【新智元导读】最近,由1000多位科学家组成的团队历时117天,搞出来了个超大的开源NLP模型。
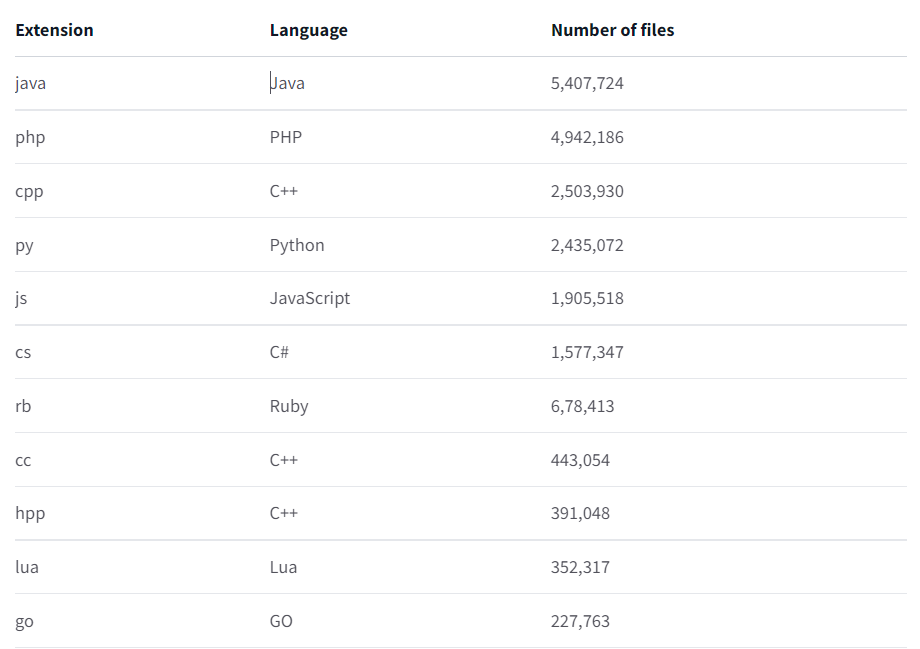
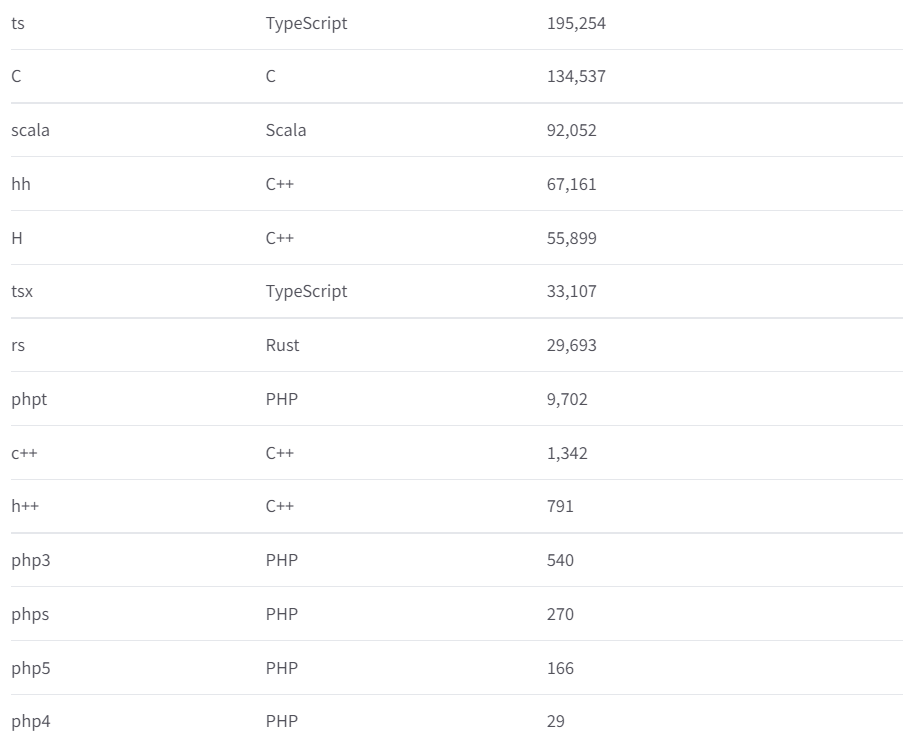
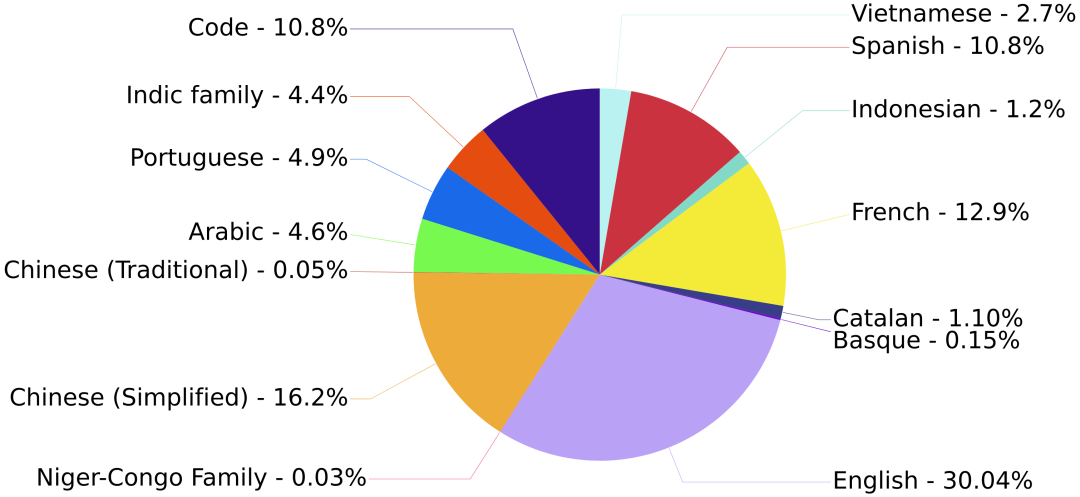
上半年,世界范围内1000多个科学家联合搞了个大团队。众所周知,自然语言处理这一块的模型和数据库一直都被科技大厂牢牢地掌握在手里。从某种程度上讲,这算是一种技术垄断。这1000个科学家,有搞伦理的,有搞法律的,甚至还有搞哲学的。当然,也不乏来自Meta和谷歌的员工,不过他们都是以个人身份参与进来的。他们的目的也很简单,就是要整一个真正像样的NLP模型——公平,公平,还是**的公平。新的NLP模型取名叫BOOM,啊不是,是BLOOM。估计是希望这个模型能像花一样蓬勃绽开吧。据统计,来自公共的资助就有价值700万美元的训练时间,也就是说,没有这些机构的帮助,这笔钱就得自己花,才能完成训练。顺利的话,BLOOM足以和谷歌、OpenAI这种大厂掰掰手腕。而且更关键的是,还是开源的。此外,BLOOM将会是同等规模的模型中,第一个多语言模型。如今,BLOOM在训练了117天后,终于完事儿了。毕竟说穿了它就是一种算法,模型会学习数十亿个单词和短语之间的统计学关联,然后执行各种任务,包括生成摘要、翻译、回答问题,以及对文本进行分类等等。尤其是,BLOOM在参数量上还没啥突破——为1760亿个参数。具体来说,BLOOM和GPT一样,使用的是decoder-only架构。甚至还是从英伟达的Megatron-LM和OpenAI的GPT2那儿改过来的。它拥有共70层,每层112个的注意力头(attention head),2048个token的序列长度,并采用了GeLU激活函数。同时,BLOOM还使用了13种编程语言,可以说主流的编程语言基本全用了。数据集方面,BLOOM算得上是多语言模型——其中包括了46种语言。数据集的容量达到了3416亿个token,相当于1.5TB的文本数据。硬件方面,384个A100 GPU用于训练,每一个都有80GB的内存。而一份模型需要48个GPU,每个GPU有60GB的内存。训练的吞吐量大约为150TFLOPs。团队预估的训练时间差不多是3~4个月,误差取决于训练过程中吞吐量的变化,以及可能出现的意外。今年的3月14日,BLOOM正式开始训练,用的是法国的巴黎郊外设立的Jean Zay国家超算。