近年来,世界模型(World Model)在机器人、模拟与强化学习中均取得了出色的研究结果。2018年,Jürgen Schmidhuber 与 David Ha 首次以无监督的方式训练世界模型,使模型能快速学习环境中的压缩时空表征,再将世界模型中的特征作为智能体的输入,训练出了一个非常压缩与简单的策略来解决模拟2D赛车等任务。今年2月,Google AI 也用世界模型,在 Atari 游戏中实现了达到人类水平的表现。但是,相比简单的游戏环境,现实的世界环境要复杂得多。不久前,在发表于 ICCV 2021 的一篇工作(“Pathdreamer: A World Model for Indoor Navigation”)上,Google AI 团队提出了一个世界模型,叫作“Pathdreamer”,可以仅基于有限的种子观察与原先计划的导航路线,生成一幅智能体“肉眼”不可见的建筑物区域的、360? 高清摄像。https://arxiv.org/pdf/2105.08756.pdf
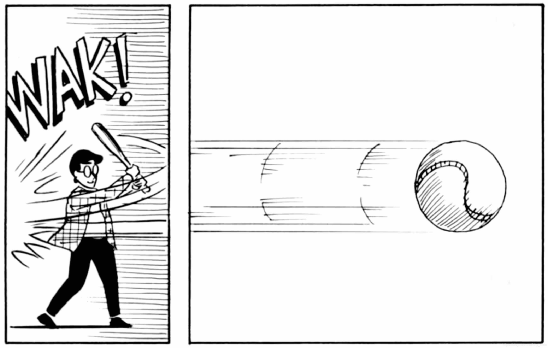
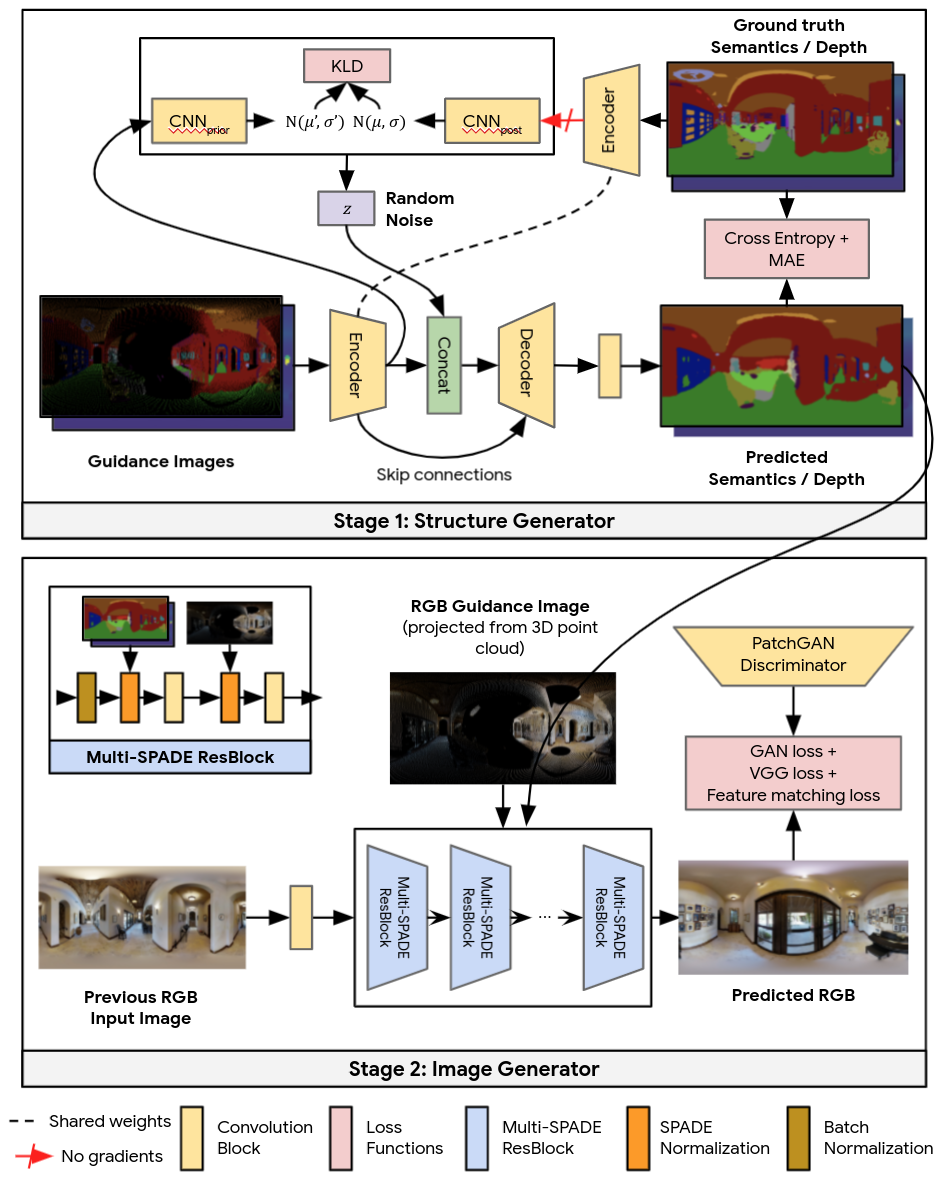
Google AI的团队将Pathdreamer应用于机器人导航任务中,成功率高达50.4%!仅比ground truth设置低了 8.6%(59%)!世界模型(World Model)首次由 Jürgen Schmidhuber 与 David Ha 在 NeurIPS 2018中提出,主要出发点是打造一个通用强化学习环境的生成神经网络模型,为强化学习技术的落地提供完美的模拟环境。这篇工作入选了当年 NeurIPS 的 oral paper。https://arxiv.org/pdf/1803.10122.pdf世界模型的灵感来源于心理学上的“心理世界模型”(mental model of the world)。在人对世界的理解过程中,我们往往是以有限的感官所能感知到的事物为基础,形成一个心理世界模型。我们所做的决定和行动都是基于这个模型。为了处理流经我们日常生活的大量信息,我们的大脑学会了信息的空间域和时域的抽象表示。我们能够观察一个场景并记住其中的抽象描述。图注 / 世界模型示例,源自 Scott McCloud 的《理解漫画》一书证据还表明,我们在任何时刻所感知的,都是由我们的大脑根据我们的内部心理模型对未来的预测所决定的。心理模型不仅仅是预测未来,而且会根据我们当前的运动行为来预测未来的感官数据。我们能够在这种预测模型上采取行动,并在我们面临危险时表现出快速的行为,而不需要有意识地规划一个行动路线。以棒球为例,一个棒球运动员只有毫秒级的时间来决定如何挥动球棍,这个时间甚至比视觉信号从眼球传到大脑的时间还要短。对专业运动员来说,这个动作几乎是下意识的,他们的肌肉在正确的时间和地点挥动球棍,与他们内部模型的预测一致。他们可以根据他们对未来的预测迅速采取行动,而不需要有意识地推出可行的击球计划。在许多强化学习问题中,智能体既需要一个对过去和现在状态的良好描述,还需要一个优秀的模型来预测未来的状态。作为真实世界的一个表征,世界模型采用无监督的方式进行训练,能取得较好的策略。2018年,当 Jürgen Schmidhuber 与 David Ha 提出世界模型后,他们将世界模型用于解决一个赛车竞速的强化学习任务。带有预测能力的世界模型可以有效地提取空域与时域特征,再将这些特征应用于控制模型,然后训练一个最小的控制模型来完成连续域控制任务,即赛车。