
什么场景下,不适合使用Apache Kafka?

译者 | 吉锴
策划 | 云昭
Apache Kafka是处理流式数据的事实标准。随着它在各行各业中的广泛应用,我经常会听到一个非常有意思的问题:我什么时候不适合使用Apache Kafka?流式数据处理平台有哪些限制?Kafka在在什么场合下不能胜任?
这篇文章探讨了Kafka擅长做的和不擅长做的场景。并且用单独的章节列出了何时适合使用Kafka,何时不适合使用Kafka,以及何时可以将Kafka作为可选项。

首先,Kafka的应用如此广泛,已经证明了其在流式事件处理领域有着巨大的市场需求。但同时也要注意:Kafka并没有提供流式事件处理领域的完整解决方案。简言之,Kafka不是银弹,而是流式事件处理领域中一个至关重要的组成部分!
今天所在的世界,信息互联互通变得无处不在。这种越来越紧密的连接生成了大量相互关联的实时数据。通过对这些数据的处理和加工,企业可以有效的降低成本和风险,并提高业务收入。
车联网和游戏就是其中两个最典型的例子。
车联网
大量的采集数据和售后服务
以下是Allied Market Research制作的2020-2027年全球机会分析和行业预测:

车联网领域所涉及到的场景和行业比大多数人想象的要广泛得多,比如:网络基础设施、安全、娱乐、零售、售后市场、车辆保险、智慧城市等场景。
游戏行业
数十亿的玩家和庞大的收入
正如Bitkraft所描述的那样,游戏行业已经超过了所有其他媒体类别的总和,而这只是一个新时代的开始:

全球每个月都有数百万新玩家加入到游戏社区。那些生活在不富裕国家的玩家,现在也可以负担得起平价的智能手机和移动网络资费。而新的游戏商业模式,比如通过玩游戏来赚钱,会改变下一代玩家玩游戏的方式。5G等更具可扩展性和低延迟的技术支持新的场景出现。区块链和NFT(非同质化代币)正在永远改变货币形态和收藏市场。
这些趋势数据印证了实时数据处理的需求日益增加。因此了解何时在项目中使用已经成为大规模数据处理分析和业务数据流的事实标准的Apache Kafka及其生态系统就变得很有价值。
?Apache Kafka能做什么
不能做什么?
一些开发者常常对Kafka功能存在着误解。例如认为Kafka只是一个消息队列。这很大程度上是由于一些供应商为了销售他们的产品,而只针对Kafka的特定功能(例如将数据导入到数据湖或数据仓库)进行介绍。
Kafka能做什么:
一个可扩展的实时消息平台,每秒可处理数百万条消息 用于海量大数据分析和少量业务数据处理的事件流平台 支持分布式存储,具有消息缓存功能,支持各种通信协议,支持按顺序消息重放。 流式ETL的数据集成框架 用于连续无状态或有状态流处理的数据处理框架 Kafka成功的在一个平台上结合了全部这些特点。
Kafka不能做什么:
不是一个数百万客户端(如移动应用程序)的接入网关;但Kafka原生代理(如REST或MQTT)适用于某些场景 不是一个接口管理平台,但这些工具通常是互补的;用于Kafka API的创建、生命周期管理或货币化 不是一个用于复杂查询和执行批处理分析的数据库;但可以胜任业务查询和相对简单的聚合(尤其是使用ksqlDB) 不是一个具有设备管理等功能物联网平台;但可以直接与支持某些物联网协议(如MQTT或OPC-UA)的设备进行集成,并且是一些场景下的推荐做法。 不是一种用于完全实时系统(如安全关键或确定性系统)框架,但对于任何其他IT框架也是如此,毕竟嵌入式系统是一种不同的软件。
由此可见,Kafka与其他技术是互补的,而不是竞争性的。因此我们应该根据任务的特点选择是否使用Kafka,并将它和其他的框架结合使用!
万物互联世界中Apache Kafka
Kafka与其他技术结合的成功例子不在少数,这些案例展示了Kafka如何解决了业务问题。这里的重点是对案例的研究,实际上对于端到端数据流解决方案,Kafka往往需要和其他组件配合使用。
在Apache Kafka的实时数据流方面,已经有大量用于车联网、物联网边缘计算、移动互联网游戏等领域得大数据分析或业务数据处理得成功案例。
这里我列出了几个不同行业和场景的案例:
奥迪:推出跨地区和跨云供应商的车联网平台
宝马:高效物流和供应链的智能工厂
Solar Power:提供完整的太阳能解决方案和服务
皇家加勒比:以混合云部署、支持离线的边缘服务为基础构建得游轮娱乐系统
迪士尼+Hotstar:为数百万粉丝提供在智能手机上的交互式媒体和游戏/博彩?
