
自动化数据分析下的威胁发现

文|宙斯盾流量安全分析团队
彦修
不记得多早之前,大概是2020年9月3号15点37分25秒181毫秒写过一篇信息搜集过程中有关数据分析的文章(原文链接),或许有读者会问,这么精确的时间我为什么记得这么清楚,因—为—我—瞎—编—的。
言归正传,这里重点说下本篇文章,总的来说,这两篇其实都是关于数据分析的。一篇关于攻击过程中的用到的数据分析,而本篇则作为上一篇的姊妹篇,则着重讲一下在安全运营用到的数据分析,也就是企业防御;
开个头!
在正式开始文章之前,我们先来看一个包含攻击的HTTP包(源目IP等信息略去),读者不妨先思考下,从这个HTTP包中我们能得到或者还原哪些有用的信息?

一般情况下,可能会有部分读者会围绕上文中的HTTP包所展现的内容来进行分析,比如攻击手法等等,针对一些有经验的安全工程师来说甚至可以指出这是针对thinkPHP的漏洞。
但是实际上,其实有更多信息隐藏冰山之下,而想要挖掘冰山之下的信息,我们首先需要对所有的可能路径按照演进过程进行推理,我将其简化为下图:
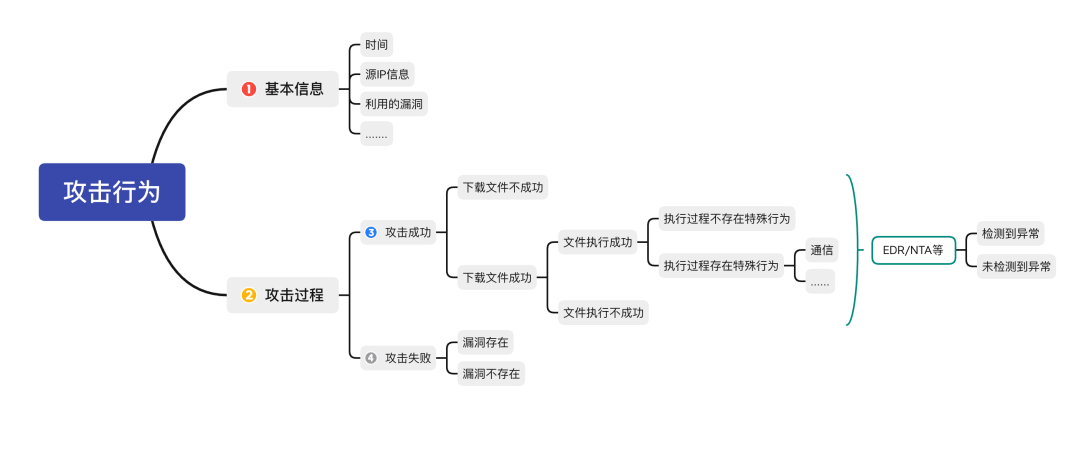
总的来说,我们获取的信息分为两类,直接信息即该HTTP包的基本信息,包括时间、攻击方式等;而间接信息则涵盖攻击后续演进过程中所有可能的信息,包括过程、进程、通信等等。
为什么要这么做呢?因为实际运营中我们发现单纯的依赖直接信息或者单纯的依赖间接信息都很难完成告警的闭环。比如以该攻击行为的直接信息为例,我们WAF每天收到类似上述的告警数不胜数,基本没有可运营性。
但是倘若我们将直接信息和间接信息通过自动化数据分析则可以做到过滤误报的同时,实现高准度的告警。
然后呢?
刚才我们提到了为什么要做自动化的数据分析,我相信读者更多的是好奇怎么去做,笔者所在的团队为流量分析团队,所以利用流量实现自动化的数据分析的是本文的一大重点。
接下来我们仍然用刚才的例子来说明,首先,需要思考的第一个问题是:“为什么直接信息没有办法形成有效告警?”,简单来说就是我们不知道它是否执行成功了,所以我们在这里将视角后移,倘若有间接信息来佐证执行成功了,那么这其实也就形成了完整的证据链。
这就好比你前女友七夕被求婚了,你可能想知道是否成功,虽然不在现场但是你可以根据他们近期有没有婚礼、有没有领结婚证这些事件来判定是否求婚成功。
在这里,笔者单梳理在刚才案例中能够作为佐证的事件如下:
服务器执行了下载文件命令
服务器正在或者下载了该文件
服务器正在执行或执行过该文件
该文件执行中存在对外通信
综上,如果在该攻击行为的基础上可以确认有上述行为的任意一种,那么是不是就可以确认攻击成功了呢。
此外,这么做的好处很明显,使用数据分析而不是简单的使用传统规则不但可以减少规则的维护,提升通用性,同时在告警运营上也更加准确。
怎么做?
具体应用过程,有点像把大象放进冰箱里:
第一步需要将完整的命令字符串提取出来,并且能够实现对命令字符串的简单分析;
第二步是需要对文件(若有)进行沙盒分析,同时能够根据当前攻击类型提取相关规则,并对对应安全设备下发提取的规则;
第三步则是利用NTA和EDR、扫描器各个安全设备的数据进行关联,实现告警运营;
第一步
第一步将完整命令字符串提取出来,其实有很多方式:
1) 第一种比较传统的方式,其思路也比较简单,是对完整的HTTP请求进行解析,将请求中的参数和参数值拆分为字典形式(无论是get、post内容或者是cookie内容),之后再通过对应正则对参数值的常见命令进行提取,该方式比较简单,但是相对漏报和误报的问题则比较突出;
2) 而第二种方式则是同时落地很多同类请求,在包含恶意请求的同时,也包含该接口的正常请求,通过利用正常请求和攻击请求的差集实现对命令字符串的提取。这种方式的误报相对少,但是成本却也相对较高。

