_label.write(str(val_v)?+?",")
????????????????????ar_label.write(str(val_a)?+?",")
????????????????if?num==1280:
????????????????????va_label.write(str(val_v)?)
????????????????????ar_label.write(str(val_v)?)
????????????????eeg_raw?=?np.reshape(eeg_realtime,?(40,?8064))
????????????????eeg_raw?=?eeg_raw[:32,?:]
????????????????eeg_feature_arr?=?self.get_feature(eeg_raw)
????????????????for?f?in?range(160):
????????????????????if?f?==?159:
????????????????????????fout_data.write(str(eeg_feature_arr[f]))
????????????????????else:
????????????????????????fout_data.write(str(eeg_feature_arr[f])?+?",")
????????????????fout_data.write("\n")
????????????????print(file?+?"?Video?watched")
然后从计算fft得到所有通道的频率。输入:维数为N × M的通道数据,N为通道个数,M为每个通道的脑电图数据个数。输出:每个通道的频带:Delta, Theta, Alpha, Beta和Gamma。
#?Length?data?channel
L?=?len(all_channel_data[0])
#?Sampling?frequency
Fs?=?128
#?Get?fft?data
data_fft?=?self.do_fft(all_channel_data)
#?Compute?frequencymotio
frequency?=?map(lambda?x:?abs(x?//?L),?data_fft)
frequency?=?map(lambda?x:?x[:?L?//?2?+?1]?*?2,?frequency)
f1,?f2,?f3,?f4,?f5?=?itertools.tee(frequency,?5)
#?List?frequency
delta?=?np.array(list(map(lambda?x:?x[L?*?1?//?Fs?-?1:?L?*?4?//?Fs],?f1)))
theta?=?np.array(list(map(lambda?x:?x[L?*?4?//?Fs?-?1:?L?*?8?//?Fs],?f2)))
alpha?=?np.array(list(map(lambda?x:?x[L?*?5?//?Fs?-?1:?L?*?13?//?Fs],?f3)))
beta?=?np.array(list(map(lambda?x:?x[L?*?13?//?Fs?-?1:?L?*?30?//?Fs],?f4)))
gamma?=?np.array(list(map(lambda?x:?x[L?*?30?//?Fs?-?1:L?*?50?//?Fs],?f5)))
模型预测
从特征得到arousal值和valence值。其中Valence-Arousal分别代表情绪的正负向程度和激动程度,基于这两个维度可以构成一个情感平面空间,任何一个情感状态可以通过具体的Valence-Arousal数值,映射到VA平面空间中具体的一个点。
输入:来自所有频带和信道的特征(标准差和平均值),维度为1 × M(特征数量)。
输出:由每一种arousal和valence产生的1至3级情绪。1表示低,2表示中性,3表示高。
self.train_arousal?=?self.train_arousal[40*(index-1):40*index]
self.train_valence?=?self.train_valence[40*(index-1):40*index]
self.class_arousal?=?np.array([self.class_arousal[0][40*(index-1):40*index]])
self.class_valence?=?np.array([self.class_valence?[0][40*(index-1):40*index]])
distance_ar?=?list(map(lambda?x:?ss.distance.canberra(x,?feature),?self.train_arousal))
#?Compute?canberra?with?valence?training?data
distance_va?=?list(map(lambda?x:?ss.distance.canberra(x,?feature),?self.train_valence))
#?Compute?3?nearest?index?and?distance?value?from?arousal
idx_nearest_ar?=?np.array(np.argsort(distance_ar)[:3])
val_nearest_ar?=?np.array(np.sort(distance_ar)[:3])
#?Compute?3?nearest?index?and?distance?value?from?arousal
idx_nearest_va?=?np.array(np.argsort(distance_va)[:3])
val_nearest_va?=?np.array(np.sort(distance_va)[:3])
#?Compute?comparation?from?first?nearest?and?second?nearest?distance.、If?comparation?less?or?equal?than?0.7,?then?take?class?from?the?first?nearest?distance.?Else?take?frequently?class.
#?Arousal
comp_ar?=?val_nearest_ar[0]?/?val_nearest_ar[1]
然后从特征中获取情感类。
输入:来自所有频段和信道的特征(标准偏差),尺寸为1 × M(特征数量)。
输出:根据plex模型,情绪在1到5之间的类别。
class_ar,?class_va?=?self.predict_emotion(feature,fname)
print(class_ar,?class_va)
if?class_ar?==?2.0?or?class_va?==?2.0:
????emotion_class?=?5
if?class_ar?==?3.0?and?class_va?==?1.0:
????emotion_class?=?1
elif?class_ar?==?3.0?and?class_va?==?3.0:
????emotion_class?=?2
elif?class_ar?==?1.0?and?class_va?==?3.0:
????emotion_class?=?3
elif?class_ar?==?1.0?and?class_va?==?1.0:
????emotion_class?=?4
预测结果如下图可见:
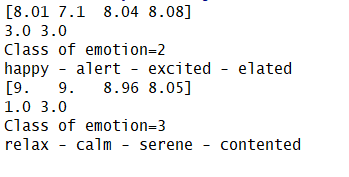

链接:
https://pan.baidu.com/s/1BX58sJv037eIJx9A8jWt3g
提取码:rwpe
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。




分享

点收藏

点点赞

点在看
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675