
基于智能数据库的自助式机器学习

译者 | 张怡
审校 | 梁策 孙淑娟
本文采用以数据为中心结构的AI Tables,从而让自助式机器学习(self-serviceML)能更好地为数据工程师、开发人员和业务分析师服务。
如何成为一个IDO?
IDO(insight-driven organization)指洞察力驱动(以信息为导向)的组织。要成为一个IDO,首先需要数据以及操作和分析数据的工具;其次是具有适当经验的数据分析师或数据科学家;最后还需要找到一种技术或者方法,从而在整个公司实施洞察力驱动的决策过程。
机器学习是能最大限度发挥数据优势的技术。ML流程首先使用数据训练预测模型,训练成功之后来解决与数据相关的问题。其中,人工神经网络是最有效的技术,它的设计源自我们目前对人类大脑工作方式的理解。考虑到人们目前拥有的巨大计算资源,它通过大量数据训练可以产生令人难以置信的模型。
企业可以使用各种自助化软件和脚本完成不同的任务,从而避免人为错误的情况。同样,你也完全可以基于数据进行决策来避免当中的人为错误。
为什么企业在采用
人工智能方面进展缓慢?
使用人工智能或机器学习来处理数据的企业仅是少数。美国人口普查局(US Census Bureau)表示,截至2020年,只有不到10%的美国企业采用了机器学习(主要是大公司)。
采用ML的障碍包括:
人工智能在取代人类之前还有大量工作尚未完成。首先是许多企业缺乏且请不起专业人员。数据科学家在这一领域备受推崇,但他们的雇佣成本也是最高的。
缺乏可用数据、数据安全性以及耗时的ML算法实现。
企业很难创造一个环境,从而让数据及其优势得到发挥。这种环境需要相关的工具、过程和策略。
机器学习的推广
只有自动ML(AutoML)工具是不够的
自动ML平台虽然有着很光明的未来,但其覆盖面目前还相当有限,同时关于自动ML能否很快取代数据科学家的说法也有争论。
如果想要在公司成功部署自助化机器学习,AutoML工具确实是至关重要的,但过程、方法和策略也必须重视。AutoML平台只是工具,大多数ML专家认为这是不够的。
分解机器学习过程

