
文字识别助力政务治理,提升数字服务力
背景
暨2021年“十四五”规划将数字政府提上国家顶层设计后,今年两会期间,数字经济、智慧城市再一次成为各界关注的焦点。今年3月5日,《政府工作报告》提出加强数字政府建设,推动政务数据共享。智慧政务旨在助力政务决策、业务流程优化,提升利企便民的服务体验,是提升政府监管效能和公共服务能力的关键之举,智慧城市中的重中之重。
政务治理主要指智慧城市中与政府公务相关的场景,包括:信息采集、审核与服务等。良好的政务治理水平能够为民生服务提供便捷高效的办理体验、增加民政沟通互动、对政务信息的数字化建设也可以方便查询与检索。
随着中国各行业数字化转型速度的加快,越来越多的民众已经体验到数字化对生活带来的便捷,作为与民众息息相关的政务治理,数字化转型需求越来越迫切,如:
场景一:疫情防控、人口普查、客流抽样调查时,各职能部门需要线下批量采集民众身份证或户口本信息并进行管理。过去手工逐一登记的方式人力投入大、耗时长、效率无法满足紧急事务需求;
场景二:民众线上办理政务服务时,往往需要审核身份信息,而繁琐的手动输入过程也会降低办理速度,影响办理体验;
场景三:政务系统过去以纸质文档传递公告、文件为主,随着文件的不断累积,查找某些重要的文件的过程就变得十分繁琐。电子政务系统虽然在不断升级,但各系统之间尚未完全打通,纸质文件的传递有时仍然不可避免。
飞桨PaddleOCR套件支持的PP-OCRv2和PP-Structure解决方案,助力城市政务治理变「智」理。
飞桨政务「智」理方案
政务治理主要指智慧城市中与政府公务相关的场景,包括:信息采集、审核与服务等,其主要业务场景和对应的飞桨解决方案如下图:

政务治理全景图
政务治理按信息的采集和处理流程可分为:现场数据采集、网上政务办理、政务文件电子化、政务信息审核和政务问答系统五个细分场景。
根据采集的对象不同,又可将上述场景分为:
针对身份证、户口本、驾驶证的证件信息采集场景;
针对文件、公告等字体稠密的文档电子化场景;
针对文字信息分类、生成、审核、问答的自然语言处理场景。
前两个场景中是处理图像为主的计算机视觉任务,后一个场景主要是针对文本信息的自然语言处理任务。本文着重介绍与视觉相关的场景与AI技术。
应用PP-OCRv2实现证件信息自动采集
疫情发生、人口普查、客流抽样调查时,政务人员需要快速采集民众的证件信息。基于深度学习的文字识别技术,可以快速、准确地提取证件中的姓名、身份证号等文字信息,对图像质量敏感度较低,能够大幅减少信息采集成本,并有效解决了传统技术在自然场景下的泛化性不足,不能有效处理场景中的倾斜、模糊、阴影等问题。

PP-OCRv2关键信息提取示意
PaddleOCR飞桨文字识别开发套件开源了面向通用场景的产业级SOTA文字识别解决方案PP-OCRv2,包含检测、方向分类器、识别三个模型,可针对中文、英文、数字、竖排文本等进行识别,大小仅13M。在一些场景下,使用少量真实数据微调,即可达到上线效果。目前已经广泛应用在各类证件识别的垂类场景中。

在线体验地址:https://www.paddlepaddle.org.cn/hub/scene/ocr
应用PP-Structure实现政务文件结构化
由于各种因素限制,政务系统不可避免的存在使用纸质文档传递公告、文件的情况,因而造成查阅和检索不便、且无法实现结构化信息管理。
证件信息采集是是政务治理中面向自然场景的,文字形态特征多样,保证通用的识别能力是AI技术的关键所在,而政务文件电子化则是政务治理中面向文档对象的重要应用场景。针对以文档、表格、票据为主的文档场景,文本信息往往比较密集,除了获得文本信息以外,还希望能够自动划分文档区域、将其中的表格结构化提取等等。
PaddleOCR开源了针对文档结构化的解决方案PP-Structure,支持版面分析与表格识别、关键信息提取、视觉问答任务,满足政务文件电子化的需求。
支持对图片形式的文档进行版面分析,划分文字、标题、表格、图片以及列表5类区域;
支持表格区域结构化提取,最终结果输出Excel文件;
支持视觉文档问答和关键信息提取任务,能够针对性的提取图片中的关键信息。