?
像这样的案例一直在不断的增加。
然而我们需要进一步说明何时在Apache Kafka系统中使用事件流,以及其他补充解决方案如何和为Kafka提供补充。
何时适合使用Apache Kafka
在讨论什么时候不使用Kafka之前,让我们先了解应该再何时使用Kafka,并了解如何使用其他技术来补充Kafka。我将在每个部分中添加真实示例。这会使得理解这些场景变得更加容易。
1、通过Kafka实时处理物联网和移动端大数据
大数据实时处理是Kafka的关键能力之一。
特斯拉不仅仅是一家汽车制造商。还是一家科技公司,他开发了大量创新和尖端软件。他们为汽车提供能源基础设施,包括特斯拉超级充电站、生产太阳能得超级工厂的等等。特斯拉成功的关键技术之一,就是实时处理处理和分析来自汽车智能电网和工厂的数据,并与其他IT后端服务集成。
特斯拉建立了一个基于Kafka的数据平台基础设施,支持数百万台设备和数万亿个数据埋点。2019年,特斯拉在Kafka峰会上展示了他们实时数据业务的演进过程:

请注意,Kafka的作用不仅是信息传递。Kafka是一个分布式存储层,它真正将生产者和消费者解耦。此外,Kafka原生处理工具(如Kafka Streams和ksqlDB)支持实时处理。
2、通过Kafka将物联网数据集成到MES和ERP等业务系统
Kafka Connect和其他非Kafka中间件为大规模实时数据集成系统与业务系统(如ERP或MES系统)提供了核心的事件流功能。
BMW在边缘节点(即智能工厂)和公有云上部署了着执行重要任务的Kafka实例。对制造业的来说每一分钟的停机时间都会耗费大量资金,因此稳定性就会变得至关重要。而Confluent的Kafka发行版本相比较原生Kafka在稳定性上有了大幅度提高。
宝马通过对供应链的实时优化和管理。实现了在业务系统(如基于SAP的宝马ERP)中实现正确的物理库存的信息。我在该领域接触的近50%的客户,都在使用Kafka和SAP互相集成的方案。除了和SAP集成,许多下一代ERP和MES平台也直接使用了Kafka作为底层技术支持。
3、通过Kafka将部署在边缘端、混合云或多云的非物联网IT系统集成到企业系统。
将Apache Kafka部署在多集群和跨数据中心已成为常态。一些特定的需求可能需要采用多集群解决方案,包括灾难恢复、聚合分析、云迁移、关键任务扩展部署、全球Kafka。
4、通过Kafka为跨行业应用提供可基于混合云部署的现代化基础设施。
这方面以Unity公司为例,该公司提供了一个游戏实时3D开发平台,并凭借其AR/VR功能成功进入制造业等其他行业。2019年,这家数据驱动公司产品生成的内容已经在全球达到30亿部设备安装,安装次数已经达到330亿次。同时Unity运营着世界上最大的盈利网络之一。他们的项目团队将这个平台从自建的Kafka迁移到了托管的Confluent 云上,过程中没有停机或数据丢失。?
