
超干货!一文概览 NLP 算法

作者 | 算法进阶
来源 | 算法进阶
一、自然语言处理(NLP)简介
NLP,自然语言处理就是用计算机来分析和生成自然语言(文本、语音),目的是让人类可以用自然语言形式跟计算机系统进行人机交互,从而更便捷、有效地进行信息管理。
二、NLP主要任务及技术


高清图可如下路径下载(原作者graykode): https://github.com/aialgorithm/AiPy/tree/master/Ai%E7%9F%A5%E8%AF%86%E5%9B%BE%E5%86%8C/Ai_Roadmap
2.1 数据清洗 + 分词(系列标注任务)
数据语料清洗。我们拿到文本的数据语料(Corpus)后,通常首先要做的是,分析并清洗下文本,主要用正则匹配删除掉数字及标点符号(一般这些都是噪音,对于实际任务没有帮助),做下分词后,删掉一些无关的词(停用词),对于英文还需要统一下复数、语态、时态等不同形态的单词形式,也就是词干/词形还原。 分词。即划分为词单元(token),是一个常见的序列标注任务。对于英文等拉丁语系的语句分词,天然可以通过空格做分词, 
对于中文语句,由于中文词语是连续的,可以用结巴分词(基于trie tree+维特比等算法实现最大概率的词语切分)等工具实现。
import?jieba
jieba.lcut("我的地址是上海市松江区中山街道华光药房")
>>>?['我',?'的',?'地址',?'是',?'上海市',?'松江区',?'中山',?'街道',?'华光',?'药房']
英文分词后的词干/词形等还原(去除时态 语态及复数等信息,统一为一个“单词”形态)。这并不是必须的,还是根据实际任务是否需要保留时态、语态等信息,有WordNetLemmatizer、 SnowballStemmer等方法。 分词及清洗文本后,还需要对照前后的效果差异,在做些微调。这里可以统计下个单词的频率、句长等指标,还可以通过像词云等工具做下可视化~
from?wordcloud?import?WordCloud
ham_msg_cloud?=?WordCloud(width?=520,?height?=260,max_font_size=50,?background_color?="black",?colormap='Blues').generate(原文本语料)
plt.figure(figsize=(16,10))
plt.imshow(ham_msg_cloud,?interpolation='bilinear')
plt.axis('off')?#?turn?off?axis
plt.show()

2.2 词性标注(系列标注任务)

2.3 命名实体识别(系列标注任务)

2.4 词向量(表示学习)
One-hot编码:最简单的表示方法某过于onehot表示,每个单词是否出现就用一位数单独展示。进一步,句子的表示也就是累加每个单词的onehot,也就是常说的句子的词袋模型(bow)表示。
##?词袋表示
from?sklearn.feature_extraction.text?import?CountVectorizer
bow?=?CountVectorizer(
????????????????analyzer?=?'word',
????????????????strip_accents?=?'ascii',
????????????????tokenizer?=?[],
????????????????lowercase?=?True,
????????????????max_features?=?100,?
????????????????)