受到 Jürgen Schmidhuber 等人的工作启发,谷歌团队开始将世界模型的研究思想应用在同样是智能体控制的机器人导航任务中,使用世界模型来获取周围环境的信息,使智能体能够在特定的环境中预测自己的行为后果。在了解Pathdreamer之前,我们不妨设想一下:如果你出去旅游,住进一间完全陌生的民宿,你会如何判断房子的方位?一般来说,当我们推开大门,我们会知道首先映入眼前的是客厅,然后顺着客厅猜测卧室、厨房、阳台等等空间的方位。那么,机器人呢?如果一个机器人来到一个完全陌生的房子里,它会如何导航?人在判断方位时,善于利用视觉与常识,通过眼前的事物推理出空间的布局,从而找到自己的目标。但是,对于机器人来说,在一个新的建筑里,要利用语义线索与事物的规律分布来定位,并不是一件容易的事。此前,针对上述问题,Facebook AI 提出了一个算法,叫“DD-PPO”,主要是:通过无模型强化学习(model-free reinforcement learning),以端到端的方式让智能体学习辨认一个空间内的线索、并利用这些线索来完成导航的任务。但是,这种方式的学习成本高,难以检验,而且泛化难,另一个智能体必须从头开始学习同样的方式、才能掌握依据理解线索来定位的能力。相比之下,Pathdreamer 模型可以从单一视角合成一幅沉浸式场景图,预测当智能体移动到一个新的视点、或是移动到一个完全看不见的区域(比如角落)时,智能体可能会看到什么。这不仅可以用于视频编辑、使照片看起来栩栩如生,最重要的是,它还可以将人类环境的知识告诉机器智能体,帮助机器人在现实世界中定位导航。比如,如果我们给机器人一个任务,让它在一栋陌生的建筑里寻找某个房间或物体,那么它就可以先在世界模型中进行模拟,学习识别物体在空间中可能的位置,减少实际投入后的导航错误。除了模拟导航以外,机器人在Pathdream等世界模型中训练,还可以增加训练数据的数量。Pathdreamer 将原来的一个或多个观察序列作为输入,生成通往目标位置的预测路线。预测的路线是事先提供,或由智能体在返回途中接触到的观察迭代更新。输入与预测均包含 RGB、语义分割与深度图像。在内部,Pathdreamer 使用了 3D 点云来表示环境的表面。云中的点都标了它们的 RGB 颜色值和它们的语义分割类,比如墙壁、椅子或桌子。要在新的建筑物里预测即将映入眼前的事物,首先要将点云重新投射到新建筑的 2D 图像中、以提供“指导”图像,然后,Pathdreamer 会从中生成逼真的高分辨率 RGB、语义分割和深度。随着模型的“移动”,点云会积累新的观察结果(要么是真实的,要么是预测的)。使用点云来记忆的一个优势是时序一致性(temporal consistency)——重新访问的区域会以与先前观察一致的方式呈现。为了将指导图像转换为合理、真实的图像输出,Pathdreamer 分为两个阶段运行:第一阶段,用结构生成器生成分割和深度图像;第二阶段,用图像生成器将分割与深度图像渲染为 RGB 输出。从概念上讲,就是第一阶段提供了关于场景的合理高级语义表示,第二阶段再将其渲染为逼真的彩色图像。这两个阶段都用到了卷积神经网络(CNN):在具有高度不确定性的区域,比如拐角或视线以外的房间,可能会出现许多不同的场景。而Pathdreamer能够生成满足区域高度不确定的多样化结果。有感于受到纽约大学Rob Fergus与Emily Denton提出的随机视频生成思想,Pathdreamer的结构生成器以噪音变量为条件,该变量表示指导图像中没有捕获的下一个导航位置的随机信息。通过对多个噪音变量进行采样,Pathdreamer可以合成多个不同场景,允许智能体在一条给定的导航路线中对多个合理的结果进行采样。这些不同的输出不仅反映在第一阶段的输出(语义分割和深度图像)中,还反映在生成的 RGB 图像中。