通过上述步骤在提取出来的命令字符串后,接下来的处理其实就相对比较简单了,这里也包含两种方式,一是使用python自带的语法解析库shelx,直接使用split方法对命令进行词法分析,当然也可以直接使用正则来进行模式匹配,然后提取URL、命令等。

第二步
第二步则可以根据字符串的命令去远程下载该文件,同时利用沙盒对可执行文件进行分析,提取文件对应的IOC,同时也可以下发相应的检测规则到各个安全设备。
第三步
第三步就相对比较简单了,主要是拿到有关进程、网络等相关数据,同时针对部分请求需要二次确认的也可以提交给扫描器,最后通过相近时间、命令相似度等方法确认是否关联成功,当然这里也可以使用图相关运算实现关联,此处具体则不再赘述。
用起来!
其实到这里通过这个小案例,大家就基本可以了解有关数据分析的思路了,当然面临不同的场景,其数据分析的关联和产出也自然不同,总而言之,其思路则是通过对攻击行为的所有过程进行分析推理。
最后,笔者在上面讲到的基础上,举一个数据分析实际应用的小案例。
案例一
通过数据分析获得用于盲打验证的dnslog域名、ip等信息,用于反哺安全策略。比如常见的盲打利用一般常见为以下几种模式:
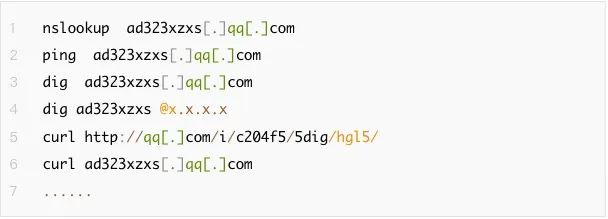
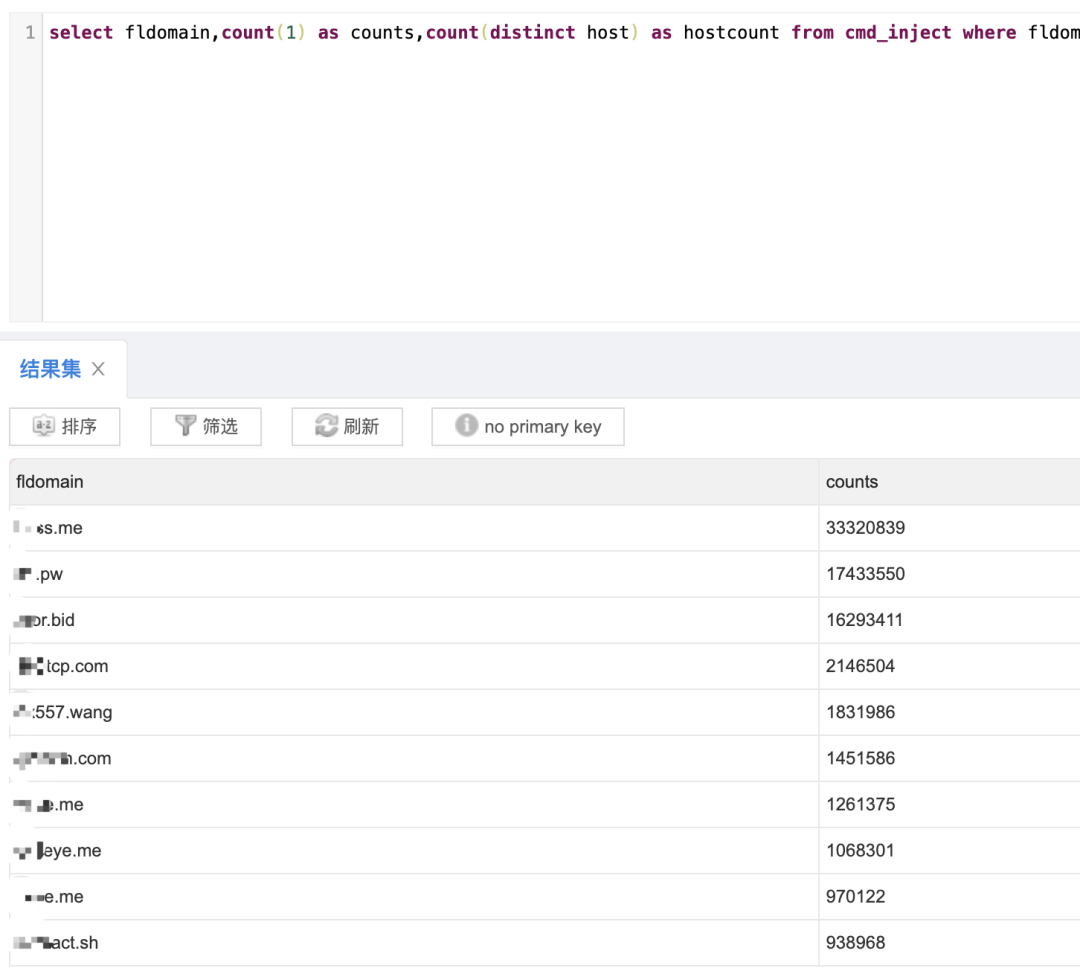
我们首先通过第一步得到所有域名存入到数据库之中,之后再根据不同模式进行处理即可得到攻击者用于验证的根域名,比如针对nslookup ?ad323xzxs[.]qq[.]com这种模式,则可以对所有域名进行拆解得到所有域名的根域名,之后进行group by的处理,最后简单通过数量判断即可得到,而最后获得的这些域名也可以反哺到策略之中。如下图:
