
一文读懂 BERT 源代码

大数据文摘授权转载自数据派THU
作者:陈之炎
BERT模型架构是一种基于多层双向变换器(Transformers)的编码器架构,在tensor2tensor库框架下发布。由于在实现过程当中采用了Transformers,BERT模型的实现几乎与Transformers一样。
BERT预训练模型没有采用传统的从左到右或从右到左的单向语言模型进行预训练,而是采用从左到右和从右到左的双向语言模型进行预训练,本文对BERT模型预训练任务的源代码进行了详细解读,在Eclipse开发环境里,对BERT 源代码的各实现步骤分步解析。
BERT 模型的代码量比较大,由于篇幅限制,不可能对每一行代码展开解释,在这里,解释一下其中每一个核心模块的功能。
1) 数据读取模块
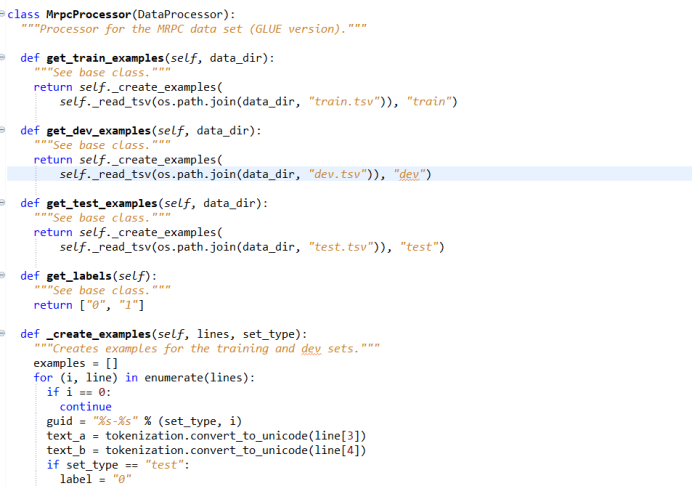
图 1
模型训练的第一步,是读取数据,将数据从数据集中读取进来,然后按照BERT 模型要求的数据格式,对数据进行处理,写出具体数据处理的类以及实际要用到的数据集中数据处理的方法,如果任务中用到的数据集不是MRPC ,这部分的代码需要依据特定的任务重新写一下如何操作数据集的代码,对于不同的任务,需要构造一个新的读取数据的类,把数据一行一行地读进来。
2) 数据预处理模块
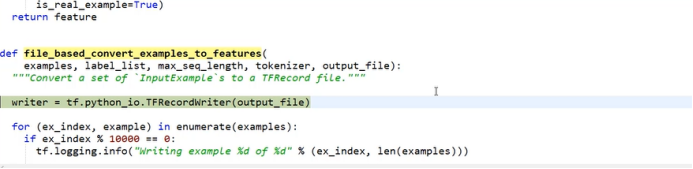
图 2
利用tensorflow 对数据进行预处理,由于用TF-Record 读数据的速度比较快,使用起来比较方便,在数据读取层面,需要将数据转换成TF-Record格式。首先,定义一个writer,利用writer函数将数据样本写入到TF-Record当中,这样一来,在实际训练过程中,不用每次都到原始数据中去读取数据,直接到TF-Record当中读取处理好的数据。
把每一个数据样本都转化成一个TF-Record格式的具体做法如下:首先,构建一个标签,接下来对数据做一个判断,判断数据中由几句话组成,拿到当前第一句话后,做一个分词操作。分词方法为wordpiece 方法。在英文文本中,由字母组成单词,词与词之间利用空格来切分单词,利用空格切分单词往往还不充分,需要对单词做进一步切分转换,在BERT 模型中,通过调用wordpiece 方法将输入的单词再进一步切分,利用wordpiece的贪心匹配方法,将输入单词进一步切分成词片,从而使得单词表达的含义更加丰富。在这里,利用wordpiece 方法将读入的单词进行再次切分,把输入的单词序列切分成更为基本的单元,从而更加便于模型学习。
在中文系统中,通常把句子切分成单个的字,切分完成之后,把输入用wordpiece转化成wordpiece结构之后,再做一个判断,看是否有第二句话输入,如果有第二句话输入,则用wordpiece对第二句话做相同的处理。做完wordpiece转换之后,再做一个判断,判断实际句子的长度是否超过max_seq_length 的值,如果输入句子的长度超过max_seq_length规定的数值,则需要进行截断操作。
3) tf-record 制作
