
傅盛的AI大课(2):大模型创新不是只能复刻OpenAI
在千家万户都在卷千亿大模型的彼时,只有做千亿大模型才是唯一路径吗?
2022年11月30日,ChatGPT 横空出世,李开复老师把ChatGPT的出现定义为AI2.0时代,这不是在原来的路线上长出来的,而是在AI技术树分支中爆发出来的。ChatGPT 也是 Think Different 的产物。

一、ChatGPT是一次生产力革命
它也是一次生产力革命,相信这已经是大家的共识。
人类历史上可能只有蒸汽机的出现叫做生产力革命,蒸汽机出现后,从热能向动能的转化范式发生了变化。在蒸汽机出现之前,全球人均的GDP和生产力水平,在两千多年的时间里从未提高过,一直在低水平上,蒸汽机出现之后,人类生产力大幅度提高,工业文明开始。
而ChatGPT由于具备语言理解,产生了人类独有的逻辑和推理能力。《人类简史》里说,之所以我们的祖先智人可以脱颖而出,就是因为讲八卦的能力,人类进化了虚拟事物的能力,而虚拟事物的本质就是逻辑,没看见的可以说出来,认为它存在,这就是一套逻辑系统,当这个逻辑系统被人类掌握后,人类才开始成为地球的主宰。
而ChatGPT由于理解逻辑和推理,使得今后电脑有可能实现从电能到智能的转换范式。以前我们要做一个智能系统要上很多人、很多设施,成本非常高,而且不是边际成本递减,但是ChatGPT出现后,有可能一台电脑就可以像人一样工作。
这一次的生产力变革,使得国家之间的智能竞争不再是人口和教育数字,而是人口+教育+算力的竞争,而每一家企业可能未来真正的智能水平也不只靠有经验的员工,而是靠有经验的人和很厉害的算力,这件事在硅谷已经出现了,有的企业已经会将一半的资金用在算力投资上。
今天这个时代,每个业务用大模型重做一遍,都能获得十倍增长。有些企业已经开始崛起:
第一,微软。今年老态龙钟的科技巨头微软完全焕发了新的活力,我们在年初还讨论过,微软有没有可能成为地球上第一个市值超过10万亿美金的公司,这是真的有可能。微软以前的Slogan是让每一个家庭都有一台电脑,现在就可以变成让每一个人都有很多AI助理,所以它整个的想象空间扩大了。
第二,Midjourney,现在年收入超过2亿美金。如果只把它看成是一个玩图的网站,那想象不到它的商业价值,但如果把它跟类似猪八戒网的网站对齐,它就是提供设计外包。以前企业要找无数的设计师满足对图片的需求,现在只要点几下,就可以获得需要的图片,所以它让生产力大幅度提升。
第三,创业公司HeyGen,它就做了一个应用,把一个人的演讲变成英语、日语,口形还能对准,现在年收入超过两千万美金,供不应求。如果把它看成以前的视频制作公司,帮你拍外语视频,它让生产力也是极大提高了。
第四,Pika也是最近硅谷很热的一家视频制作公司,只有4名员工,估值超2亿美金。

二、脱离市场的技术投入是资源浪费
面对这一次的AI大潮,每个人都跃跃欲试,但不知所措,总结起来就是两句话:
第一,这一波技术来得太猛。很多人问我,以后是不是不懂技术、不会编程就要被淘汰,我们完全不懂AI到底是什么。第二,变得太快了,刚学一些又有新的技术出现。
而我要说,这一波AI的到来绝对不是不懂技术的会被淘汰,而是给不懂技术的人一个非常强大的支撑。以后谁懂业务,谁懂计算机的行业规律,那谁就有可能被AI放大其能力,可能是十倍、百倍的放大。因为以前技术只属于程序员,但今天不再如此,技术被平权化,扩散到千千万万个普通人,使得我们可以跨越这条鸿沟。
所以我想说,万变不离其宗,所有的技术浪潮无论听起来有多神奇,都应该躬身入局,以终为始,找一条适合自己的路。
记得我跟李彦宏的一次对话,他说每个月认知都在迭代,一方面在学习新东西,一方面很焦虑。在2023年3月份,国内千亿大模型创业如火如荼,所有人都想要做中国的OpenAI。
当时我的团队也找到我说,“老板,再不动手训练大模型就落伍了,A100要大涨价了”,他们堵在门口不让我走,担心这一波过去再做就来不及了。当时我抑制住了激动的心情,说等我想想。当然在他们的“胁迫”下还是买了一些A100,做一些基础算力。因为从技术团队的角度上,训练千亿大模型是技术皇冠上的明珠,每个技术团队都有摘取的愿景,但那时候我想的问题是如何才能有独特的价值。

