
深度学习有多深

?深度学习概念?
深度学习(DL,Deep Learning)的概念最早由多伦多大学的G.E.Hinton等,于2006年提出,是基于样本数据通过一定的训练方法得到包含多个层级的深度网络结构的机器学习(ML, Machine Learning)过程。机器学习通常以使用决策树、推导逻辑规划、聚类、贝叶斯网络等传统算法对结构化的数据进行分析为基础,对真实世界中的事件做出决策和预测。深度学习被引入机器学习使其更接近于最初的目标—人工智能(AI, Artificial Intelligence),其动机在于建立模型模拟人类大脑的神经连接结构,通过组合低层特征形成更加抽象的高层表示、属性类别或特征,给出数据的分层特征表示;它从数据中提取知识来解决和分析问题时,使用人工神经网络算法,允许发现分层表示来扩展标准机器学习。这些分层表示能够解决更复杂的问题,并且以更高的精度、更少的观察和更简便的手动调谐,潜在地解决其他问题。传统的神经网络随机初始化网络权值,很容易导致网络收敛到局部最小值。为解决这一问题,Hinton提出使用无监督预训练方法优化网络初始权值,再进行权值微调,拉开了深度学习的序幕。深度学习所得到的深度网络结构包含大量的单一元素(神经元),每个神经元与大量其他神经元相连接,神经元间的连接强度(权值)在学习过程中修改并决定网络的功能。通过深度学习得到的深度网络结构符合神经网络的特征,因此深度网络就是深层次的神经网络,即深度神经网络(deep neural networks,DNN)。深度神经网络是由多个单层非线性网络叠加而成的,常见的单层网络按照编码解码情况分为3类:只包含编码器部分、只包含解码器部分、既有编码器部分也有解码器部分。编码器提供从输入到隐含特征空间的自底向上的映射,解码器以重建结果尽可能接近原始输入为目标将隐含特征映射到输入空间。深度神经网络分为以下3类。
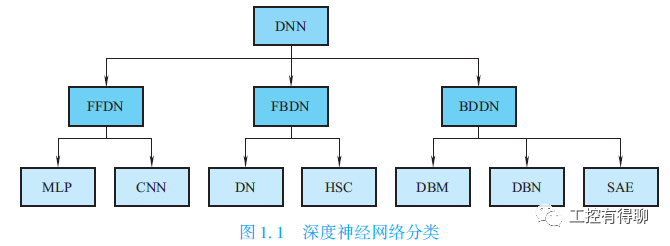
(1) 前馈深度网络(feed-forward deep networks,FFDN),由多个编码器层叠加而成,如多层感知机(multi-layer perceptrons,MLP) 、卷积神经网络(convolutional neural networks,CNN) 等。
(2) 反馈深度网络(feed-back deep networks,FBDN),由多个解码器层叠加而成,如反卷积网络(deconvolutional networks,DN)、层次稀疏编码网络(hierarchical sparse coding,HSC)等。
(3) 双向深度网络( bi-directional deep networks,BDDN),通过叠加多个编码器层和解码器层构成(每层可能是单独的编码过程或解码过程,也可能既包含编码过程也包含解码过程) ,如深度玻尔兹曼机(Deep Boltzmann Machines,DBM)、深度信念网络(deep belief networks,DBN)、栈式自编码器(stacked auto-encoders,SAE)等。
?深度学习发展?