对输入句对进行编码,遍历wordpiece结构的每一个单词以及每一个单词的type_id ,加入句子分隔符【CLS】、【SEP】,为所有结果添加编码信息;添加type_id,把所有单词映射成索引功,对输入词的ID (标识符)进行编码,以方便后续做词嵌入时候进行查找;
Mask编码:对于句子长度小于max_seq_length 的句子做一个补齐操作。在self_attention 的计算中,只考虑句子中实际有的单词,对输入序列做input_mask 操作,对于不足128个单词的位置加入额外的mask,目的是让self_attention知道,只对所有实际的单词做计算,在后续self_attention计算中,忽略input_mask=0 的单词,只有input_mask=1 的单词会实际参与到self_attention计算中。Mask编码为后续的微调操作做了初始化,实现了任务数据的预处理。
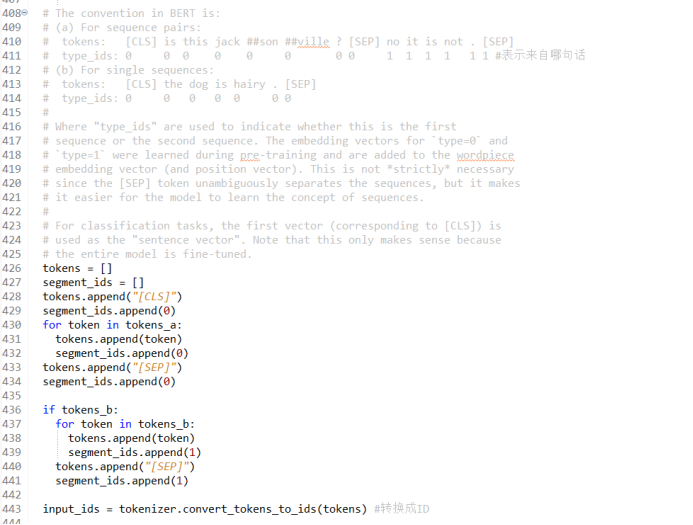
图 3
对input_Feature做初始化:构建 input_Feature并把结果返回给BERT。通过一个for 循环,遍历每一个样本,再对构造出来一些处理,把input_id、input_mask和segment_id均转换成为int类型,方便后续tf-record的制作。之所以要做数据类型的转换,是因为tensorflow 官方API要求这么做,tensorflow对tf-record的格式做了硬性的规定,用户无法自行对其修改。在后续具体项目任务中,在做tf-record时,只要把原始代码全部复制过去,按照原有的格式修改即可。构造好input_Feature之后,把它传递给tf_example,转换成tf_train_features ,之后,直接写入构建好的数据即可。
4) Embeding层的作用
在BERT 模型中有一个creat_model 函数,在creat_model 函数中一步一步把模型构建出来。首先,创建一个BERT 模型,该模型中包含了transformer的所有结构,具体操作过程如下:
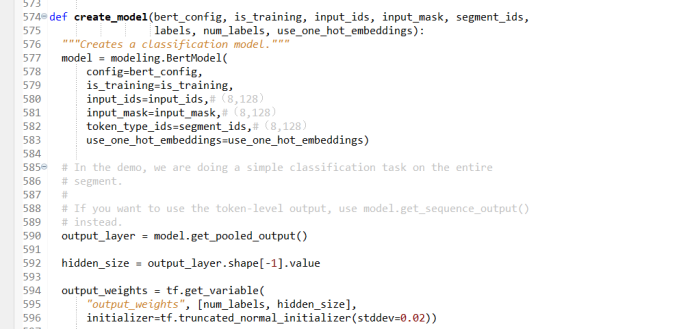
图 4
读入配置文件,判断是否需要进行训练,读入input_id、input_mask和segment_id等变量, one_hot_embedding变量?在利用TPU 训练时才使用,在用CPU 训练时不用考虑,默认值设为Faulse。
构建embedding层,即词嵌入,词嵌入操作将当前序列转化为向量。BERT 的embedding层不光要考虑输入的单词序列,还需要考虑其它的额外信息和位置信息。BERT 构建出来的词嵌入向量中包含以下三种信息:即输入单词序列信息、其它的额外信息和位置信息。为了实现向量间的计算,必须保持包含这三种信息的词向量的维数一致。
5) 加入额外编码特征
接下来,进入到embedding_lookup 层,这个层的输入是:input_id(输入标识符)、vocab_size(词汇表大小)、embedding_size(词嵌入的维度)、initializer_range(初始化的取值范围)。embedding_lookup的输出是一个实际的向量编码。