5、Kafka为移动服务和游戏/博彩平台提供可扩展的实时后端
许多游戏和移动服务都将事件流作为其基础设施的支柱。使用场景包括用户行为分析、基于位置的服务、支付、欺诈检测、用户/玩家留存率和用户粘性的处理。游戏和移动服务领域几乎所有的应用都需要大规模的实时数据流。
例如:
移动服务:优步、Lyft、FREE NOW、Grab、Otonomo和Here Technologies 游戏服务:迪士尼+Hotstar、索尼Playstation、腾讯、大鱼游戏 博彩服务:威廉山、天空博彩
一个有意思的现象是:并不是每家移动或游戏服务的厂商都在公开谈论Kafka的使用,但几乎每家都在寻找Kafka专家来开发和运营他们的平台。
这些场景对安全性的要求与银行核心平台中的支付流程一样高。遵守合规性和零数据丢失也是至关重要。因此利用Kafka多区域集群(例如跨越美国东部、中部和西部等地区的Kafka集群)实现了高可用性,即使在发生灾难的情况下也不会出现停机和数据丢失。

游戏中的多区域Kafka集群示例
6、在车辆或物联网设备中内嵌单独Kafka实例
边缘计算技术在日新月异的发展,出于低延迟、成本效率、网络安全或没有互联网连接等原因的考量,某些场景需要在数据中心外的边缘部署Kafka集群或实例。
边缘的Kafka的例子包括:
在交通运输过程中无法连接到中心服务器时(例如,街道上的卡车或围绕船舶飞行的无人机),用于离线时存储日志、传感器数据和图像。 车辆到周边(V2X)通信场景,通过本地小型数据中心(如AWS Outposts)构建MQTT网关,适用于大面积、大量车辆或糟糕的网络,或通过Kafka客户端直连数百台机器(如在智能工厂中)等。 线下移动服务,如将汽车基础设施与地图集成,或将推荐引擎与本地服务的合作伙伴集成(例如,10英里内出现的下一个麦当劳会提供优惠券)
皇家加勒比游轮一个成功案例。它经营着世界上四艘最大的游轮。截至2021年1月,该航线运营24艘船舶,另有6艘船舶在订购中。皇家加勒比在边缘侧实现了最著名的Kafka场景之一。每艘游轮都有一个Kafka集群在本地运行,用于支付处理、用户粘性、客户推荐等业务。

Kafka边缘部署要注意根据实际业务场景做出调整,这样才能保证足够的低时延性能。
Apache Kafka的搁浅区
在本节中,假设我们讨论的是生产环境,而不是一些丑陋的变通方式,当你需要在全球范围内部署和弹性伸缩、遵守合规性并保证业务性服务不会丢失数据时,情况就会发生变化。考虑到这一点,对于一些用例和问题来说,把Kafka排除在外是相对容易的:?
1、Kafka不是完全实时的
实时一词的定义很难。这通常是一个营销术语。实时程序必须保证在指定的时间限制内做出响应。Kafka(以及在此上下文中使用的所有其他框架、产品和云服务)只是相对实时的,并且是为IT应用构建的。但是许多自动化控制和物联网应用需要具有零延迟峰值的完全实时。
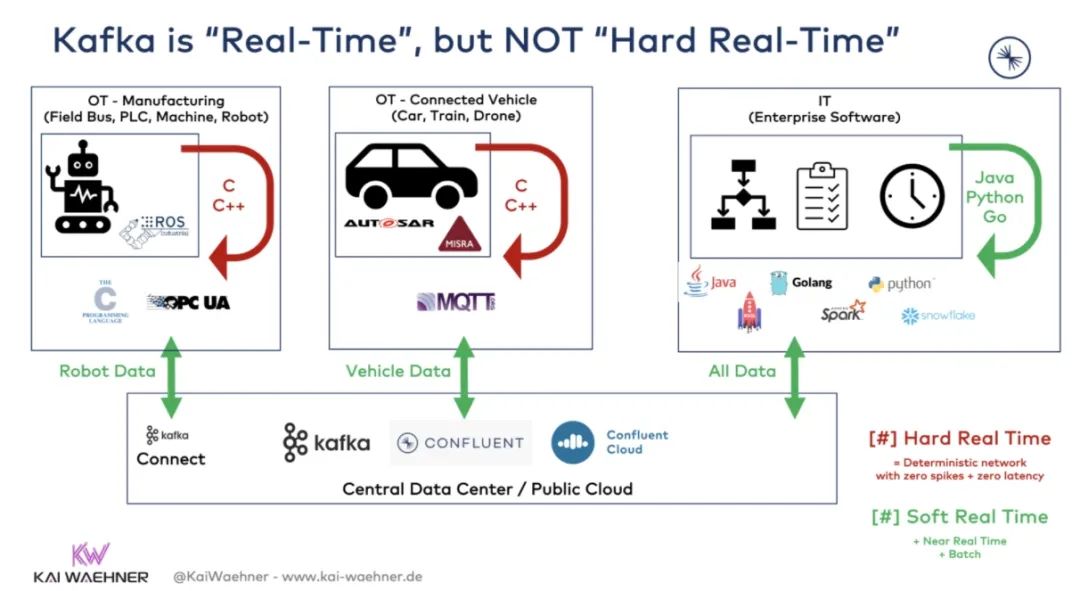
Kafka是实时的,但不是完全实时的。相对实时通常用于以下应用:
IT应用程序之间的点对点消息传递
从各种数据源到归集到一个或多个数据接收器
数据处理和数据关联(通常称为事件流或事件流处理)
