统计学常犯错误TOP榜,避坑防雷指南!
本文约2400字,建议阅读5分钟
本文为你总结统计学常犯错误。
实际上完全没有关系的变量,在利用样本数据进行计算时也可能得到一个较大的相关系数值(尤其是时间序列数值) 当样本数较少,相关系数就很大。当样本量从100减少到40后,相关系数大概率会上升,但上升到多少,这个就不能保证了;取决于你的剔除数据原则,还有这组数据真的可能不存在相关性;
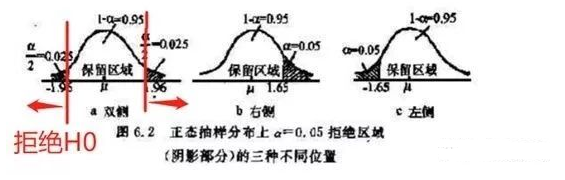
显著性水平: 通过小概率准则来理解,在假设检验时先确定一个小概率标准----显著性水平;用? ?表示;凡出现概率小于显著性水平的事件称小概率事件;
通过两类错误理解:? ?为拒绝域面积

自变量之间不能存在完全共线性; 总体方程误差项服从均值为0的正态分布(大数定理) 误差项的方差不受自变量影响且为固定值;(同方差性)
最小二乘法是基于几何意义上距离最小 最大似然估计是基于概率意义上出现的概率最大 最小二乘法:对数据分布无要求 最大似然估计:需要知道概率密度函数
1)H0与H1是完备事件组,相互对立,有且只有一个成立
2)在确立假设时,先确定备设H1,然后再确定H0,且保证“=”总在H0上
3)原H0一般是需要反驳的,而H1是需要支持的
4)假设检验只提供原假设不利证据
当原假设为真时,比所得到的样本观察,结果更极端的结果会出现的概率。 如果P值很小,我们拒绝原假设的理由越充分。 P的意义不表示两组差别大小,p反映两组差别有无统计学意义 显著性检验只是统计结论,判断差别还需要专业知识;
当样本容量n够大,样本观察值符合正态分布,可采用U检验 当样本容量n较小,若观测值符合正态分布,可采用T型检验
组间变异:由于不同实验处理而造成的各组之间的变异 组内变异:组内各被适变量的差异范围所呈现的变异

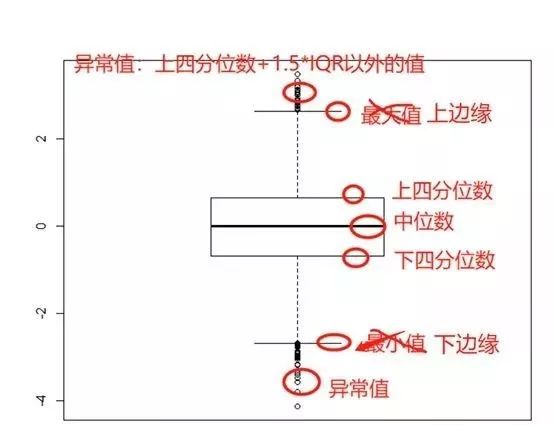
第一四分位数:下四分位数;等于该样本中所有数值由小到大排列后第25%的数字(所以下四分位数可以不是样本中的数值,它是一个统计指标(就像平均数一样,不一定是原数据中的一点) 第二四分位数:中位数 第三四分位数:上四分位数
「完」

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 中共中央召开党外人士座谈会 7904889
- 2 日本又发生6.6级地震 7809114
- 3 王毅:台湾地位已被“七重锁定” 7712222
- 4 全国首艘氢电拖轮作业亮点多 7618100
- 5 中国游客遇日本地震:连滚带爬躲厕所 7521610
- 6 日本震中突发大火 民众开车逃命 7428561
- 7 日本地震致多人受伤 超10万人需避难 7328641
- 8 男子带老婆买糖葫芦被认成父女 7236279
- 9 高速公路上一车龟速占道引众怒 7138673
- 10 “人造太阳”何以照进现实 7039932