近年来,基础模型(foundation models,也被称为预训练模型)的研究从技术层面逐渐趋向于大一统(the big convergence),不同人工智能领域(例如自然语言处理、计算机视觉、语音处理、多模态等)的基础模型从技术上都依赖三个方面:一是 Transformers 成为不同领域和问题的通用神经网络架构和建模方式,二是生成式预训练(generative pre-training)成为最重要的自监督学习方法和训练目标,三是数据和模型参数的规模化(scaling up)进一步释放基础模型的潜力。技术和模型的统一将会使得 AI 模型逐步标准化、规模化,从而为大范围产业化提供基础和可能。通过云部署和云端协作,AI 将有可能真正成为像水和电一样的“新基建”赋能各行各业,并进一步催生颠覆性的应用场景和商业模式。近期,微软亚洲研究院联合微软图灵团队推出了最新升级的 BEiT-3 预训练模型,在广泛的视觉及视觉-语言任务上,包括目标检测(COCO)、实例分割(COCO)、语义分割(ADE20K)、图像分类(ImageNet)、视觉推理(NLVR2)、视觉问答(VQAv2)、图片描述生成(COCO)和跨模态检索(Flickr30K,COCO)等,实现了 SOTA 的迁移性能。BEiT-3 创新的设计和出色的表现为多模态研究打开了新思路,也预示着 AI 大一统渐露曙光。(点击阅读原文,查看 BEiT-3 论文)图1:截至2022年8月,BEiT-3 在广泛的视觉及视觉-语言任务上都实现了 SOTA 的迁移性能
事实上,在早期对于 AI 和深度学习算法的探索中,科研人员都是专注于研究单模态模型,并利用单一模态数据来训练模型。例如,基于文本数据训练自然语言处理(NLP)模型,基于图像数据训练计算机视觉 (CV) 模型,使用音频数据训练语音模型等等。然而,在现实世界中,文本、图像、语音、视频等形式很多情况下都不是独立存在的,而是以更复杂的方式融合呈现,因此在人工智能的探索中,跨模态、多模态也成了近几年业界研究的重点。“近年来,语言、视觉和多模态等领域的预训练开始呈现大一统(big convergence)趋势。通过对大量数据的大规模预训练,我们可以更轻松地将模型迁移到多种下游任务上。这种预训练一个通用基础模型来处理多种下游任务的模式已经吸引了越来越多科研人员的关注,”微软亚洲研究院自然语言计算组主管研究员董力表示。微软亚洲研究院看到,大一统的趋势已经在三个方面逐渐显现,分别是骨干网络(backbone)、预训练任务和规模提升。首先,骨干网络逐渐统一。模型架构的统一,为预训练的大一统提供了基础。在这个思想指引下,微软亚洲研究院提出了一个统一的骨干网络 Multiway Transformer,可以同时编码多种模态。此外,通过模块化的设计,统一架构可以用于不同的视觉及视觉-语言下游任务。受到 UniLM(统一预训练语言模型)的启发,理解和生成任务也可以进行统一建模。其次,基于掩码数据建模(masked data modeling)的预训练已成功应用于多种模态,如文本和图像。微软亚洲研究院的研究员们将图像看作一种语言,实现了以相同的方式处理文本和图像两种模态任务的目的。自此,图像-文本对可以被用作“平行句子”来学习模态之间的对齐。通过数据的归一化处理,还可以利用生成式预训练来统一地进行大规模表示学习。BEiT-3 在视觉、视觉-语言任务上达到 SOTA 性能也证明了生成式预训练的优越性。第三,扩大模型规模和数据大小可提高基础模型的泛化能力,从而提升模型的下游迁移能力。遵循这一理念,科研人员逐渐将模型规模扩大到了数十亿个参数,例如在 NLP 领域,Megatron-Turing NLG 模型有5300亿参数,这些大模型在语言理解、语言生成等任务上都取得了更好的成效;在 CV 领域,Swin?Transformer v2.0具有30亿参数,并在多个基准上刷新了纪录,证明了视觉大模型在广泛视觉任务中的优势。再加之,微软亚洲研究院提出了将图像视为一种语言的方式,可直接复用已有的大规模语言模型的预训练方法,从而更有利于视觉基础模型的扩大。BEiT:微软亚洲研究院为视觉基础大模型开创新方向