(感谢法国研究机构CNRS和GENCI提供的价值约300万欧元的计算拨款。)经过几天的优化,团队很快就将训练速度提到了149-150 TFLOPs/GPU。有一个非常有意思的点,刚开始模型还在按部就班的训着,基本保持每天1%的速度,稳步前进。虽说这类模型有些时候让人很满意,比如说生成诗歌,或是正确回答一些琐碎的问题等等,但说到底这些模型并不真的理解语言。这正是NLP模型也会生成一堆垃圾出来的原因。更令人担忧的是,语言模型还有可能宣扬错误的价值观,比方说种族主义,或是性别歧视。究其原因就是模型并不理解语言,给它塞什么就学什么。Hugging Face的机器学习研究院Yacine Jernite表示,现在存在的大多数模型都是直接从网络上抓取语言,包括Reddit等网站。这群研究人员从500种来源中,人工挑选了341亿字的数据集的三分之二。其中包括Semantic Scholar,这是一个AI支持的学术出版物搜索引擎,其中就包括Nature等顶刊中的内容。换句话说,BLOOM模型的数据集基本是手搓出来的。其中,选取数据集的来源是开会讨论出来的,同时还参考了其它社区团体的建议,比如非洲NLP社区Masakhane,LatinX in AI和Machine Learning Tokyo。Jernite表示,我们想保证所有能应用这个模型的人,都能参与到数据集的选择当中。选取他们国家、他们语言中的内容。(然后引入了科学家自己的主观偏见)为此,BigScience团队使用多语言网络抓取的方式先把数据集的容量拉满,然后再对数据集的质量进行过滤,并对隐私政策进行了一些调整。该项目还减少了从色情网站中提取的内容量,这是为了避免最终模型会输出含有性别歧视的内容。同时Jernite也承认,BLOOM也不是说一点偏见就没有了。但是通过向它输入多文化和高质量的内容,BigScience团队还是想尽可能的改进现有的模型。最关键的是,正因为模型背后的代码和数据集是开源的,每个研究人员都可以进行尝试,了解哪些部分导致最终输出了负面的内容。这对未来的模型迭代很有好处。布朗大学的自然语言学习研究院Ellie Pavlick表示,对BLOOM的评估也将和此前的基准不同。除了将BLOOM与其它模型在回答问题的能力等方面作比较以外,研究人员还希望能考察更多的指标。例如,BLOOM对某些刻板印象的联想有多强,或者BLOOM对某种特定的语言有多么的偏向。Pavlick表示,因为现在BLOOM已经被训练成多语言模型了,那么它会对语言有更深的理解。这会帮助它对多样化任务的概括能力。同时,Leahy预测,鉴于语言数据集的规模不大,该模型在英语中的表现可能要比其它大模型略逊一点。但是,因为BLOOM在其它方面有别的优势,Leahy认为这应该能抹平这种差距。前提到的以往的NLP模型由大厂掌控,所以BigScience团队才琢磨着要做这么一件事。