因为当时训练千亿大模型本质上是资本的投入,一次训练要耗费上千万美金,而且训练一次要用3-6个月的周期,就像孙悟空在炼丹炉里面,它不出来永远不知道是什么样子,可能要等3-6个月才能看到这个模型怎么样,不行就要再来一次。那么,做还是不做?
在千家万户都在卷千亿大模型的彼时,只有做千亿大模型才是唯一路径吗?到了4月份,我跟出门问问的李志飞聊,他说不要做,因为再过半年中国会有很多个千亿大模型,到时候会出现千亿大模型过剩,但却没有应用。
我想起当时第一波做AI1.0的时候,招了很多博士,做的很多技术都可以发论文,但我要坦诚的说,第一代机器人做得并不好。后来我才换了一条道路,机器人需要什么技术,就把那个AI技术打磨好,而不是先搞一堆技术放在那里。
况且,如果没有商业落地,那只是技术狂欢,脱离市场的技术投入,就是资源浪费。这个观念今天讲出来需要勇气,因为天天大家都在讲硬科技,但如果坦诚地看,在AI1.0时代,很多AI公司并没有真正实现闭环,或者实现的闭环并不够好,烧了很多钱并没有独到的东西,这是事实。
三、大模型创新的两种模式
我之所以没有走训练千亿级大模型的路子,是因为我在思考,不断的拼资本、算力,拼到最后能用起来吗?
这里我总结了两套大模型创新的模式。去年三四月份的时候,大家都觉得不做这个千亿大模型上不了牌桌,做完了再去看哪里能用。而我想这次要慢慢来,这次科技浪潮不是一年的事,甚至不是十年的事,我们要先从应用出发,挖掘应用场景,寻找垂直模型,到真正准备好了,我们再开始训练,我相信这么一个大赛道下我们有的是机会。

我发现ChatGPT有用以后,就在公司说,所有的部门都要参与到这次的AI变革当中,全员AI。通过搞内部创新的方式,涌现出一些特别惊人的例子。我们公司CFO的助理,从没学过编程,用了ChatGPT以后,一言不合就开始写程序,震惊了所有的程序员。
下面这张图也是她画的,她想表达的意思是,在垂直技术领域,AI可能带来生产力的跃迁,一个人可以通过AI赋能,从一个领域的非专业人员快速达到中等专业水平,未来的很多岗位限制都会因为初阶技能的消失而打通。

所以今天OpenAI是一个技术浪潮,但不是让懂技术的人更牛,而是不懂技术的人能够跨越技术的鸿沟。
通过近一年的实践我们发现,大模型在企业增效中非常明显,但是只靠员工自我驱动难以落实,一定要一把手亲自抓,而且要深度结合企业流程进行AI重构。我们公司内部已经开始组织部门进行调整,成立了AI生产力部门,把过去散落在各地的中台部门全部统一到这个部门里,并直接向我汇报。
总结起来就是,AI前景肯定很大,但现在还处于早期,大模型落地需要强应用。不把针对企业流程的应用做好,接入一个API就能够让企业增长20%的效率是不可能的。只有进行流程重构,做好应用才有可能。
可能也有很多人知道,我吵架经常会上微博热搜。有一次,朱啸虎说,“AI大模型对创业者不友好,99%的能力都是被大模型覆盖的,你们的创业公司有什么价值?”我就很生气,怼了一下说,“做好应用,依然是创业者最好的机会!”很多人以为我是一时兴起,但是事实上不是的,因为在这之前我们实践了太多,一个基本问答问题让大模型做好都要做非常大的努力,需要做很多的套件才能真正实践起来。
四、企业应用,百亿参数就够了
我们从去年三四月份就和客户一起成长,在2023年5月,有客户说能不能帮我私有化部署大模型。但是当时一个千亿参数大模型一年私有化授权费用是几千万,到今天应该还是,然后你要把他私有化部署以后,你买服务器的费用最低成本160万(当时的价格)。我们客户说,我们其实就想做一个客服,AI大模型被讲的那么牛,我一年投个几千万难以承受,再高深的技术最后也得算账,我不能因为有这个技术就用,用了以后比我现在的成本高几十倍,有没有更便宜又不损失性能的方案?
这个时候行业又发生了变化,LLaMA来了。LLaMA在行业内有一个绰号叫做“奶妈”,因为它滋养了很多大模型公司,使得大模型的算法壁垒快速消失。开源社区本来就是人类文明的一部分,我们可以看到这棵科技树在OpenAI的旁边又长出了一个分支。
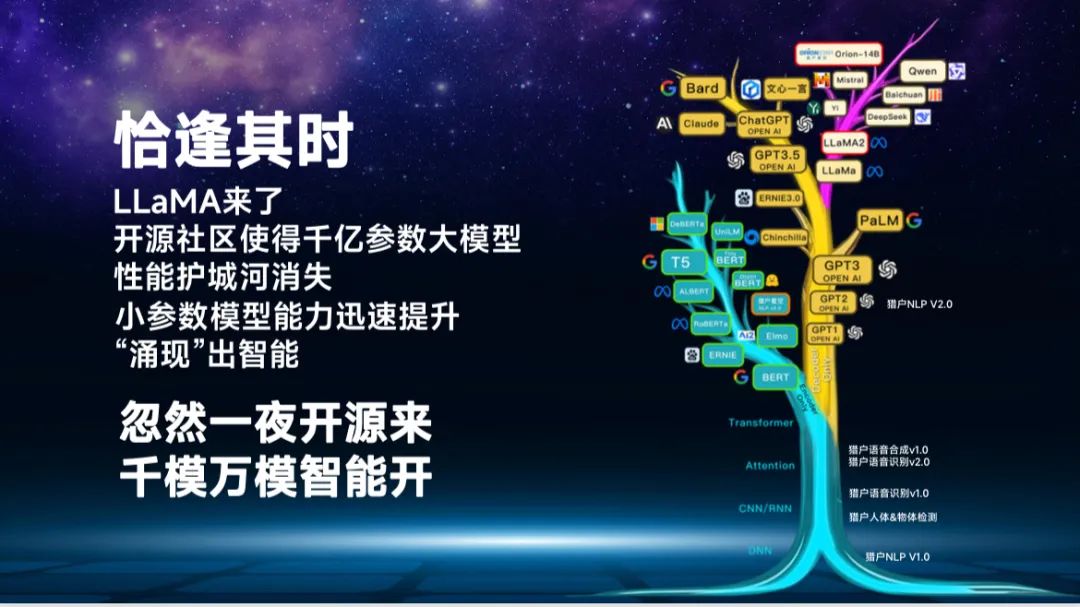
有人说OpenAI都在搞几千万卡的并联了,但是有一帮科学家、从业者、技术极客说千亿参数可以涌现智能,百亿参数可不可以呢?百亿参数的智能在有一些情况可不可用呢?所以在LLaMA出现以后,整个开源社区开始百花齐放,小参数模型的性能快速崛起。
我们可以看到在有一些评测上,百亿参数在某一些能力上已经接近了GPT,我觉得这就是这个行业每天都在日新月异的发展给我们带来的机会。我们突然发现也许千亿参数不是唯一的选择,这个分支带来了AI大模型的二元对立时代。

