
ST-GCN 实现人体姿态行为分类

作者 | 李秋键
出品 |?AI科技大本营(ID:rgznai100)
引用

1、ST-GCN 介绍

1.1 模型通道

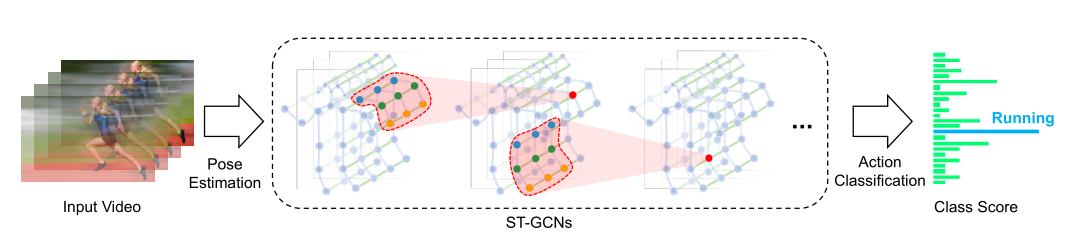
1.2 骨骼图结构
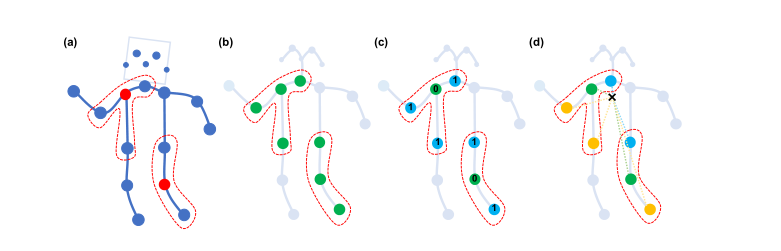
1.3 时空模型
2、模型实验
2.1 环境搭建
1、首先下载好完整无误配置好的代码(包括模型等等,见文末)。
2、搭建最新版的openpose环境,并使用cmake编译。
3、配置好python的cuda环境,以及opencv等基础环境。
4、使用命令
“python main.py demo --openpose E:/cmake/environment/x64/Release --video 2.mp4”进行测试生成结果。
其中“E:/cmake/environment/x64/Release”需要改成自己的openpose环境。
2.2 主函数调用
其中主函数通过使用processors管理的设定好的分类识别、输入输出管理等程序内部函数进行整个程序的布置。
代码如下:
import argparseimport sysimport torchlightfrom torchlight import import_classif __name__ == '__main__':parser = argparse.ArgumentParser(description='Processor collection')processors = dict()processors['recognition'] = import_class('processor.recognition.REC_Processor')processors['demo'] = import_class('processor.demo.Demo')subparsers = parser.add_subparsers(dest='processor')for k, p in processors.items():subparsers.add_parser(k, parents=[p.get_parser()])arg = parser.parse_args()Processor = processors[arg.processor]p = Processor(sys.argv[2:])p.start()
2.3 模型网络
def __init__(self, in_channels, num_class, graph_args,edge_importance_weighting, **kwargs):super().__init__()self.graph = Graph(**graph_args)A = torch.tensor(self.graph.A, dtype=torch.float32, requires_grad=False)self.register_buffer('A', A)spatial_kernel_size = A.size(0)temporal_kernel_size = 9kernel_size = (temporal_kernel_size, spatial_kernel_size)self.data_bn = nn.BatchNorm1d(in_channels * A.size(1))kwargs0 = {k: v for k, v in kwargs.items() if k != 'dropout'}self.st_gcn_networks = nn.ModuleList((st_gcn(in_channels, 64, kernel_size, 1, residual=False, **kwargs0),st_gcn(64, 64, kernel_size, 1, **kwargs),st_gcn(64, 64, kernel_size, 1, **kwargs),st_gcn(64, 64, kernel_size, 1, **kwargs),st_gcn(64, 128, kernel_size, 2, **kwargs),st_gcn(128, 128, kernel_size, 1, **kwargs),st_gcn(128, 128, kernel_size, 1, **kwargs),st_gcn(128, 256, kernel_size, 2, **kwargs),st_gcn(256, 256, kernel_size, 1, **kwargs),st_gcn(256, 256, kernel_size, 1, **kwargs),))

2.4 ST-GCN网络建立
def __init__(self,in_channels,out_channels,kernel_size,stride=1,dropout=0,residual=True):super().__init__()assert len(kernel_size) == 2assert kernel_size[0] % 2 == 1padding = ((kernel_size[0] - 1) // 2, 0)self.gcn = ConvTemporalGraphical(in_channels, out_channels,kernel_size[1])self.tcn = nn.Sequential(nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True),nn.Conv2d(out_channels,out_channels,(kernel_size[0], 1),(stride, 1),padding,),nn.BatchNorm2d(out_channels),nn.Dropout(dropout, inplace=True),)if not residual:self.residual = lambda x: 0elif (in_channels == out_channels) and (stride == 1):self.residual = lambda x: x


李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。



分享

点收藏

点点赞

点在看
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675