诞生于第二次世界大战、恐怖纳粹统治时期的1947年纽伦堡法案和随后的1964年赫尔辛基宣言,帮助人们建立起了知情同意原则(Informed Consent),该原则建立在人类尊严和控制关于自己信息传播的基础上。
在接下来的数十年间,知情同意原则指导了医学、心理学等学科收集实验对象数据的方式。尽管这一原则尚不完善,但是它仍然在一定程度上保护了大数据时代的个人隐私保护。然而,在这个大数据时代,知情同意、隐私或个人代理的基础已经逐渐被侵蚀。政府机构、学术界和工业界都在未经同意的情况下,以匿名的名义积累了数以百万计的人类图像,通常是出于未声明的目的。这些说法具有误导性,因为总体而言,汇总数据的匿名性和隐私性较弱,更重要的是,人脸图像不是可以汇总的数据类型。从表1可以看出,在同行评议的文献中发现了数千万人的图像,这些图像是在未经个人同意或知情的情况下获得的,也没有得到IRB(强制性机构审查委员会)的批准。表1. 包含人类图像的大规模数据集
在此背景下,UnifyID AI Labs的Vinay Uday Prabhu, The Irish Software Research Centre的Abeba Birhane,将目光关注最著名和最规范的大规模图像数据集之一:ImageNet数据集。从有问题的图像来源方式到图像中的人类标签,再到使用这些图像训练人工智能模型的下游效应,ImageNet和大规模视觉数据集(下文简称“LSVD”),构成了计算机视觉的代价巨大的胜利。在他们的论文LARGE DATASETS: A PYRRHIC WIN FOR COMPUTER VISION?中,两人指出,这场胜利是以损害少数群体为代价的(数据实战派后台回复“ImageNet”获取论文下载链接)。这个高质量但低隐私的计算机视觉行业新起点,变相助长了在这之后数年技术对个人和集体隐私、同意权的侵蚀。ImageNet数据集的出现被广泛认为是深度学习革命的关键时刻,这场革命彻底改变了计算机视觉(CV)和人工智能(AI)。在ImageNet之前,计算机视觉和图像处理研究人员在小数据集上训练图像分类模型,如CalTech101 (9k图像)、PASCAL-VOC (30k图像)、LabelMe (37k图像)和SUN (131k图像)数据集。ImageNet拥有超过1400万张图像,分布在21,841个synsets中,包含1,034,908个边界框注释,弥补了以前规模方面的缺失,主导了曾经的计算机视觉奥运会,拥有6000万个参数的卷积神经网络(CNN)在这个数据集中大放异彩。ImageNet创建于十多年前,迄今仍是最具影响力和最强大的图像数据库之一。在它创建的多年后进行事后审判,似乎是多余的,但ImageNet确实对其他大规模数据集的持续性和计算机视觉领域的文化培养起到了关键作用。从ImageNet出发,这篇论文总结了缺乏谨慎伦理考虑、对负面社会后果预期的数据集管理实践的潜在危害和威胁。如果在构建大型图像数据集时没有仔细考虑社会影响,将对个人的福利和福祉构成威胁。最常见的情况是,弱势群体和边缘化人群付出了不成比例的高昂代价。在过去的一年里,允许人脸搜索等功能的反向图像搜索引擎的效率显著提高,只要付一小笔费用,任何人都可以使用他们的门户或API来运行一个自动化的过程,以揭示ImageNet数据集中一幅面孔对应的“真实世界”身份。例如,在性工作受到社会谴责或在法律上被定为犯罪的社会中,通过图像搜索重新识别性工作者,对个体受害者来说是一种真正的危险。如紧身衣,胸罩,比基尼等包含了海滩偷窥和其他非自愿采集的图像,通过图片搜索,可以轻易把这些图像和本人联系到一起,而这些受害者通常为女性。
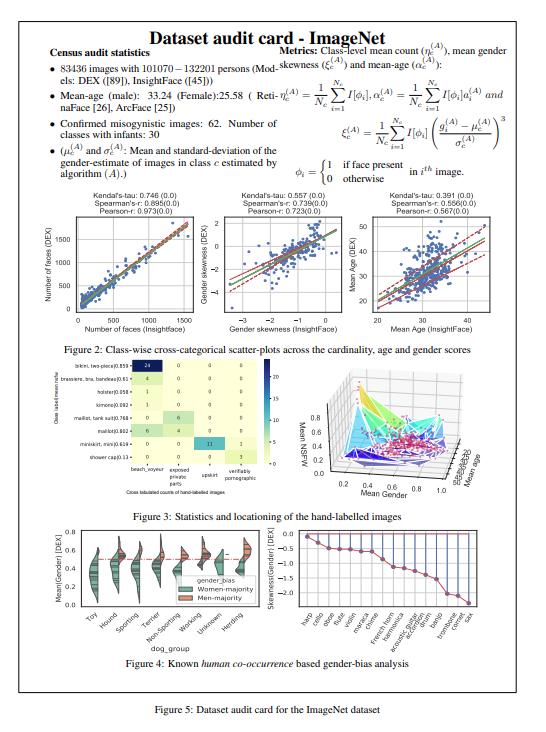
构建计算机视觉的尝试是渐进的,其起点可以追溯到1966年Papert的夏季视觉项目。然而,ImageNet凭借其海量数据,不仅在人工智能历史上树立了一个权威的里程碑,还为更大、更强大、令人怀疑不透明的数据集制作铺平了道路。计算机视觉社区对ImageNet数据集缺乏审查,这只会鼓励学术和商业机构在不经过审查的情况下建立更大的数据集。例如,近年来许多高被引论文都使用了一个名为JFT-300M的大规模视觉数据集。这个数据集可以说是“在黑暗中运行”。甚至没有官方说明JFT-300M到底代表什么意思。行业所知的是它拥有超过3亿张图片,这些图片分布于一万八千个类别之中。开源的open Images V4-5-6包含一个三百多万图像的子集,涵盖2万个类别(还拥有一个扩展数据集,包含五十万众包图像,涵盖6000多个类别)。但被发现包含有11张未经双方同意的儿童图片,而这些图片是从flickr上下载的。