
「狗」生万物?以色列团队提出零样本训练模型,狗狗秒变尼古拉斯·凯奇

??新智元报道??
??新智元报道??
来源:arXiv
编辑:Priscilla 好困
【新智元导读】特拉维夫大学和英伟达研究团队利用CLIP模型的语义能力,提出了一种文本驱动的方法:StyleGAN-NADA,无需在新的领域收集图像,只要有文本提示就能极速生成特定领域图像。




方法实现
?
方法实现
网络结构概述

基于CLIP的指导
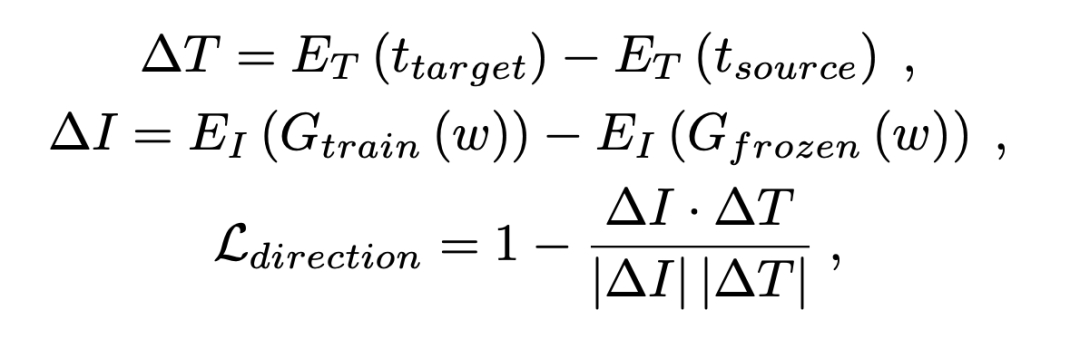

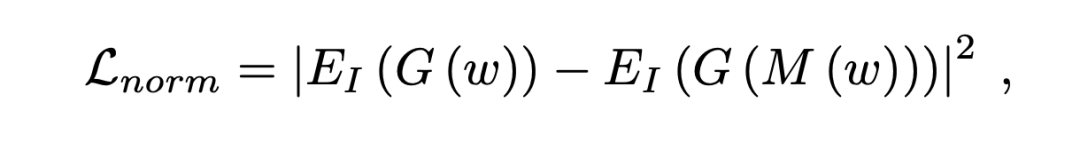
实验结果
实验结果




参考资料:
https://arxiv.org/abs/2108.00946

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675