词嵌入分布式表示:自然语言的单词数是成千上万的,One-hot编码会有高维、词语间无联系的缺陷。这时有一种更有效的方法就是——词嵌入分布式表示,通过神经网络学习构造一个低维、稠密,隐含词语间关系的向量表示。常见有Word2Vec、Fasttext、Bert等模型学习每个单词的向量表示,在表示学习后相似的词汇在向量空间中是比较接近的。
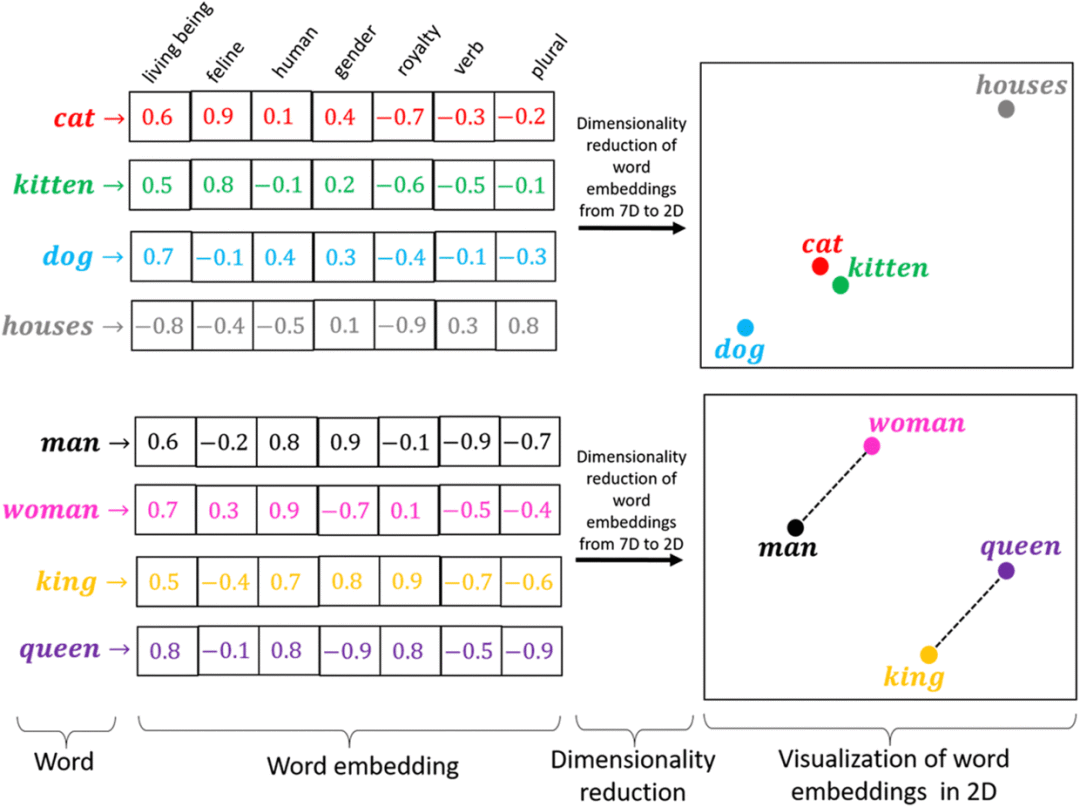
#?Fasttext?embed模型
from?gensim.models?import?FastText,word2vec
model?=?FastText(text,??size=100,sg=1,?window=3,?min_count=1,?iter=10,?min_n=3,?max_n=6,word_ngrams=1,workers=12)
print(model.wv['hello'])?#?词向量
model.save('./data/fasttext100dim')

对于学习后的词表示向量,还可以通过重要程度进行特征加权,合适的加权方法对于任务可以有不错的提升效果。常用的有卡方chi2、TF-IDF等加权方法。TF-IDF是一种基于统计的方法,其核心思想是假设字词的重要性与其在某篇文章中出现的比例成正比,与其在其他文章中出现的比例成反比。 
#?TF-IDF可以直接调用sklearn
from?sklearn.feature_extraction.text?import?TfidfTransformer
2.5 句法、语义依存分析
句法、语义依存分析是传统自然语言的基础句子级的任务,语义依存分析是指在句子结构中分析实词和实词之间的语义关系,这种关系是一种事实上或逻辑上的关系,且只有当词语进入到句子时才会存在。语义依存分析的目的即回答句子的”Who did what to whom when and where”的问题。例如句子“张三昨天告诉李四一个秘密”,语义依存分析可以回答四个问题,即谁告诉了李四一个秘密,张三告诉谁一个秘密,张三什么时候告诉李四一个秘密,张三告诉李四什么。

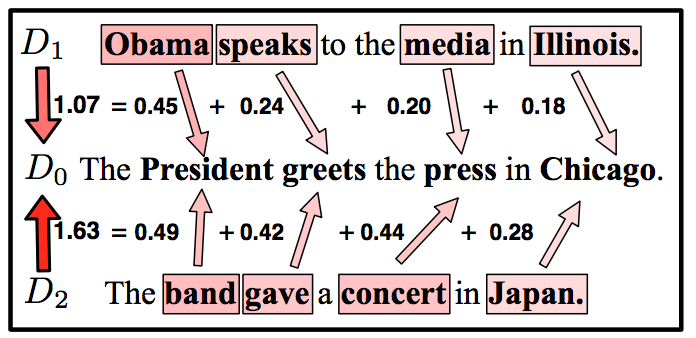
2.6 相似度算法(句子关系的任务)
2.7 文本分类任务
一种是输入序列输出这整个序列的类别,如短信息、微博分类、意图识别等。 另一种是输入序列输出序列上每个位置的类别,上文提及的系列标注可以看做为词粒度的一种分类任务,如实体命名识别。