对这种不透明的、有偏见的(半)合成数据集的任何下游算法进行基准测试,只会导致有争议的情况。因此,有必要再次强调,这些数据集的存在和使用对人们产生直接和间接的影响,因为社会结果的决策越来越依赖于通过这些数据进行训练的系统。然而,尽管有这样深刻的影响,这些数据究竟来自哪里?图像被使用是否获得了共识?这样的关键问题却很少被认为是LSVD管理过程的一部分。ImageNet在更广泛的人工智能社区中培养的文化更微妙,也许是间接的影响,在这种文化中,将真人的图像作为自由获取的原材料,已经被视为一种常态。这种常态不仅对我们常说的弱势群体,而且对我们所知的隐私的真正含义也构成了威胁。知识共享许可协议只涉及版权问题,而不涉及隐私权或同意将图像用于训练。然而,ImageNet之外的许多努力,包括开放图像数据集,都是建立在这种基础上的,大规模数据集管理机构将“对所有人免费开放”视为绿色通行证。两位作者认为,这本质上是错误的,正如知识共享组织提出的观点所证明的那样:“CC许可的设计是为了解决一个特定的约束,它们做得很好:解除限制性的版权。但版权不是保护个人隐私、解决人工智能发展中的研究伦理问题或规范在线监控工具使用的好工具。”科技研究和社会科学领域数十年的工作表明,对大多数更广泛的社会和伦理挑战,几乎不存在单一直接的解决方案。这些挑战深深植根于社会和文化结构,并构成基本社会结构的一部分。当人工智能系统被灌输了世界的美、丑、残忍的信息,但期待它只反映美是一种幻想。鉴于我们所面临的挑战的广度,任何快速解决问题的尝试,都有可能掩盖问题,并可能提供一种错误的解决方案。例如,所谓的完全消除偏见的想法,在现实中,可能只是把那些偏见深深隐藏起来。此外,许多挑战(偏见、歧视、不公正)随着环境、历史和地点的变化而变化,它们是不断变化的概念,这些变化相当于一个移动的目标。在ImageNet数据集中,2832个人物类别中有1593个有潜在的攻击性标签,并计划从ImageNet中删除所有这些标签。两位作者强烈主张对Tiny Images数据集中的攻击性名词类以及ImageNet-ILSVRC-2012数据集中属于可验证色情、非自愿场景拍摄、海滩窥淫癖和暴露生殖器类别的图像采取类似的行为。在图像类别被保留但图像不被保留的情况下,可以选择用经双方同意拍摄的经济补偿的图像来替换。这些照片中的一些人可能会站出来表示同意,并贡献他们的照片,以换取公平的经济补偿、信用,或纯粹出于利他主义。然而,这种解决方案带来了进一步的问题?我们最终会不会得到一个主要由经济上处于不利地位的参与者的图像池?论文作者发现,一些反向图片搜索引擎,确实允许用户通过他们的“报告滥用”门户网站从索引中删除特定的图片。这有助于减轻某些方面的直接伤害。这个方法需要使用DP-Blur等技术,以量化的隐私保证来模糊图像中人类的身份。其基本思想是在模型训练期间使用(或增加)合成图像来代替真实图像。方法包括使用手绘草图图像,使用GAN生成的图像和数据集蒸馏技术,其中数据集或数据集的子集被蒸馏为几个有代表性的合成样本。这是一个新兴的领域,在跨视觉领域的无监督域适应等领域已经出现了一些有前景的结果。对ImageNet进行纵向分析时,作者发现,如果在数据集筛选阶段向众包人员提供明确的指令,从源头上对这些图像进行过滤,可以避免具体的道德违规。作者希望,在未来,伦理检查能成为未来数据集管理工作中不可分割的一部分。背景对于确定一个特定的数据集是否符合伦理或有问题至关重要,因为它提供了重要的背景信息,而数据表是提供背景的有效方法。因此,作者提出了数据集审计卡的方法。这允许大规模图像数据集管理人员在公开数据集的同时,也发布目标、管理过程、已知缺点和注意事项。如下图所示的,使用所执行的定量分析为ImageNet数据集规划了一个示例数据集审计卡。文章中,作者对ImageNet进行了跨类别定量分析,以评估道德违规的程度和基于模型注释的方法的可行性,包括57个不同指标(参见补充部分)的图像级和类级分析、计数、年龄和性别(CAG)、nsfw评分、类标签的语义和使用预先训练的模型分类的准确性。具体可见论文,在此不多做赘述。总而言之,这项研究督促机器学习社区密切关注其工作直接和间接的社会影响,特别是对弱势群体的影响。在这方面,对当前工作的历史背景、背景和政治维度的认识是必要的,由此推动人工智能数据集管理实践的更新,例如在大规模数据集管理过程中建立机构审查委员会(IRB)等等。关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/




 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