PP-Structure版面分析示意
PaddleOCR飞桨文字识别开发套件
PP-Structure和PP-OCRv2是PaddleOCR针对不同业务场景设计的解决方案,在产业落地中,PaddleOCR提供了覆盖从数据生成、半自动标注、训推一体和多端多平台部署的全流程方案,能够在短时间内完成模型训练与部署,如下图。在模型库的丰富性上,PaddleOCR提供包含4种文本检测算法、8种文本识别算法、1种端到端算法以及80种多语言模型,方便开发者根据业务需求进行二次开发。
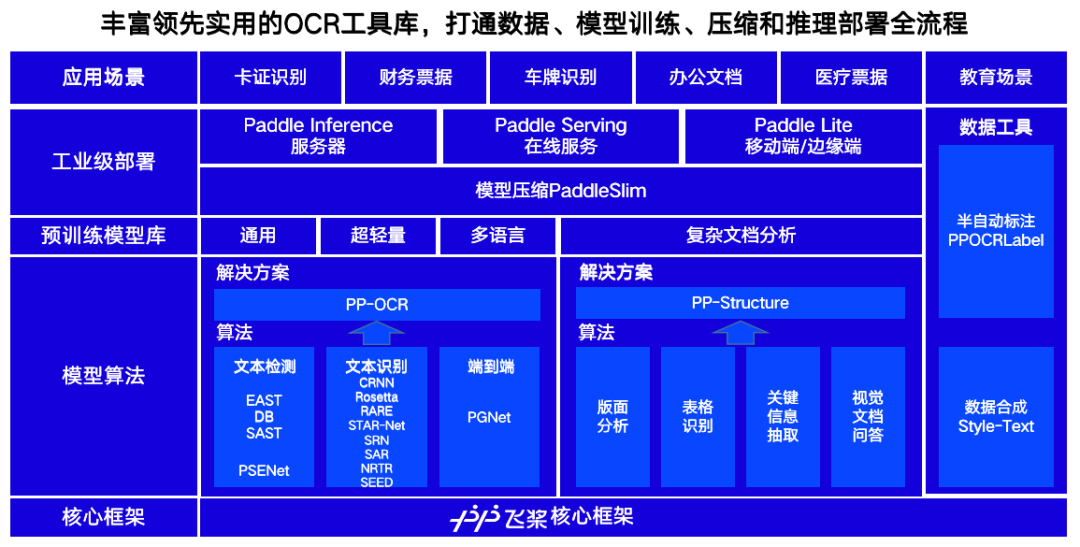
PaddleOCR全景图
产业应用案例:弘连公司智能电子取证分析案例
弘连网络科技公司是一家电子取证公司,在取证工作中往往需要浏览大量图像才能找到对判定案件起关键作用的信息,传统方式通过人工查阅费时费力,而利用AI能力对图像信息分类、文本内容提取可实现对关键信息的快速定位、查阅分析目的。

在方案设计上,弘连公司通过图像分类技术对海量图像归类为人物、文档、证件三个类别,然后利用文字识别能力,提取图片中的文字信息,实现图片文本检索。对人物类图像使用人脸检测、分割、匹配技术实现人物身份快速识别。

在落地的过程中,弘连公司采用阶梯式集成学习、自动化训练等技术,使用PP-OCRv2模型、PP-YOLOv2模型完成文字识别和目标检测任务,在识别效果和解析速度之间达到较好的平衡。
飞桨官网:https://www.paddlepaddle.org.cn
PaddleOCR项目地址:https://github.com/PaddlePaddle/PaddleOCR
课程直播预告
飞桨贴心地为大家准备了一节直播课,从核心技术理论入手,结合企业用户亲自讲解应用案例及心得,全方位剖析智慧政务类业务场景中的技术难点、痛点与解决方案,让大家听得懂、学得会、用得明。在3月25日晚上20:00~21:30在线直播,欢迎感兴趣的行业伙伴们一起参与和交流。
扫码报名直播课,加入技术交流群

更多精彩抢先看

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675