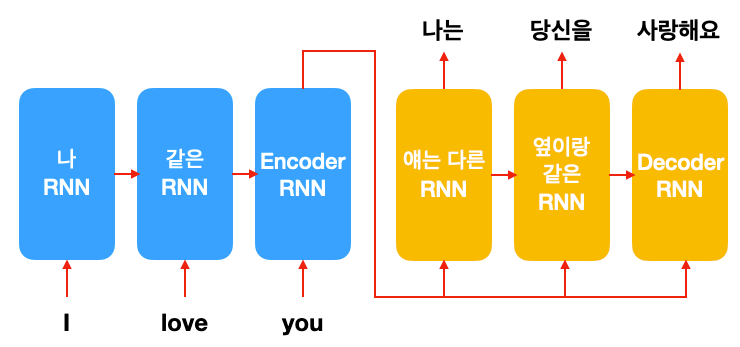
2.8 文本生成任务
三、垃圾短信文本分类实战
3.1 读取短信文本数据并展示
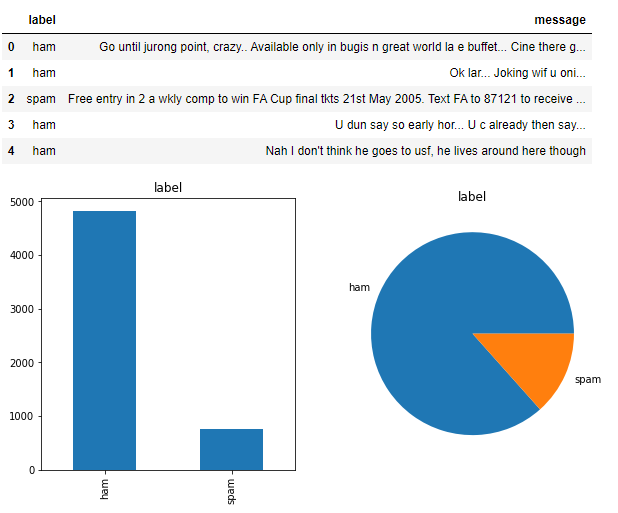
#?源码可见https://github.com/aialgorithm/Blog
import?pandas?as?pd
import?numpy?as?np
import??matplotlib.pyplot?as?plt
spam_df?=?pd.read_csv('./data/spam.csv',?header=0,?encoding="ISO-8859-1")
#?数据展示
_,?ax?=?plt.subplots(1,2,figsize=(10,5))
spam_df['label'].value_counts().plot(ax=ax[0],?kind="bar",?rot=90,?title='label');
spam_df['label'].value_counts().plot(ax=ax[1],?kind="pie",?rot=90,?title='label',?ylabel='');
print("Dataset?size:?",?spam_df.shape)
spam_df.head(5)
3.2 数据清洗预处理
#?导入相关的库
import?nltk
from?nltk?import?word_tokenize
from?nltk.corpus?import?stopwords
from?nltk.data?import?load
from?nltk.stem?import?SnowballStemmer
from?string?import?punctuation
import?re??#?正则匹配
stop_words?=?set(stopwords.words('english'))
non_words?=?list(punctuation)
#?词形、词干还原
#?from?nltk.stem?import?WordNetLemmatizer
#?wnl?=?WordNetLemmatizer()
stemmer?=?SnowballStemmer('english')
def?stem_tokens(tokens,?stemmer):
????stems?=?[]
????for?token?in?tokens:
????????stems.append(stemmer.stem(token))
????return?stems
###?清除非英文词汇并替换数值x
def?clean_non_english_xdig(txt,isstem=True,?gettok=True):
????txt?=?re.sub('[0-9]',?'x',?txt)?#?去数字替换为x
????txt?=?txt.lower()?#?统一小写
????txt?=?re.sub('[^a-zA-Z]',?'?',?txt)?#去除非英文字符并替换为空格
????word_tokens?=?word_tokenize(txt)?#?分词
????if?not?isstem:?#是否做词干还原
????????filtered_word?=?[w?for?w?in?word_tokens?if?not?w?in?stop_words]??#?删除停用词
????else:
????????filtered_word?=?[stemmer.stem(w)?for?w?in?word_tokens?if?not?w?in?stop_words]???#?删除停用词及词干还原
????if?gettok:???#返回为字符串或分词列表
????????return?filtered_word
????else:
????????return?"?".join(filtered_word)
spam_df['token']?=?spam_df.message.apply(lambda?x:clean_non_english_xdig(x))
spam_df.head(3)
#?数据清洗
spam_df['token']?=?spam_df.message.apply(lambda?x:clean_non_english_xdig(x))
#?标签整数编码
spam_df['label']?=?(spam_df.label=='spam').astype(int)
spam_df.head(3)

