
图神经网络,如何变深?

来源:智源社区
版式制作:Camel
撰文:侯振宇
编辑:贾 ? 伟
现实世界中很多很多任务可以描述为图(Graph)问题,比如社交网络,蛋白质结构,交通路网数据,图是一个很值得研究的领域。
近年来,随着深度学习的发展,研究人员借鉴了CNN等神经网络的思想,定义和设计了用于处理图数据的神经网络结构——图神经网络(Graph Neural Networks,GNN)。
不同于CNN可以通过堆叠非常多层数的神经网络来取得更好的模型表现,自从「图神经网络」的概念被提出后,大部分图神经网络仅仅堆叠两层就能够在下游任务上取得较好的效果。
那么自然提出一个问题:深层的图神经网络必要吗?
当网络层数加深时,按照常见的解释,会发生过平滑(over-smoothing)或者过压缩(over-squashing)现象,导致不同节点之间的区分度和节点自身的特征表达下降,从而使得深层的图神经网络效果反而不如浅层网络。
但鉴于CV/NLP中的相关经验,浅层网络对数据的拟合能力会弱一些,因此对如何构建深层图神经网络的探索从未停止,例如深层图神经网络GCNII在Cora/PPI等数据集,RevGEN在ogbn-proteins数据集上都取得了state-of-art的结果,我们仍然希望看到深层图神经网络未来的潜力。
深层的图神经网络一方面增加了每个节点的感受野,使得节点可以感知到更大邻域的拓扑和节点特征信息;另一方面,深层网络增大了模型的复杂度和模型容量,使得网络的拟合能力更强。
01
如何设计深层GNN?
那么如何设计一个深层的GNN呢?
图神经网络变深,需要面临的最主要的问题在于:如何克服over-smoothing和over-squashing问题,以及如何训练好一个深层的图神经网络模型。
当结合所有层的输出,图神经网络层数过深、传播次数过多会带来大部分节点的过平滑,而我们又希望通过捕获高阶邻居的信息来帮助获得更好的节点表示,JKNet(Jumping Knowledge Networks)[2]给出的解决方法是:考虑每一层网络的输出结果,将每一层的节点输出进行融合,使得网络能够自适应地学习整合不同层的信息,得到最终的节点表示:
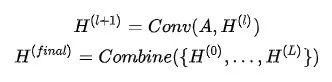

4层JKNet
另外GRAND[10]是将所有传播的结果叠加在一起:?
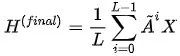
不过,JKNet这类模型并不属于深层GNN,一方面并没有克服GNN加深时存在的各种问题,另一方面也无法堆叠到非常深,模型“自适应学习融合不同层”的信息很难实现。所以JKNet实际上仍然属于浅层GNN,只不过在引入了聚合更高阶邻居的信息的方式。
我们针对这些问题,在最新发表的论文《CogDL: An Extensive Toolkit for Deep Learning on Graphs》中,提出三种策略,包括:初始残差连接、归一化+跳跃连接以及可逆网络(克服内存瓶颈)。
论文题目:CogDL: An Extensive Toolkit for Deep Learning on Graphs
论文链接:https://www.aminer.cn/pub/603e2f2191e01129ef28fecc
1、初始残差连接
APPNP 提出利用PageRank来的模拟传播过程(实际上是一个固定的图滤波器)来取代逐层堆叠的GCN。由于PageRank的局部性,APPNP能够利用图的局部性,在节点分类任务上取得了不错的表现。记归一化后的邻接矩阵?,APPNP的计算可以表示为:

在将信息传播和特征转换解耦的同时,在每次传播的过程中,APPNP都将初始节点特征以一定的权重 α?增叠到每次传播的结果上,从而使得在聚合邻域节点信息的同时,保持节点本身的特征,避免过平滑现象。但由于APPNP在每一次传播时只有线性变换而且并无可学习的权重,所以仍然只能算是一个浅层模型。关于APPNP的实现可以参见:
https://github.com/THUDM/cogdl/blob/master/cogdl/models/nn/ppnp.py
为了构建真正的深层图神经网络,GCNII 在此APPNP基础上,提出了两个技巧:初始残差连接(Initial residual connection)和恒等映射(Identity Mapping)。
Initial Residual Connection(初始残差连接)?与APPNP中相同,GCNII 每次将初始特征$H^{(0)}$ 以一定的权重增加到每层的传播结果上,来使得传播的每一层都能保持至少一定比例的节点的初始特征:(1-αι)?H(ι)+αιH(0)在代码实现中,αι,?ι=0,1,...,L取相同且固定的值。
Identity Mapping(恒等映射)?在ResNet中,残差的存在使得网络在深度增加时,至少可以保持“模型表现不下降”,只要在网络深度不断加深时学习到一个恒等映射即可。在GCNII作者的论述中,GCNII借用相似的思路,设计了特征变换的恒等映射:
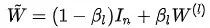
在实际实现中,\beta_l为固定值(0, 0.5),随着层数l的增大而减小。在关于过平滑的分析中,由于一般W(ι)的最大特征值:
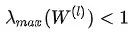
因此W(ι)的存在会加剧过平滑的出现,Identity Mapping则增大了“特征变换”矩阵的特征值:
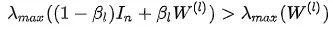
因此有助于缓解过平滑现象。
因此,GCNII 的形式为:
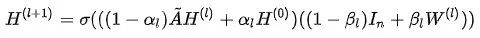
其中σ(·)为非线性变换。
一般地,由于αι≠0,βι≠0,所以每一层GCNII实际上并不能学习到恒等映射,在每一层仍然会不断聚合更高阶邻居的信息。
而消融实验也说明,Initial Residual Connection 在拓展网络深度、避免过平滑现象中发挥了主要作用,而Identity Mapping在有助于缓解过平滑现象的同时,能够进一步增强模型的效果。
GCNII的实现可以参见:
https://github.com/THUDM/cogdl/blob/master/cogdl/models/nn/gcnii.py
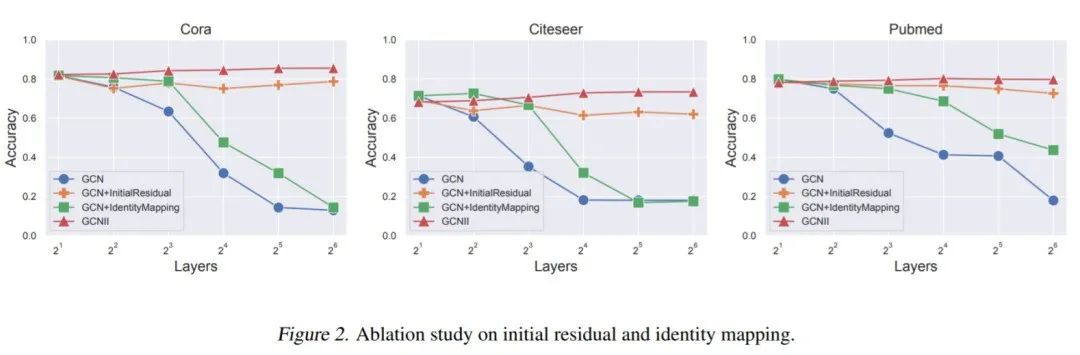
GCNII消融实验
2、归一化 + 跳跃连接
CNN利用BatchNorm和跳跃连接(Skip-connection),能够将网络深度做到上前层。BatchNorm有效改善了深层网络训练中出现的梯度弥散现象,skip-connection则使得CNN能够在增加网络深度的同时能够取得不弱于浅层网络的表现。

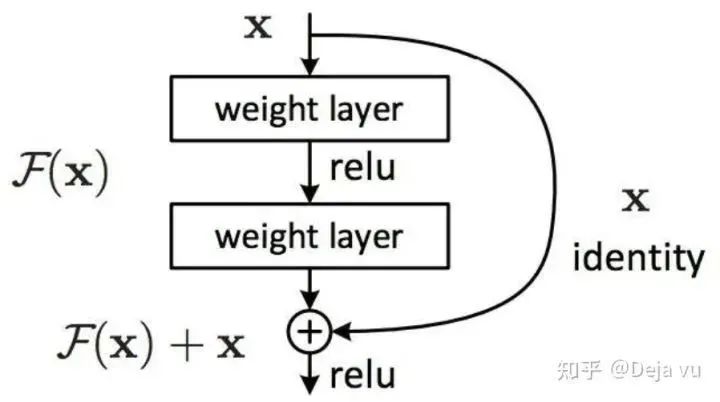
跳跃连接/残差
同样地,归一化和跳跃连接在设计深层图神经网络时也能够有效发挥作用。DeeperGCN将归一化和跳跃连接整合到了图神经网络中,设计了DeeperGCN,同时设计了“提前激活(pre-activation)"形式的残差图神经网络,在实验中,当层数增加到100+层时,DeeperGCN仍然能够在ogbn-proteins数据集上取得非常优异的表现。
ResGCN:?

