来源:GitHub
编辑:LRS
【新智元导读】零样本的风格迁移听说过没有?英伟达一个实习生小哥集文本CLIP和图像生成StyleGAN于一身,只需要输入几个单词就可以完成你想要的风格迁移效果!再也不用为了风格迁移找数据啦!
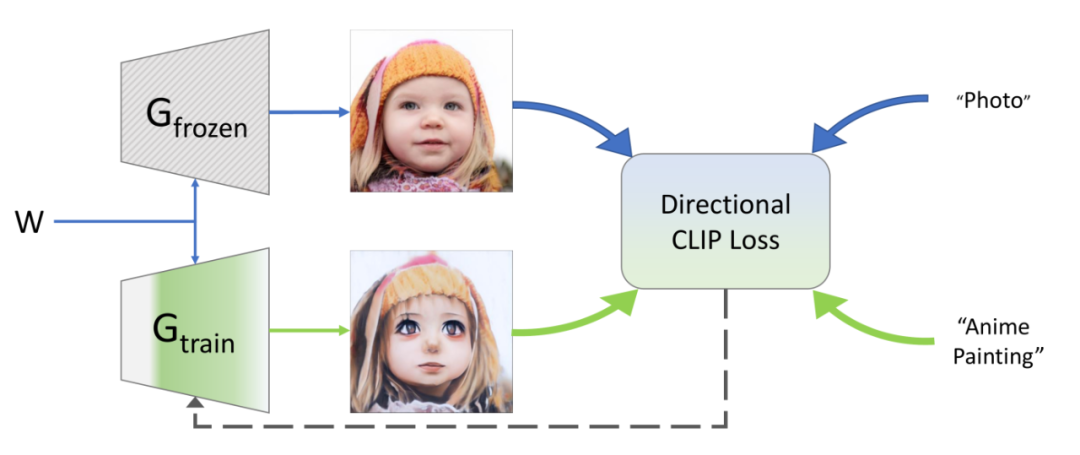
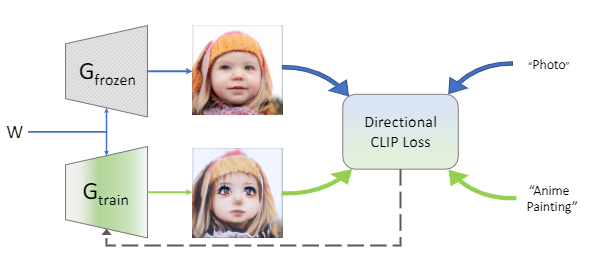
StyleGAN想必大家都不陌生了,它借助生成对抗网络(GAN)对捕获丰富语义的潜在空间和模拟图像分布的能力,可以用来换脸、风格迁移、换肤色等等,一般的输入数据都是源域的图像和目标域的图像。但这些模型的应用范围仅限于可以收集大量图像的域,这一要求严重限制了其适用性。事实上,在许多情况下(例如某个特定艺术家的绘画),可能没有足够的数据来训练一个GAN,甚至面临根本没有任何数据的情况。根据以往的经验,大规模预训练模型已经见到了足够多的域的数据,也就是说直接使用Vision语言模型也许可以不用收集数据,直接根据文本就可以召回相关域的图像。英伟达的实习生 Rinon Gal 最近提出这样一个模型,不需要图像输入就可以做StyleGAN,秘诀就是利用CLIP模型的多模态能力。这种文本驱动的方法域外(out-of-domain)的图像生成,研究人员引入了一个训练方案,该方案只使用文本提示词,就可以将预训练的模型的域转移到一个新的域。域转移(domain shift)的实现是通过修改生成器对与文本对齐的图像的权重来实现的。例如上图中,研究人员修改了针对真实人脸和汽车的图像生成器,就可以生成特定艺术风格的绘画。还可以在教堂里训练生成器以生成纽约市的图像。但这种模型是相当于是「盲目」训练(train blindly)的,在训练过程中看不到目标域的任何图像,也就是说这符合zero-shot的设定。这个模型主要由两个核心组件构成,StyleGAN和CLIP。近年来,StyleGAN及其后继模型已然是无条件图像生成领域的老大哥,能够合成质量非常高图像。StyleGAN生成器由两部分组成,首先,映射网络将从高斯分布采样的隐编码转换为学习的隐空间中的向量。然后把这些隐向量输入到第二个组件合成网络,用来控制网络中不同层的特征。之前的研究也证明了,通过遍历这个中间隐空间W,或者通过在不同的网络层上混合不同的W编码,能够对生成图像中语义属性的细粒度控制。但这种潜在空间传输通常仅限于域内修改,也就是说,它被约束到具有与初始训练集匹配的属性的图像的流形。相比之下,这篇论文的目标是在不同域之间转换生成器,而不只是在隐空间内编辑或是微调语义感知。结合StyleGAN的生成能力和CLIP的语义知识能力的模型最近也有人提出,模型叫StyleCLIP,并且提出三种方法来利用CLIP的语义表达能力:1、隐优化技术(latent optimization technique),使用标准的反向传播方法修改给定的潜编码,使得生成的图像和给定的目标文本之间的CLIP-space内距离最小。