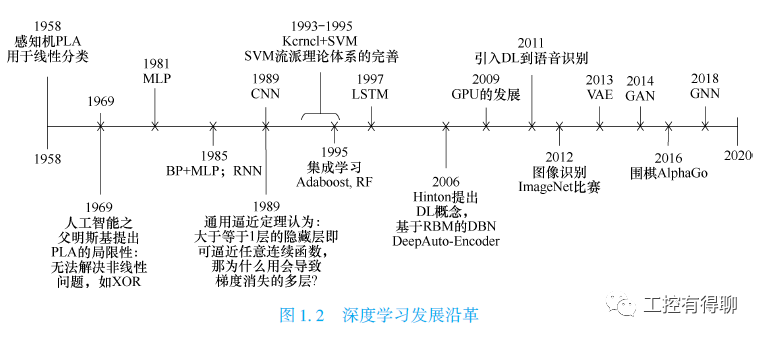
1. 深度学习发展沿革
深度学习是神经网络发展到一定时期的产物。最早的神经网络模型可以追溯到1943年McCulloch等提出的McCulloch-Pitts计算结构,简称MP模型,它大致模拟了人类神经元的工作原理,但需要手动设置权重,十分不便。
1958年,Rosenblatt提出了感知机模型(perceptron)。与MP模型相比,感知机模型能更自动合理地设置权重,但1969年Minsky和Paper证明了感知机模型只能解决线性可分问题,并且否定了多层神经网络训练的可能性,甚至提出了“基于感知机的研究终会失败”的观点,此后十多年的时间内,神经网络领域的研究基本处于停滞状态。
1986年,欣顿(Geoffery Hinton)和罗姆哈特(David Rumelhart)等提出的反向传播(Back Propagation,BP)算法,解决了两层神经网络所需要的复杂计算量问题,大大减少了原来预计的计算量,这不仅有力回击了Minsky等人的观点,更引领了神经网络研究的第二次高潮。随着20世纪80年代末到90年代初共享存储器方式的大规模并行计算机的出现,计算处理能力大大提升,深度学习有了较快的发展。
1989年,Yann LeCun等提出的卷积神经网络是一种包含卷积层的深度神经网络模型,较早尝试深度学习对图像的处理。2012年,Hinton构建深度神经网络,并应用于ImageNet上,取得了质的提升和突破,同年,人们逐渐熟悉谷歌大脑(Google Brain)团队。2013年,欧洲委员会发起模仿人脑的超级计算机项目,百度宣布成立深度学习机构。2014年,深度学习模型Top-5在ImageNet2014计算机识别竞赛上拔得头筹,腾讯和京东也同时分别成立了自己的深度学习研究室。
2015年至2017年初,谷歌公司的人工智能团队DeepMind所创造的阿尔法狗(AlphaGo)相继战胜了人类职业围棋选手,这只“狗”引起世界的关注,人类围棋大师们陷入沉思。这一切都显著地表明了一个事实:深度学习正在有条不紊地发展着,其影响力不断扩大。深度学习发展沿革,如图1.2所示。
机器学习和深度学习之间的关系是包含与被包含的关系,如图1.3所示。

2. 深度学习的局限瓶颈
深度神经网络(DNN)是一个强大的框架,可应用于各种业务问题。当前,深度学习仍有一定的局限。
第一,深度学习技术具有启发式特征。深度学习能否解决一个给定的问题还暂无定论,因为目前还没有数学理论可以表明一个“足够好”的深度学习解决方案是存在的。该技术是启发式的,工作即代表有效。
第二,深度学习技术具有不可预期性。深度学习涉及的诸多隐含层,属“黑箱模型”,会破坏合规性,对白箱模型形成挑战。
第三,深度学习系统化具有不成熟性。目前,没有适合所有行业或企业需要的通用深度学习网络,各行业或企业需要混合和匹配可用工具创建自己的解决方案,并与更新迭代的软件相互兼容。
第四,部分错误的结果造成不良影响。目前,深度学习不能以100%精度解决问题。深度学习延续了较浅层机器学习的大多数风险和陷阱。
第五,深度学习的学习速度不如人意。深度学习系统需要进行大量训练才有可能成功。
尽管深度学习在图像识别、语音识别等领域都得到落地和应用,涌现出了依图、商汤、寒武纪等人工智能企业,但是深度学习依旧存在困扰产学研的瓶颈。
第一,数据瓶颈。几乎所有的深度神经网络都需要大量数据作为训练样本,如果无法获取大量的标注数据,深度学习无法展开。虽然谷歌等互联网巨头开始研发人造数据技术,但是真正的效果还有待评估。
第二,认知瓶颈。这是由深度学习的特性决定。深度学习对感知型任务支持较好,而对认知型任务支持的层次较低,无法形成理解、直觉、顿悟和自我意识的能力。科学家推断,可能是这一切源于人类知识认识的局限,而深度学习在某些方面已经超越了人类的认知能力和认知范围。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 51CTO技术栈
51CTO技术栈
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675