我当时在一个演讲中说,有经济实力的公司全在卷算力,他们的梦想是造出一个爱因斯坦。同时还有一帮开源社区的极客爱好者,用更小的资源、更精巧的算法去实现智能,看谁能造出平民化大模型,每个人都可以随便用,而不是一上来就要几千万门槛的大模型。当然,由此我们也能看到,所有的技术并不是在一个树上从头长到尾,而是会不断涌现出新的分支,可能有一天一个分支就会变成主流。
在我们自己的实践中,就给客户做调试,后来发现用百亿参数的模型,加上客户自己的私有数据,再加应用的打磨,效果是可以约等于甚至大于千亿参数大模型。
虽然千亿参数大模型必然全面性更好,比如让它做一道奥数题,回答法律知识,它的面会很宽,但是在企业场景当中并不需要做奥数题,只要在一个专业点上做好就可以了。所以不同专业的应用领域,用一个百亿参数把数据打磨好,把应用做好,它就可以满足需求,而且更具性价比。

一个非常真实的案例。今年四五月份的时候,我们用千亿大模型没有做深入调试,结果只有60%的准确率,相信很多从业者一定也会有这样的体验,听起来很好,但用的时候有很多问题。我们用了6个月的时间,与前面提到的那个客户一点点打磨,做到了97%的准确率,基本上完成对这个场景的增强。
所以我们想说,我们自己也在实践,企业应用百亿参数就够了。
小结:技术不是为工程师而生,而是为应用而生
纸上得来终觉浅,绝知此事要躬行。只看朋友圈就觉得AI要吞噬人类,未来全人类只需要一家公司就是OpenAI,但事实上你真正动手做时就发现太多细节是可以做的,魔鬼都在细节里,如果只要一个底层技术很牛就能做出一切,芯片公司将来会统领所有行业。但是并不是这样的,底层技术有底层技术的价值,应用有应用的价值。
我想引用乔布斯的一句话:技术不是为工程师而生,而是为应用而生。
在这波大模型的技术浪潮中,最笃定的其实是微软,它投资了OpenAI,将AI融入应用,把原来的Windows、Office加入Copilot,一个消息接着一个消息往外放,股价不断上涨。在我看来,这就是Think Different ,不是只有跟随 OpenAI 才能成功。
猎户星空大模型开源地址 :
https://github.com/OrionStarAI/Orion
https://huggingface.co/OrionStarAI
扫描下方二维码,关注傅盛视频号,观看直播回放,了解详情

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 傅盛
傅盛
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675