任何ML进程都从数据开始。人们普遍认为,数据准备是ML过程中最重要的环节,建模部分只是整个数据管道的一部分,同时通过AutoML工具得到简化。完整的工作流仍需要大量的工作来转换数据并将其提供给模型。数据准备和数据转换可谓工作中最耗时、最令人不愉快的部分。
此外,用于训练ML模型的业务数据也会定期更新。因此,它要求企业构建能够掌握复杂的工具和流程的复杂ETL管道,因此确保ML流程的连续和实时性也是一项具有挑战性的任务。
将ML与应用程序集成
假设现在我们已经构建了ML模型,然后需要将其部署。经典的部署方法将其视为应用层组件,如下图所示:
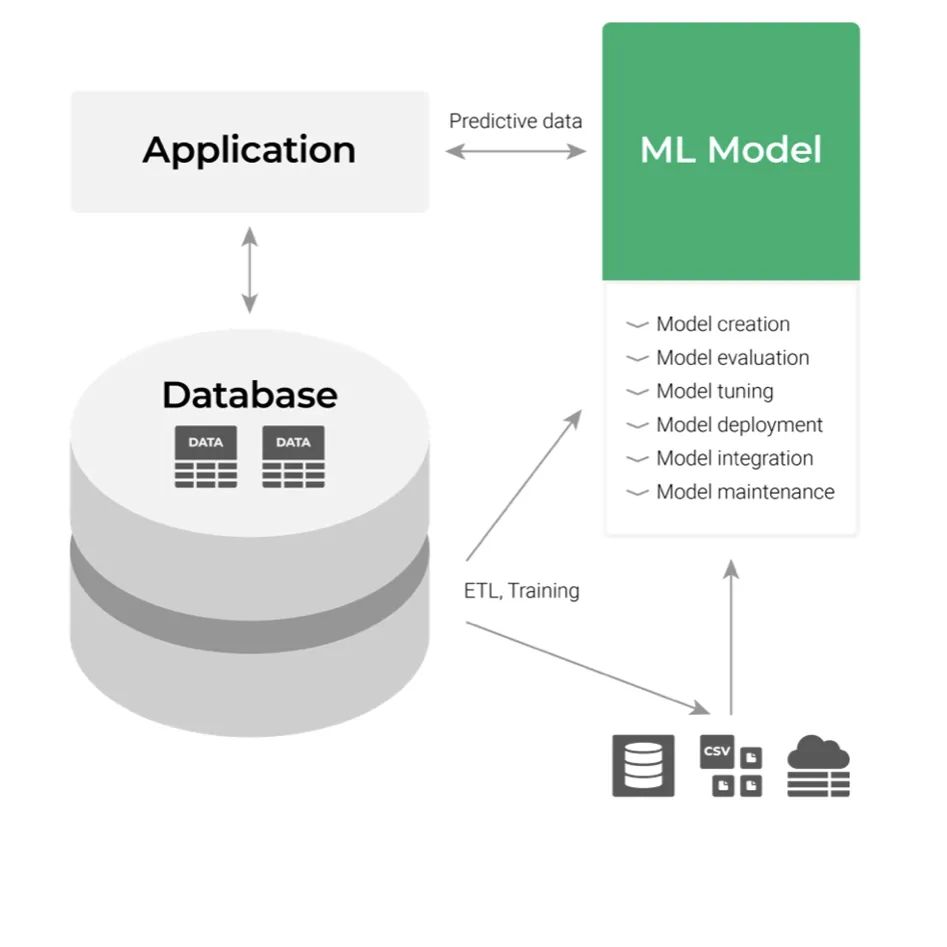
它的输入是数据,输出是我们得到的预测。通过集成这些应用程序的API来使用ML模型的输出。仅从开发者的角度来看,这一切似乎很容易,但在考虑流程时就不是那么回事了。在一个庞大的组织中,与业务应用程序的任何集成和维护都相当麻烦。即使公司精通技术,任何代码更改请求都必须通过多级部门的特定审查和测试流程。这会对灵活性产生负面影响,并增加整个工作流的复杂性。
如果在测试各种概念和想法方面有足够的灵活性,那么基于ML的决策就会容易得多,因此人们会更喜欢具有自助服务功能的产品。
自助机器学习/智能数据库?
正如我们上面看到的,数据是ML进程的核心,现有的ML工具获取数据并返回预测结果,而这些预测也是数据的形式。
现在问题来了:
为什么我们要把ML作为一个独立的应用程序,并在ML模型、应用程序和数据库之间实现复杂的集成呢?
为什么不让ML成为数据库的核心功能呢?
为什么不让ML模型通过标准的数据库语法(如SQL)可用呢?
让我们分析上述问题及其面临的挑战,从而找到ML解决方案。
挑战#1:复杂的数据集成和ETL管道
维护ML模型和数据库之间的复杂数据集成和ETL管道,是ML流程面临的最大挑战之一。
SQL是极佳的数据操作工具,所以我们可以通过将ML模型引入数据层来解决这个问题。换句话说,ML模型将在数据库中学习并返回预测。
挑战#2:ML模型与应用程序的集成
通过API将ML模型与业务应用程序集成是面临的另一个挑战。
业务应用程序和BI工具与数据库紧密耦合。因此,如果AutoML工具成为数据库的一部分,我们就可以使用标准SQL语法进行预测。接下来,ML模型和业务应用程序之间不再需要API集成,因为模型驻留在数据库中。
解决方案:在数据库中嵌入AutoML
在数据库中嵌入AutoML工具会带来很多好处,比如:
任何使用数据并了解SQL的人(数据分析师或数据科学家)都可以利用机器学习的力量。
软件开发人员可以更有效地将ML嵌入到业务工具和应用程序中。
数据和模型之间以及模型和业务应用程序之间不需要复杂的集成。
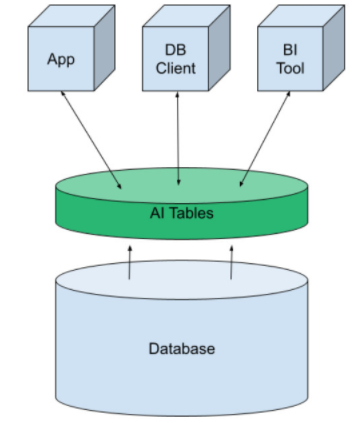
这样一来,上述相对复杂的集成图表变更如下:

它看起来更简单,也使ML过程更流畅高效。
如何实现自助式ML
将模型作为虚拟数据库表
找到解决方案的下一步是来实施它。
为此,我们使用了一个叫做AI Tables的结构。它以虚拟表的形式将机器学习引入数据平台。它可以像其他数据库表一样创建,然后向应用程序、BI工具和DB客户端开放。我们通过简单地查询数据来进行预测。
AI Tables最初由MindsDB开发,可以作为开源或托管云服务使用。他们集成了传统的SQL和NoSQL数据库,如Kafka和Redis。
使用AI Tables
AI Tables的概念使我们能够在数据库中执行ML过程,这样ML过程的所有步骤(即数据准备、模型训练和预测)都可以通过数据库进行。
训练AI Tables
首先,用户要根据自己的需求创建一个AI Table,它类似于一个机器学习模型,包含了与源表的列等价的特征;然后通过AutoML引擎自助完成剩余的建模任务。后文还将举例说明。
做预测
一旦创建了AI Table,它不需要任何进一步的部署就可以使用了。要进行预测,只需要在AI Table上运行一个标准SQL查询。
你可以逐个或分批地进行预测。AI Tables可以处理许多复杂的机器学习任务,如多元时间序列、检测异常等。
AI Tables工作示例
对于零售商来说,在适当的时间保证产品都有适当的库存是一项复杂的任务。当需求增长时,供给随之增加。基于这些数据和机器学习,我们可以预测给定的产品在给定的日期应该有多少库存,从而为零售商带来更多收益。
首先你需要跟踪以下信息,建立一张AI Table:
产品售出日期(date_of_sale)
产品售出店铺(shop)
具体售出产品(product_code)
产品售出数量(amount)
如下图所示:

1、训练AI Tables
要创建和训练AI Tables,你首先要允许MindsDB访问数据。详细说明可参考MindsDB文档( MindsDB documentation)。
AI Tables就像ML模型,需要使用历史数据来训练它们。
下面使用一个简单的SQL命令,训练一个AITable:

让我们分析这个查询:
使用MindsDB中的CREATE PREDICTOR语句。
根据历史数据定义源数据库。
根据历史数据表(historical_table)训练AI Table,所选列(column_1和column_2)是用来进行预测的特征。
AutoML自动完成剩下的建模任务。
MindsDB会识别每一列的数据类型,对其进行归一化和编码,并构建和训练ML模型。
同时,你可以看到每个预测的总体准确率和置信度,并估计哪些列(特征)对结果更重要。
在数据库中,我们经常需要处理涉及高基数的多元时间序列数据的任务。如果使用传统的方法,需要相当大的力气来创建这样的ML模型。我们需要对数据进行分组,并根据给定的时间、日期或时间戳数据字段对其进行排序。
例如,我们预测五金店卖出的锤子数量。那么,数据按商店和产品分组,并对每个不同的商店和产品组合作出预测。这就给我们带来了为每个组创建时间序列模型的问题。
这听起来工程浩大,但MindsDB提供了使用GROUP BY语句创建单个ML模型,从而一次性训练多元时间序列数据的方法。让我们看看仅使用一个SQL命令是如何完成的:

创建的stock_forecaster预测器可以预测某个特定商店未来将销售多少商品。数据按销售日期排序,并按商店分组。所以我们可以为每个商店预测销售金额。
2、批量预测
通过使用下面的查询将销售数据表与预测器连接起来,JOIN操作将预测的数量添加到记录中,因此我们可以一次性获得许多记录的批量预测。

如想了解更多关于在BI工具中分析和可视化预测的知识,请查看这篇文章。
3、实际运用
传统方法将ML模型视为独立的应用程序,需要维护到数据库的ETL管道和到业务应用程序的API集成。AutoML工具尽管使建模部分变得轻松而直接,但完整的ML工作流也仍然需要经验丰富的专家管理。其实数据库已经是数据准备的优选工具,因此将ML引入到数据库而非将数据引入ML中是更有意义的。由于AutoML工具驻留在数据库中,来自MindsDB的AI Tables构造能够为数据从业者提供自助AutoML并让机器学习工作流得以简化。
译者介绍
张怡,51CTO社区编辑,中级工程师。主要研究人工智能算法实现以及场景应用,对机器学习算法和自动控制算法有所了解和掌握,并将持续关注国内外人工智能技术的发展动态,特别是人工智能技术在智能网联汽车、智能家居等领域的具体实现及其应用。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 51CTO技术栈
51CTO技术栈
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675