ResGCN+:?
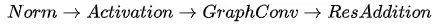
不过,在DeeperGCN论文中,作者并没有测试当网络层数加深时,模型在Cora/Citeseer/PubMed这些常用半监督节点分类数据集上的效果。因为具有“稀疏性高,图规模、直径较小”等特点,关于过平滑现象常见的讨论主要关注在这三个数据集上。我们利用CogDL中复现的DeeperGCN代码发现,深层的DeeperGCN虽然未发生过平滑,但在三个半监督的数据集上的表现略微逊色一些。
在DeeperGCN中,归一化和跳跃连接是一起使用的,除了减缓过平滑现象外,归一化和残差操作都能够提升训练的稳定性和收敛性,使得深层图神经网络的训练更加容易,损失曲线更加平滑。特别地,归一化能够提高深度网络运算过程中的数值稳定性,避免运算过程中出现数值爆炸,而残差连接能够提高深层图神经网络的模型训练表现。
有趣的是,GCNII在实现上除了利用Initial Residual Connection之外,有时也会使用Residual Connection来提升模型的表现,这表明了Residual Connection在加深图神经网络时是一个非常重要的技巧。
CogDL中实现了以上提到的GCNII和DeeperGCN,包括更多的参数模块,可以进行更多地消融实验来探索每一部分的影响和作用。
3、克服内存瓶颈
当网络层数增加时,一方面模型的计算速度会降低,因为需要进行更多次的传播和运算;另一方面,网络层数的增加也会带来内存占用的线性增加,在GPU显存有限的情况下,硬件资源往往也是网络层数增加的一个重要限制。网络层数增加带来的内存占用增加主要包括2个部分:
模型参数的增加,这一部分往往非常小O(d?),所以往往可以忽略; 需要保存每一层前向计算的结果O(Nd)??,用于反向传播时梯度的计算,这一部分占用内存较高。
为了缓解模型层数增加带来的内存线性增长,[7]提出了可逆网络(RevNets),即当前层的激活计算结果可以由下一层的计算结果计算得出。也就是说,如果我们知道网络最后一层的结果,就可以反推出中间每一层的结果。因此,在神经网络进行前向传播的过程中,不再需要保存中间计算结果,从而极大地节省GPU显存的占用。
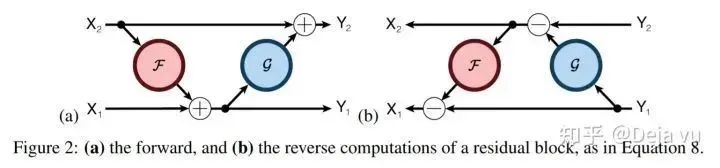
为了实现可逆网络,我们将输入X切分成2部分(X?,X?),因此会得到两个输出(Y?,Y?)。在计算中,我们有:

F 和 G 表示网络前向传播的计算过程,在实现中往往取 F = G。
在后向传播时,我们可以利用计算结果反推出输入,即每一层的输出可以由下一层的输出计算得到:

因此,网络在实际计算时,在反向传播时只需要根据下一层的结果计算上一层的结果即可,不再在需要保存中间的激活结果。这虽然带来了一定的额外的计算的开销(约额外一倍的前向传播计算开销),但极大地节省了显存的占用,使得模型计算的显存占用与层数无关。
所以,如果不考虑模型参数占用的显存,理论上可逆网络可以拓展到任意深度。[6] 将可逆网络应用到了图神经网络上,从而构建了上百层甚至上千层的图神经网络,并利用448层的GNN在ogbn-proteins数据集上取得了state-of-art的效果。这表明深层图神经网络在仍然具有潜力。
02
模型实现
在CogDL?中,我们实现了我们实现了上述提到的所有图神经网络模型,并放在Models下,可以尝试模型在不同数据集上的效果和进行不同参数的调节实验,模型的调用可以直接利用命令行或者?cogdl.experiment?接口实现,同时单独的GNN层放在Layers下,方便进行使用和构建新模型。
python scripts/train.py --dataset cora --model gcnii --task node_classification
或者直接在代码中使用
from cogdl.experiment import experiment
experiment(task="node_classification", model="gcnii", dataset="cora")
同时,我们将DeeperGCN的残差连接形式和RevNet的可逆实现封装成统一的接口,从而可以将任意图神经网络进行封装成深层的图神经网络,具体代码可以参见:
from cogdl.layers import RevGNNLayer, ResGNNLayer
from cogdl.layers import GCNLayer
from cogdl.datasets import build_dataset_from_namedata = build_dataset_from_name("cora").data
data = build_dataset_from_name("cora").data
# 通过CogDL中的图神经网络层GCNLayer/ResGNNLayer/RevGNNLayer构建一个深层GNN
class RevGCN(BaseModel):
def __init__(self, in_feats, out_feats, nhidden, nlayer):
self.input_fc = nn.Linear(in_feats, nhidden)
self.output_fc = nn.Lineare(nhidden, out_feats)
self.layers = nn.ModuleList()
for i in range(nlayer):
gcn_layer = GCNLayer(data.num_features, data.num_classes)
# 得到Pre-activation的残差连接GCN层
resgcn_layer = ResGCNLayer(gcn_layer)
# 得到Reversible的GCN层
revgcn_layer = RevGNNLayer(resgcn_layer)
self.layers.append(revgcn_layer) def forward(self, graph):
def forward(self, graph):
x = graph.x
h = self.input_fc(x)
for layer in self.layers:
h = layer(graph, h)
return self.output_fc(h)
deepgnn = RevGNN(data.num_features, data.num_classes, 64, nlayer=100)
我们目前在CogDL中实现了Deeerpgcn,可逆网络包括?revgcn、revgat、revgen等,当然用户也可以根据个人需求利用CogDL提供的接口便捷地实现自定义的模型。
03
深层GNN表现如何?
GCNII在Cora/PPI上,以及RevGEN在ogbn-proteins等数据集上都取得非常优秀甚至state-of-art的效果。
我们在Flickr、Reddit等常用数据集上进行了测试,结果如下表所示,可以看到,通过增加层数,模型可以取得更优的表现。这些说明深层图神经网络还有待进行更深入的研究,以及开发深层图神经网络的潜力。

关于更多深层图神经网络和其他GNN模型,包括在异构图[9]、图对抗[12]、推荐[13]等方面的模型和应用,可以参照 CogDL中的实现。
CogDL?项目传送门:
https://github.com/THUDM/cogdl CogDL?0.1.1?release?
详细信息 :
https://github.com/THUDM/cogdl/releases/tag/0.1.1
 ?参考资料(上下滑动可浏览)
?参考资料(上下滑动可浏览)
[1] Cen, Yukuo, et al. "CogDL: An extensive toolkit for deep learning on graphs."?arXiv preprint arXiv:2103.00959?(2021).
[2] Xu, Keyulu, et al. "Representation learning on graphs with jumping knowledge networks." ICML'18.
[3] Klicpera, Johannes, Aleksandar Bojchevski, and Stephan Günnemann. "Predict?then propagate: Graph neural networks meet personalized pagerank."ICLR'19.
[4] Chen, Ming, et al. "Simple and deep graph convolutional networks." ICML'20.
[5] Li, Guohao, et al. "Deepergcn: All you need to train deeper gcns."?arXiv preprint arXiv:2006.07739?(2020).
[6] Li, Guohao, et al. "Deepgcns: Can gcns go as deep as cnns?." ICCV'19.
[7] Li, Guohao, et al. "Training Graph Neural Networks with 1000 Layers." ICML'21.
[8] Gomez, Aidan N., et al. "The reversible residual network: Backpropagation without storing activations." NeuIPS'17.
[9] Lv, Qingsong, et al. "Are we really making much progress? Revisiting, benchmarking, and refining heterogeneous graph neural networks." KDD'21.
[10] Feng, Wenzheng, et al. "Graph Random Neural Network for Semi-Supervised Learning on Graphs." NeuIPS'20.
[11] Qiu, Jiezhong, et al. "LightNE: A Lightweight Graph Processing System for Network Embedding." SIGMOD'21.
[12] Zou, Xu, et al. "TDGIA: Effective Injection Attacks on Graph Neural Networks." KDD'21.
[13] Huang, Tinglin, et al. "MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems." KDD'21.
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
??如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675