如下图所示,最左侧的一列指导图像表示智能体先前看到的像素。其中,黑色像素表示智能体原先看不见的区域,对此,Pathdreamer 通过对多个随机噪声向量进行采样,生成了不同的图像输出。在实践中,当智能体在一个环境中定位导航时,它可以通过新的观察结果来生成输出图像。Pathdreamer 基于来自 Matterport3D 的图像和 3D 环境重建进行训练,并且能够合成逼真的图像与连续的视频序列。由于输出图像具有高分辨率和 360? 无死角的特征,现有的导航机器人可以轻松地将图像转换,以适应机器人配有的相机视野。他们将 Pathdreamer 应用于视觉与语言导航 (VLN) 任务,其中,机器人必须遵循自然语言的指令定位到真实 3D 环境中的某一个位置。他们使用 Room-to-Room(R2R)数据集进行了一项实验,让指令机器人在模拟多条可能的行走轨迹前进行规划,并根据导航指令对每一条轨迹进行排名,然后选择排名第一的轨迹进行导航。地面实况(ground truth)设置:机器人通过与真实的环境互动(比如移动)来进行规划;
基线(Baseline)设置:机器人提前规划,无需与导航图交互、对建筑内的导航路线进行编码,但没有提供任何视觉观察;
Pathdreamer 设置:机器人提前规划,无需与导航图交互,且还能接收到Pathdreamer所生成的对应视觉观察。
在Pathdreamer设置中,机器人提前三步(大约6米)规划,导航成功率高达 50.4%,而基线设置的成功率只有 40.6%。这表明,Pathdreamer对现实室内环境中的有用、且可以访问的视觉、空间与语义知识进行了编码。而在地面实况的设置中,机器人通过移动进行规划,导航成功率达到了 59%。不过,地面实况设置要求机器人花费大量的时间与资源进行多轨迹探索,在现实世界中的代价可能十分高昂。图注:VLN机器人在三种设置(地面实况、基线与Pathdreamer)中的表现实验结果表明,类似 Pathdreamer 的世界模型在处理复杂的导航任务中具有出色表现。1、https://ai.googleblog.com/2021/09/pathdreamer-world-model-for-indoor.html
2、https://ai.facebook.com/blog/near-perfect-point-goal-navigation-from-25-billion-frames-of-experience/
3、https://ai.googleblog.com/2021/04/model-based-rl-for-decentralized-multi.html
4、https://ai.googleblog.com/2020/03/introducing-dreamer-scalable.html
5、https://worldmodels.github.io/
6、https://ai.googleblog.com/2021/02/mastering-atari-with-discrete-world.html
7、https://bair.berkeley.edu/blog/2019/12/12/mbpo/
8、https://blog.csdn.net/hhy_csdn/article/details/88207977
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
















 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