在 CV 领域的模型学习中,通常使用的是有监督预训练,利用有标注的数据。但随着视觉模型的不断扩大,标注数据难以满足模型需求,当模型达到一定规模时,即使模型再扩大,也无法得到更好的结果,这就是所谓的数据饥饿(data hungry) 。因此,科研人员开始使用无标注数据进行自监督学习,以此预训练大模型参数。以往在 CV 领域,无标注数据的自监督学习常采用对比学习。但对比学习存在一个问题,就是对图像干扰操作过于依赖。当噪声太简单时,模型学习不到有用的知识;而对图像改变过大,甚至面目全非时,模型无法进行有效学习。所以对比学习很难把握这之间的平衡,且需要大批量训练,对显存和工程实现要求很高。对此,微软亚洲研究院自然语言计算组的研究员们提出了掩码图像建模 (Masked Image Modeling, MIM)预训练任务,推出了 BEiT 模型。与文本不同,图像是连续信号,那要如何实现掩码训练呢?
为了解决这一问题,研究员们将图片转化成了两种表示视图。一是,通过编码学习 Tokenizer,将图像变成离散的视觉符号(visual token),类似文本;二是,将图像切成多个小“像素块”(patch),每个像素块相当于一个字符。这样,在用 BEiT 预训练时,模型可以随机遮盖图像的部分像素块,并将其替换为特殊的掩码符号[M],然后在骨干网络 ViT 中不断学习、预测实际图片的样子。在 BEiT 预训练后,通过在预训练编码上添加任务层,就可以直接微调下游任务的模型参数。在图像分类和语义分割方面的实验结果表明,与以前的预训练方法相比,BEiT模型获得了更出色的结果。同时,BEiT 对超大模型(如1B或10B)也更有帮助,特别是当标记数据不足以对大模型进行有监督预训练时。BEiT相关论文被 ICLR 2022 大会接收为 Oral Presentation(口头报告论文,54 out of 3391)。ICLR 大会评审委员会认为,BEiT 为视觉大模型预训练的研究开创了一个全新的方向,首次将掩码预训练应用在了 CV 领域非常具有创新性。(了解更多详情,请查看BEiT论文原文:https://openreview.net/forum?id=p-BhZSz59o4)
BEiT-3为 AI 多模态基础大模型研究打开新思路
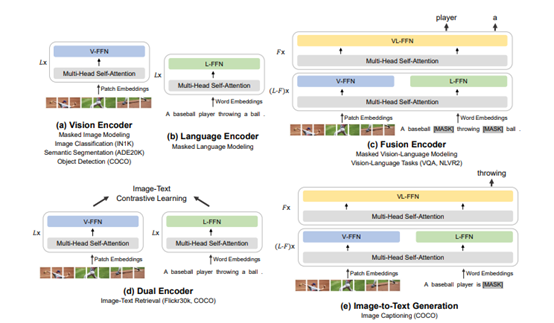
在 BEiT 的基础上,微软亚洲研究院的研究员们在 BEiT-2 中进一步丰富了自监督学习的语义信息(了解更多信息,请查看 BEiT-2 论文原文:https://arxiv.org/abs/2208.06366)。近日,研究员们又将其升级到了 BEiT-3。BEiT-3 利用一个共享的 Multiway Transformer 结构,通过在单模态和多模态数据上进行掩码数据建模完成预训练,并可迁移到各种视觉、视觉-语言的下游任务中。骨干网络:Multiway Transformer。研究员们将 Multiway Transformer 作为骨干网络以对不同模态进行编码。每个 Multiway Transformer 由一个共享的自注意力模块(self-attention)和多个模态专家(modality experts)组成,每个模态专家都是一个前馈神经网络(feed-forward network)。共享自注意力模块可以有效学习不同模态信息的对齐,并对不同模态信息深度融合编码使其更好地应用在多模态理解任务上。根据当前输入的模态类别,Multiway Transformer 会选择不同模态专家对其进行编码以学习更多模态特定的信息。每层 Multiway Transformer 包含一个视觉专家和一个语言专家,而前三层 Multiway Transformer 拥有为融合编码器设计的视觉-语言专家。针对不同模态统一的骨干网络使得 BEiT-3 能够广泛地支持各种下游任务。