案例二
通过数据分析获得存在疑似漏洞的请求提交给扫描器扫描或者发现新型漏洞的传播。之前上文中提到通过正常请求和带paylaod的请求可以获得攻击payload,与此同时,经过该步骤其实也可以获得正常的请求和注入点的位置。
而我们可以根据paylaod的等级来给漏洞存在的可能性进行打分,比如存在拖库行为则可以打高分,最后针对高分的请求直接提交到扫描器进行二次扫描。当然发现新型漏洞传播也是相同的原理,只是具体的处理方式略有不同。
结个尾!
读者看到这里,本文完,欢迎通过留言或者评论进行交流
宙斯盾流量安全分析团队
宙斯盾流量安全分析团队隶属于腾讯安全平台部,依托腾讯安全平台部十五年安全经验打造公司级安全系统,聚焦基于流量的攻击检测、入侵检测、流量阻断以及威胁情报的建设和落地工作,不断挖掘流量中的安全风险并拓宽应用场景,结合大数据、AI 等前沿技术,构建网络流量纵深防御体系。
# 推荐阅读

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
![SNH48-孙珍妮新年新气象,库存发发掉 [2022]](https://imgs.knowsafe.com:8087/img/aideep/2022/1/5/cfa5bd8c9998ab835bc2939c643b418d.jpg?w=250)





 腾讯安全应急响应中心
腾讯安全应急响应中心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675