如果应用程序需要亚毫秒的延迟,那么Kafka不是合适的技术。例如,高频交易通常通过专门构建的专有商业解决方案来实现。
请始终记住:在争取最低延迟的比赛中,Kafka每次都会输,最低延迟的最佳方案是根本不使用消息传递系统,而是只使用共享内存。然而,对于审计日志和业务日志或持久化引擎的交换部分来说,没有什么数据丢失比延迟和Kafka的胜利更重要。?实际上大多数实时场景只需要毫秒到秒范围内的数据处理。在这种情况下,Kafka是一个完美的解决方案。许多金融科技公司,如罗宾汉,依赖Kafka完成关键任务的业务工作,甚至是金融交易。多接入边缘计算(MEC)则是通过Apache Kafka和云原生5G基础设施构建的低延迟数据流的另一个优秀示例。
2、Kafka对于嵌入式和安全关键型系统来说是不确定的
需要明确的是,Kafka不是一个确定性系统。不能用于汽车发动机控制系统、医疗系统(如心脏起搏器)或工业过程控制器等安全关键型应用程序。
Kafka不适用的典型场景如下:
汽车或车辆中的安全关键数据处理,包括Autosar/MINRA/Assembler和类似技术 ECU之间的CAN总线通信 机器人技术:C/C++或类似的低级语言,与工业ROS(机器人操作系统)等框架相结合 安全关键机器学习/深度学习(例如,用于自动驾驶) 车对车(V2V)通信:5G sidelink不能使用类似Kafka的转发。
安全相关数据处理并非Kafka能胜任的,必须使用专用的低级编程语言和解决方案来实现。同样,类Kafka 的软件如IBM MQ、Flink、Spark、Snowflake也不适用。
3、Kafka不是为不稳定的网络而建
Kafka需要客户端和实例之间良好稳定的网络连接。因此,如果网络不稳定,导致客户端需要不停的尝试重新连接,那么这种情况往往很难达到预先设定的SLA。
也有一些例外,例如通过其他技术来解决不良网络问题而构建的。MQTT是最典型的例子。因此,Kafka和MQTT是朋友,而不是敌人。这种组合功能强大,在各个行业中广泛使用。因此,我写了一系列关于Kafka和MQTT的Blog。
例如我们使用MQTT、Kafka和TensorFlow构建了一个Kappa架构的汽车连接基础设施,用于处理100000个数据流以进行实时预测。
4、Kafka不提供与成千上万个客户端的连接
将Kafka定义为集成解决方案的另一个具体点是,Kafka无法连接到数万个客户端。如果您需要为移动玩家构建互联汽车基础设施或游戏平台,客户端(即汽车或智能手机)将通过一个集成了Kafka 的解决方案连接,而不会直接连接到Kafka。
一般来说在数千个客户端和Kafka之间加入一个专用代理(如HTTP网关或MQTT代理)负责客户端和Kafka的连接,而数据最终会被Kafka集成到数据仓库,数据湖或者自定义后端应用中。
Kafka客户端连接的限制在哪里? 通常情况下,这很难说。?我看到客户通过.net直接从工厂车间连接,通过Java Kafka客户端直接连接到运行Kafka集群的云。?如果机器plc、物联网网关和物联网设备的数量在数百台,直接混合连接通常会工作得很好。?对于更多的客户端应用程序,开发者需要针对以下问题来进行评估:?
中间是否需要一个代理
在边缘及项目是否需要部署Kafka,以降低延迟和并提高经济消息
?什么时候有可能使用
Apache Kafka?