如图4所示,BEiT-3 可以用作各种视觉任务的骨干网络,包括图像分类、目标检测、实例分割和语义分割,还可以微调为双编码器用于图像文本检索,以及用于多模态理解和生成任务的融合编码器。图5:BEiT-3 可迁移到各种视觉、视觉-语言的下游任务预训练任务:掩码数据建模 (masked data modeling)。研究员们在单模态(即图像与文本)和多模态数据(即图像-文本对)上通过统一的掩码-预测任务进行 BEiT-3 预训练。预训练期间,会随机掩盖一定百分比的文本字符或像素块,模型通过被训练恢复掩盖的文本字符或其视觉符号,来学习不同模态的表示及不同模态间的对齐。不同于之前的视觉-语言模型通常采用多个预训练任务,BEiT-3 仅使用一个统一的预训练任务,这对于更大模型的训练更加友好。由于使用生成式任务进行预训练,BEiT-3 相对于基于对比学习的模型也不需要大批量训练,从而缓解了 GPU 显存占用过大等问题。扩大模型规模:BEiT-3 由40层 Multiway Transformer 组成,模型共包含19亿个参数。在预训练数据上,BEiT-3 基于多个单模态和多模态数据进行预训练,多模态数据从五个公开数据集中收集了大约1,500万图像和2,100万图像-文本对;单模态数据使用了1,400万图像和160GB文本语料。“BEiT 系列研究有一个一以贯之的思想和原则,就是我们认为从通用技术层面看图像也可视为一种‘语言’(Imglish),从而可以以统一的方式对图像、文本和图像-文本对进行建模和学习。如果说 BEiT 引领和推进了生成式自监督预训练从 NLP 到 CV 的统一,那么,BEiT-3 实现了生成式多模态预训练的统一,”微软亚洲研究院自然语言计算组首席研究员韦福如说。BEiT-3 使用 Multiway Transformer 有效建模不同的视觉、视觉-语言任务,并通过统一的 mask data modeling 作为预训练目标,这使得 BEiT-3 成为了通用基础模型的重要基石。“BEiT-3 既简单又有效,为多模态基础模型扩展打开了一个新方向。接下来,我们还将持续进行对 BEiT 的研究,以促进跨语言和跨模态的迁移,推动不同任务、语言和模态的大规模预训练甚至模型的大一统。”人的感知和智能天生就是多模态的,不会局限在文本或图像等单一的模态上。因此,多模态是未来一个重要的研究和应用方向。另外,由于大规模预训练模型的进展,AI 的研究呈现出大学科趋势,不同领域的范式、技术和模型也在趋近大一统。跨学科、跨领域的合作将更加容易和普遍,不同领域的研究进展也更容易相互推进,从而进一步促进人工智能领域的快速发展。
“尤其是通用基础模型和通才模型等领域的研究,将让 AI 研究迎来更加激动人心的机遇和发展。而技术和模型的统一会使得 AI 模型逐步标准化、规模化,进而为大范围产业化提供基础和可能。通过云部署和云端协作,AI 将有可能真正成为像水和电一样的‘新基建’赋能各行各业,并进一步催生颠覆性的应用场景和商业模式,” 韦福如表示。更多关于微软亚洲研究院在大规模预训练模型领域的研究,请访问:
https://github.com/microsoft/unilm
相关论文链接:
BEiT: BERT Pre-Training of Image Transformers
https://openreview.net/forum?id=p-BhZSz59o4
BEiT-2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
https://arxiv.org/abs/2208.06366
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks(BEiT-3)
https://arxiv.org/abs/2208.10442
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/














 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