3.3 fasttext词向量表示学习
#?训练词向量?Fasttext?embed模型
from?gensim.models?import?FastText,word2vec
fmodel?=?FastText(spam_df.token,??size=100,sg=1,?window=3,?min_count=1,?iter=10,?min_n=3,?max_n=6,word_ngrams=1,workers=12)
print(fmodel.wv['hello'])?#?输出hello的词向量
#?fmodel.save('./data/fasttext100dim')
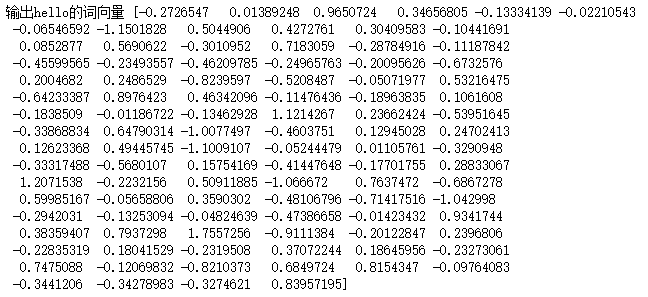
fmodel?=?FastText.load('./data/fasttext100dim')
#对每个句子的所有词向量取均值,来生成一个句子的vector
def?build_sentence_vector(sentence,w2v_model,size=100):
????sen_vec=np.zeros((size,))
????count=0
????for?word?in?sentence:
????????try:
????????????sen_vec+=w2v_model[word]#.reshape((1,size))
????????????count+=1
????????except?KeyError:
????????????continue
????if?count!=0:
????????sen_vec/=count
????return?sen_vec
#?句向量
sents_vec?=?[]
for?sent?in?spam_df['token']:
????sents_vec.append(build_sentence_vector(sent,fmodel,size=100))
????????
print(len(sents_vec))
3.4 训练文本分类模型
###?训练文本分类模型
from?sklearn.model_selection?import?train_test_split
from?lightgbm?import?LGBMClassifier
from?sklearn.linear_model?import?LogisticRegression
train_x,?test_x,?train_y,?test_y?=?train_test_split(sents_vec,?spam_df.label,test_size=0.2,shuffle=True,random_state=42)
result?=?[]
clf?=?LGBMClassifier(class_weight='balanced',n_estimators=300,?num_leaves=64,?reg_alpha=?1,reg_lambda=?1,random_state=42)
#clf?=?LogisticRegression(class_weight='balanced',random_state=42)
clf.fit(train_x,train_y)
import?pickle
#?保存模型
pickle.dump(clf,?open('./saved_models/spam_clf.pkl',?'wb'))
#?加载模型
model?=?pickle.load(open('./saved_models/spam_clf.pkl',?'rb'))
3.5 模型评估
from?sklearn.metrics?import?auc,roc_curve,f1_score,precision_score,recall_score
def?model_metrics(model,?x,?y,tp='auc'):
????"""?评估?"""
????yhat?=?model.predict(x)
????yprob?=?model.predict_proba(x)[:,1]
????fpr,tpr,_?=?roc_curve(y,?yprob,pos_label=1)
????metrics?=?{'AUC':auc(fpr,?tpr),'KS':max(tpr-fpr),
???????????????'f1':f1_score(y,yhat),'P':precision_score(y,yhat),'R':recall_score(y,yhat)}
????
????roc_auc?=?auc(fpr,?tpr)
????plt.plot(fpr,?tpr,?'k--',?label='ROC?(area?=?{0:.2f})'.format(roc_auc),?lw=2)
????plt.xlim([-0.05,?1.05])??#?设置x、y轴的上下限,以免和边缘重合,更好的观察图像的整体
????plt.ylim([-0.05,?1.05])
????plt.xlabel('False?Positive?Rate')
????plt.ylabel('True?Positive?Rate')??#?可以使用中文,但需要导入一些库即字体
????plt.title('ROC?Curve')
????plt.legend(loc="lower?right")
????return?metrics
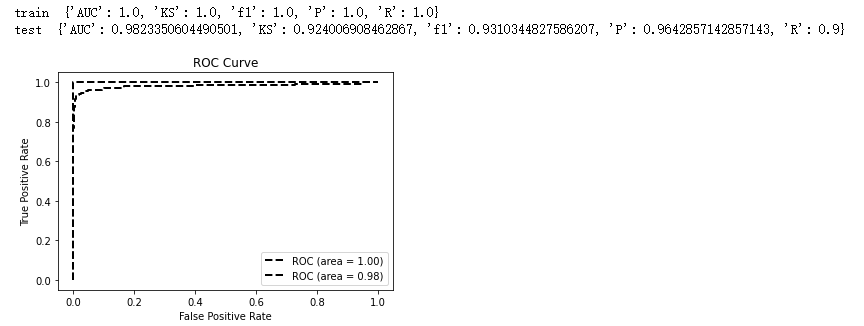
print('train?',model_metrics(clf,??train_x,?train_y,tp='ks'))
print('test?',model_metrics(clf,?test_x,test_y,tp='ks'))


分享
点收藏
点点赞
点在看




关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675