这里探讨一下哪些场景中Kafka是可选的选择。
1、Kafka(通常)不会替换另一个数据库
Apache Kafka本身是一个提供了ACID保证,并被数百家公司用于任务关键型部署的数据库。然而大多数情况下Kafka与其他数据库相比并没有竞争力。Kafka是一个事件流平台,用于实时大规模的消息传递、存储、处理和集成,并保证无停机时间或无数据丢失。
Kafka通常被用作流式数据集成层。然后根据应用场景选择其他数据库作为实体视图,如实时时序分析、近似实时的将文本导入搜索基础设施、或通过数据湖进行数据的长期存储。
总之,当你被问及Kafka是否可以取代数据库时,可以进行如下的回答:
Kafka可以以持久和高可用性的方式永久存储数据,提供ACID保证。 Kafka提供了多种方式查询历史数据。 Kafka原生的插件,如ksqlDB或分级存储,为Kafka提供了强大的数据处理和基于事件的长期存储能力。 无需其他外部数据库,即可利用Kafka构建有状态应用程序。 不能替代现有的数据库、数据仓库或数据湖,比如MySQL、MongoDB、Elasticsearch、Hadoop、Snowflake、谷歌BigQuery等。 其他类型数据库往往和Kafka相辅相成,通常创建和更新实体视图的实时数据往往来源于事件中心。 Kafka和数据库之间数据同步,有基于双向拉和推集成有不同的选项,可以相互补充。
2、Kafka(通常)不处理大型消息
Kafka不是为大型信息而设计的。
但是越来越多的项目通过Kafka发送和处理1MB、10MB甚至更大的文件或其他的大消息体。一个原因是Kafka是为大容量/吞吐量设计的,这是大消息所需要的。经常出现的一个非常常见的用法是,使用Kafka从遗留系统中提取和处理大文件。并处理过的数据存入数据仓库。然而并不是所有的大消息都适合用Kafka处理。一般来说您应该使用正确的存储系统,仅仅利用Kafka进行编排。基于引用的消息传递(即将文件存储在存储系统中并只发送链接和元数据)通常是更好的设计模式:

了解不同的设计模式,并为选择正确的技术。
有关使用Kafka处理大型文件的更多详细信息和场景,请参阅以下博客文章:《使用Apache Kafka处理大型消息(CSV、XML、图像、视频、音频、文件)》。
3、Kafka(通常)不作为物联网工业协议的最后一公里集成网关
物联网设备和移动应用程序的最后一公里集成是一个棘手的问题。如上所述,Kafka无法连接到数千个客户端。然而,许多物联网和移动应用只有数十或数百个客户端。在这种情况下,就可以使用世界上几乎任何编程语言的都提供支持各种Kafka客户端,直连到Kafka实例。
如果出现了无法在TCP协议层面上建立到Kafka服务端的连接的情况下。一个非常流行的解决方案是通过REST代理作为客户端和Kafka集群之间的代理。客户端通过同步HTTP(S)协议与REST代理通信。Apache Kafka的HTTP和REST API场景包括控制平面(=管理)、数据平面(=生成和消费消息)和DevOps自动化任务。
不幸的是,许多物联网项目需要更复杂的集成。这里不能只讨论通过MQTT或OPC-UA连接器进行的相对简单的集成。工业物联网项目面临的挑战包括:
自动化行业通常不使用开放标准,而是使用速度慢、不安全、不可扩展的专有标准。 产品的生命周期非常长(几十年),没有简单的更改或升级的方法。 物联网常使用不兼容的协议,通常为一个特定的供应商专用。 不可伸缩且不可扩展,专有且昂贵的庞然大物。
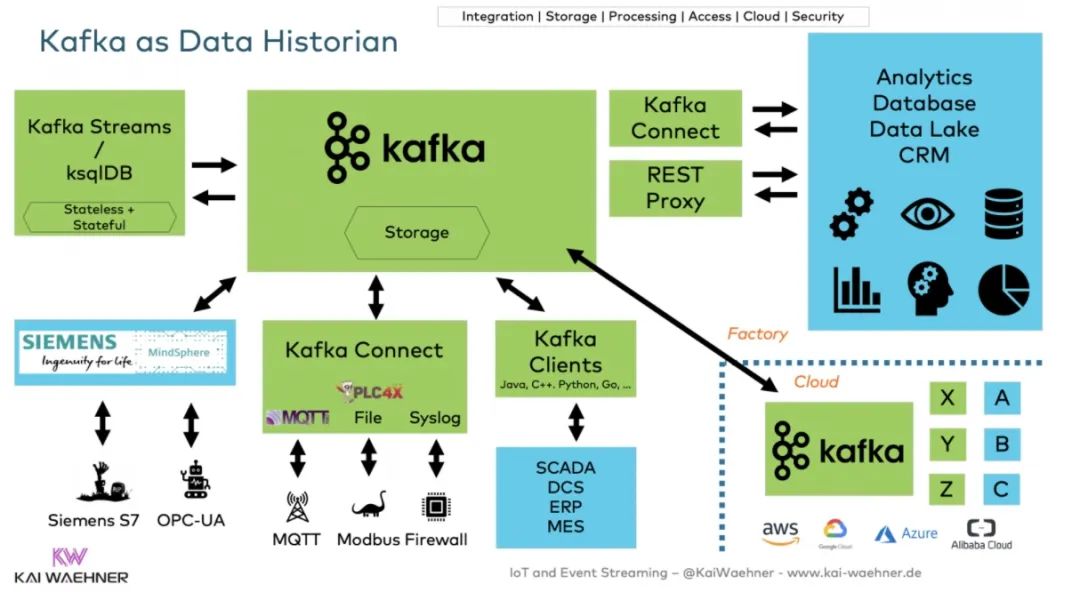