其实NLP模型的训练过程可以说是大同小异,BLOOM之所以有它独特的意义,就是因为后续的开源环节。BLOOM团队表示,在训练完毕以后,所有相关研究人员都可以获得下载BLOOM的权限,不管是想用它做实验,或是为了别的目的用新的数据集给它做进一步的训练,都可以。但是,下载BLOOM,并且成功让它跑起来,对硬件能力提出了很高的要求。现在BLOOM只供一些大一点的研究团队使用,所以BigScience团队还没给小团队或是个人铺好路。以后,研发团队会发布小一点的、对硬件要求低一点的BLOOM版本。同时,还会开发一个分布式系统,能让各个实验室在各自的服务器上分享模型。此外,Hugging Face还会发布一个网页版应用,能让任何人都可以使用BLOOM,而无需下载。除了在AI领域的应用以外,Francesco de Toni还发现了在历史研究领域的应用。Toni来自西澳大学,这所大学坐落在澳大利亚珀斯。他是BigScience团队中的一名语言学家,领导BLOOM的一个小组。他们发现,BLOOM能够高效地从大量的历史资料中提取信息,而这是任何搜索引擎都做不到的。比方说,BLOOM可以从文艺复兴时期,商人之间往来的信件中提取所有的人名,或是出现的货物,以此来研究文艺复兴时期的历史。在发布BLOOM的同时,还发布了一份文件,描述了BLOOM的能力和一些局限性。在使用BLOOM之前,还需要签署一份会不断更新的法律许可,研究人员必须承诺不会把BLOOM用于恶意,或是不恰当的目的。比如生成假新闻。Giada Pistilli表示,该团队会一直监测模型的应用情况,并且会在必要的时候插手干预,调整许可证书和相关文件的内容。https://www.nature.com/articles/d41586-022-01705-zhttps://bigscience.notion.site/BLOOM-BigScience-176B-Model-ad073ca07cdf479398d5f95d88e218c4https://mobile.twitter.com/bigsciencellm

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/












 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