图 5
首先,获取embedding_table,然后到embedding_table里查找每个单词对应的词向量,并将最终结果返回给output,这样一来,输入的单词便成了词向量。但这个操作只是词嵌入的一部分,完整的词嵌入还应在词嵌入中添加其它额外的信息,即:embedding_post_processor。
embedding_post_processor是词嵌入操作必须添加进去的第二部分信息,embedding_post_processor的输入有:input_tensor、use_token_type、token_type_id、token_type_vocab_size,返回的特征向量将包含这些额外的信息,其维度和输入单词的词向量一致。
6) 加入位置编码特征
利用use_position_embedding 添加位置编码信息。BERT 的Self_attention 中需要加入位置编码信息,首先,利用full_position_embedding 初始化位置编码,把每个单词的位置编码向量与词嵌入向量相加,接着,根据当前的序列长度做一个计算,如果序列长度为128,则对这128个位置进行编码。由于位置编码仅包含位置信息,和句子的上下文语义无关,对于不同的输入序列来说,虽然输入序列的内容各不相同,但是它们的位置编码却是相同的,所以位置编码的结果向量和实际句子中传的什么词无关,无论传的数据内容是什么,它们的位置编码均是一样的。获得位置编码的输出结果之后,在原词嵌入输出向量的基础上,加上额外编码获得的特征向量和位置编码向量,将三个向量求和,返回求和结果,到此为止,完成了BERT模型的输入词嵌入,得到了一个包含位置信息的词向量,接下来,对这个向量进行深入的操作。

图 6
7) mask机制
在完成词嵌入之后,接下来便是Transformer结构了,在Transformer之前,先要对词向量做一些转换,即attention_mask ,创建一个mask矩阵:create_attention_mask_from_input_mask 。在前文提到的input_mask 中,只有mask=1 的词参与到attention的计算当中,现在需要把这个二维的mask转换成为一个三维的mask,表示词向量进入attention的时候,哪几个向量会参与到实际计算过程当中。即在计算attention时,对输入序列中128个单词的哪些个单词做attention计算,在这里,又额外地加入了一个mask处理操作。

图 7
?
完成mask处理之后,接下来是构建Transformer的Encode端,首先给Transformer传入一些参数,如:input_tensor、attention_mask、hiden_size、head_num等等。这些参数在预训练过程中已经设置好了,在进行微调操作时,均不得对这些参数随意更改。
在多头attention机制中,每个头生成一个特征向量,最终把各个头生成的向量拼接在一起得到输出的特征向量。
8) 构建QKV 矩阵
接下来,是attention机制的实现,BERT 的attention机制是一个多层的架构,在程序具体实现中,采用的是遍历的操作,通过遍历每一层,实现多层的堆叠。总共需要遍历12层,当前层的输入是前一层的输出。attention机制中,有输入两个向量:from-tensor和to_tensor,而BERT 的attention机制采用的是self_attention,此时:
from-tensor=to_tensor=layer_input;

图 8
在构建attention_layer过程中,需要构建K、Q、V 三个矩阵,K、Q、V矩阵是transformer中最为核心的部分。在构建K、Q、V矩阵时,会用到以下几个缩略字符:
B ?代表Batch Size ?即批大小 ?在这里的典型值设为 8;
F???代表 ?from-tensor??维度是128;
T???代表 to_tensor??维度是128;
N ? Number of Attention Head attention机制的头数(多头attention机制)在这里的典型值设为 12个头;
H ? Size_per_head 代表每个头中有多少个特征向量,在这里的典型值设为 64;
构建Query 矩阵:构建query_layer查询矩阵,查询矩阵由from-tensor构建而来,在多头attention机制中,有多少个attention头,便生成多少个Query 矩阵,每个头生成的Query 矩阵输出对应向量:
query_layer=【 B*F,N*H】, 即1024*768;