因此,许多物联网项目用一个专门构建的物联网平台来补充Kafka。大多数物联网产品和云服务是专有的,但提供开放的接口和架构。在这个行业中开源的项目相对较少。一个很好的方案(对于某些场景)是Apache PLC4X。该框架集成了许多遗留专有的协议,如Siemens S7、Modbus、Allen Bradley、Beckhoff ADS等。PLC4X还提供了一个Kafka Connect连接器,用于本地和可扩展的Kafka集成。
现代数据记录系统是开放和灵活的。许多基于混合云的现代化物联网项目是由事件流驱动的:
4、Kafka与区块链
Kafka不是区块链(但与web3、加密交易、NFT、链外、侧链、预言机相关)。
Kafka是一个分布式日志提交系统。这些概念和基础非常类似于区块链。对于大多数企业项目,区块链会增加不必要的复杂性。这种情况下用一个分布式提交日志(= Kafka)或一个防篡改分布式账本(= enhanced Kafka)就足够了。只有当不同的不受信任方需要协作时,才应使用区块链。
有趣的是,越来越多的公司在其加密交易平台、市场交易所和代币交易市场中使用Kafka。
需要明确的是:Kafka并不用于构成这些平台上的区块链。区块链是一种像比特币一样的加密货币,或者像以太坊一样提供智能合约的平台,人们可以在那里为游戏或艺术行业构建新的分布式应用程序(dApps),如NFT。Kafka是将这些区块链与其他预言机(=非区块链应用)连接起来的流平台,如CRM,数据湖,数据仓库等。

TokenAnalyst是一个典型的例子,它用Kafka把比特币/以太坊的区块链数据和他们的分析工具集成起来。Kafka Streams提供了一个有状态的流式应用程序来防止在下游聚合计算中使用无效块。例如,TokenAnalyst开发了一个块确认器组件,该组件通过临时保留块来解决重组场景,并仅在达到大量确认(挖掘该块的子块)的阈值时进行传播。
在一些高级场景中,Kafka用于实现边链或链外平台,因为原始区块链的扩展性不够好(区块链称为链上数据)。并非只有比特币存在每秒只处理个位数交易的问题(!)。大多数现代区块链解决方案的性能没有办法扩展到Kafka的处理速度。
无论是去中心化自治组织还是蓝筹公司,在分布式网络中衡量区块链基础设施和物联网组件的健康状况,避免停机,确保基础设施的安全,并使区块链数据可访问都是非常必要的。Kafka提供了一种无代理和可扩展的方式来展示数据给相关各方,并确保在节点丢失之前,相关数据被公开给正确的团队。这与最前沿的Web3物联网项目(如Helium)或更简单的封闭分布式账本(DLT)(如R3 Corda)有关。
我最近发表了一篇关于活动流媒体和Kafka改变零售元世界的实时商业的文章,展示了零售和游戏行业是如何连接虚拟和实体事物的。零售业务流程和客户沟通是实时发生的; 无论你是想卖衣服、智能手机还是为你的收藏品或视频游戏出售基于区块链的NFT代币。
?写在最后?
小结一下,Kafka不能:取代数据库或数据仓库,也不适用于完全实时性的安全关键性嵌入式业务、不稳定网络中数千个客户端的代理、API管理解决方案、物联网网关,也更不等同于区块链。
对于某些场景和需求,很容易将Kafka排除。
然而,几乎所有行业的分析和业务工作都使用Kafka。它是无处不在的事件流的事实标准。因此Kafka经常与其他技术结合使用。
译者介绍
吉锴,51CTO社区编辑,18年软件开发经验。现在阿里云全球培训中心任讲师,负责云计算,云原生,数字化转型等领域的课程设计,交付。先后于富士通,联想集团,欢聚时代,搜狗任职,手机YY首任架构师。2014年开始从事专业技术培训和顾问工作。
直播预告


关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 51CTO技术栈
51CTO技术栈
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675