研究人员将这个损失函数命名为全局CLIP损失。2、隐映射(latent mapper),训练网络将输入的隐编码转换为修改生成图像中文本描述属性的编码。这个映射器使用相同的全局CLIP损失进行训练,从而最小化到目标文本的CLIP-space距离。对于一些剧烈的形状修改,我们发现训练这样一个潜在的映射器可以帮助提高识别结果-3、通过确定修改哪些维度的隐编码会导致图像空间变化,从而发现GAN隐空间中有意义的变化方向。这三个方法训练和推理时间变化很大,但它们都与其他隐空间编辑方法有一个共同的特点,它们应用于给定图像的修改在很大程度上受限于预训练生成器的图像域。所以,StyleCLIP能够改变发型、表情,甚至可以将狼变成狮子,但他们不能将照片变成其他风格的绘画。为此研究人员主要从两方面基于StyleCLIP又做了改进:(1) 如何才能最好地提取封装在CLIP中的语义信息?首先就是损失函数的修改,除了之前提到的全局CLIP损失,第二个损失函数用来保留多样性和防止图像崩溃。一个图像对包含两个图像,一个由参考生成器生成,另一个由修改的可训练的生成器使用相同的隐编码生成。把参考图像和目标图像的embedding按照CLIP-space中源文本和目标文本的embedding方向对齐。这个损失函数可以克服全局CLIP损失的缺点,如果目标生成器仅创建单个图像,则从所有源到该目标图像的剪辑空间方向将不同,所以它们不能全部与文本方向一致。其次,网络很难收敛到通用的解决方案,因此必须加入干扰来欺骗CLIP。在实验部分,下图可以看到如何从狗生成到各种动物。对于所有动物翻译实验,在每次迭代中将可训练层的数量设置为三层,并训练隐映射器以减少源域数据的泄漏。可以看到变化主要集中在样式或较小的形状调整上。例如,许多动物都会竖起右耳,而大多数AFHQ数据集中的狗品种则不会。除了zero-shot外,研究人员还将方法与两种few-shot方案进行比较,即Ojha提出的模型和MineGAN进行比较。第一种方法侧重于保持源域的多样性,同时适应目标域的风格,而后一种方法则通过引导GAN朝向更好地匹配目标集分布的隐空间域来稳定训练,但会牺牲一定的多样性。下图可以看到虽然论文中提出的模型生成的图片可以看出来有人工生成的痕迹,但它成功地避免了备选方案显示的过度拟合和模式崩溃结果,保持了高度的多样性,并且能够在不提供任何目标域图像的情况下实现了这一点。参考资料:
https://stylegan-nada.github.io/

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/



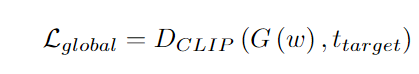










 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