图 9
构建Key 矩阵: Key 矩阵由to-tensor构建而来, 在多头attention机制中,有多少个attention头,便生成多少个Key 矩阵,每个头生成的Key 矩阵输出对应向量:
key_layer=【 B*T,N*H】, 即1024*768;

图 10
构建Value矩阵: Value矩阵的构建和Key 矩阵的构建基本一样,只不过描述的层面不同而已:
value_layer=【 B*T,N*H】, 即1024*768;
构建QKV 矩阵完成之后,计算K矩阵和Q 矩阵的内积,之后进行一个Softmax操作。通过Value矩阵,帮助我们了解实际得到的特征是什么,Value矩阵和Key矩阵完全对应,维数一模一样。

图 11
9) 完成Transformer 模块构建
构建QKV 矩阵完成之后,接下来,需要计算K矩阵和Q 矩阵的内积,为了加速内积的计算,在这里做了一个transpose转换,目的是为了加速内积的计算,并不影响后续的操作。计算好K矩阵和Q 矩阵的内积之后,获得了attention的分值:attention_score,最后需要利用Softmax操作将得到的attention的分值转换成为一个概率:attention_prob。
在做Softmax操作之前,为了减少计算量,还需要加入attention_mask,将长度为128 的序列中不是实际有的单词屏蔽掉,不让它们参与到计算中来。在tensorflow中直接有现成的Softmax函数可以调用,把当前所有的attention分值往Softmax里一传,得到的结果便是一个概率值,这个概率值作为权重值,和Value矩阵结合在一起使用,即将attention_prob和Value矩阵进行乘法运算,便得到了上下文语义矩阵,即:
Context_layer=tf.matmul(attention_prob, value_layer);

图 12
得到当前层上下文语义矩阵输出之后,这个输出作为下一层的输入,参与到下一层attention的计算中去,多层attention通过一个for循环的多次迭代来实现,有多少层attention(在这里是12层)就进行多少层迭代计算。
10) 训练BERT 模型
做完self_attention之后,接下来是一个全连接层,在这里,需要把全连接层考虑进来,利用tf.layer.dese 实现一个全连接层,最后要做一个残差连接,注意:在全连接层的实现过程中,需要返回最终的结果,即将最后一层attention的输出结果返回给BERT ,这便是整个Transformer 的结构。
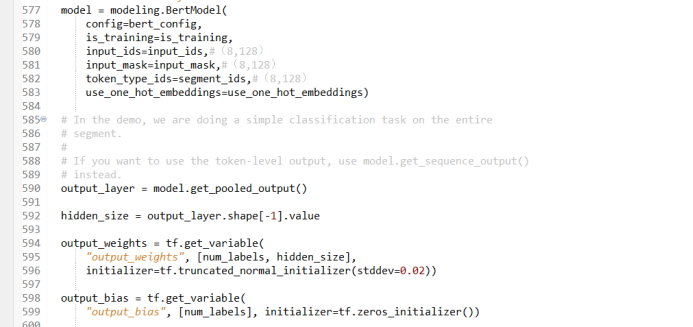
图 13
总结一下上述整个过程,即Transformer 的实现主要分为两大部分:第一部分是embedding 层,embedding 层将wordpiece词嵌入加上额外特定信息和位置编码信息,三者之和构成embedding 层的输出向量;第二部分是将embedding 层的输出向量送入transformer结构,通过构建K、Q、V三种矩阵过,利用Softmax函数,得到上下文语义矩阵C , 上下文语义矩阵C不仅包含了输入序列中各单词的编码特征,还包括了各单词的位置编码信息。
这就是BERT 模型的实现方式,理解了上述两大部分的详细过程,对BERT模型的理解便没有什么太大问题了。以上十大步骤基本涵盖了BERT 模型中的重要操作。
经过BERT 模型之后,最终获得的是一个特征向量,这个特征向量代表了最终结果。以上便是谷歌官方公布的开源MRPC 项目的全部过程。读者在构建自己特定任务的项目时候,需要修改的是如何将数据读入BERT 模型的部分代码,实现数据预处理。


关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

![玥儿玥er[XiuRen秀人网] 2024.11.22 NO.9488](https://imgs.knowsafe.com:8087/img/aideep/2025/1/4/d80b0beed65cb0ab0ba1b2fc4caae77b.jpg?w=250)




 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675