
田奇:行人再识别的挑战和最新进展
2018 年 9 月 18 日,2018 世界人工智能大会·视觉智能 瞳鉴未来七牛云专场分论坛在上海国际会议中心 5 楼欧洲厅举行。华为诺亚方舟实验室计算视觉首席科学家、美国德克萨斯大学圣安东尼奥分校计算机系教授田奇,在会上为大家带来了题为《行人再识别的挑战和最新进展》的分享。
以下内容根据现场演讲内容速记的实录整理。

各位嘉宾,各位老师,各位同学,非常荣幸在这里和大家分享我们的工作。本次我报告的主题是《行人再识别的挑战和最新进展》。在今天的报告中,我将首先介绍一下行人再识别的背景和面临的挑战,接着介绍学术界近年取得的最新进展以及我们相关的工作,最后与大家分享行人再识别领域未来可能出现的新的研究方向。
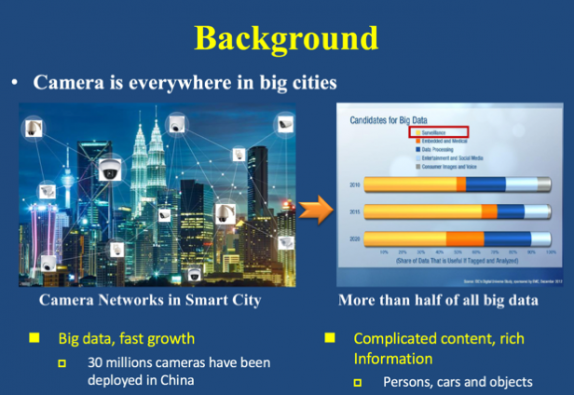
大城市中的摄像头是无处不在的,每天都会产生海量的监控视频数据。如何从海量数据中挖掘有效信息,这是我们所关心的。我们虽然拥有大数据,但是如果机器没有自动分析和处理能力,那么大数据并不意味着我们能获得海量信息。同样,如果机器没有学习和归纳能力,拥有了海量信息也并不代表我们掌握丰富知识。譬如,2013 年的波士顿马拉松恐怖袭击事件以及 2017 年拉斯维加斯恐怖袭击事件等,我们的摄像头都能捕捉到这些镜头,但是数据中心并不完全具备对海量数据分析、处理和预警的能力,因此没有避免悲剧发生。由此可见,提升机器对监控视频数据的分析、处理、学习和归纳能力是极其重要的。在监控视频中,人和车是我们最为关心的。目前,我的团队主要聚焦于分析人,尤其是行人再识别领域的研究。
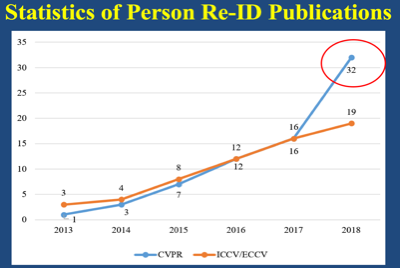
行人再识别具有广阔的应用前景,包括行人检索、行人跟踪、街头事件检测,行人动作行为分析等等。当然这个动作行为分析也包括用户在商场中的购物行为分析,比如估计顾客的年龄、性别、对什么样的商品感兴趣、停留的时间等等。这些信息有助于商场去策划相应的销售策略。由于行人再识别任务的重要性,近些年越来越多的研究人员和机构都投入进来,从计算机视觉顶会的论文发表情况就可以看出来这一趋势。例如在 2013 年,相关的文章在视觉顶会上发表的并不多,但是近年快速上升,在今年的计算机视觉顶级会议 CVPR 上,就有 32 篇文章发表,在 ECCV 上有 19 篇文章发表。

我们对行人再识别发展历程做了一个总结。简单来说,行人再识别的发展分为两个大阶段:一个是 2014 年以前,主要依靠一些传统方法,例如设计手工特征等。2014 年以后的工作基本上都是基于深度学习的。在深度学习的框架下又有一些细分工作,比如说这两年因为深度模型需要大量的训练数据,在训练数据不足的情况下,基于生成对抗网络的数据生成方法成为了比较热门的研究方向。
行人再识别是一个较难的课题,解决这一课题面临着诸多挑战。这些挑战可以归纳为三种:第一个挑战是对大量训练数据的需求;第二个挑战是行人视觉表观差异性大;第三个挑战是非理想的场景。
对大量训练数据需求的挑战主要体现在以下这些方面:
一是有限的训练数据。从当前行人再识别训练数据的收集情况来看,收集到的数据相对于真实数据的时空分布是非常有限的、局部的。同时,与其他视觉任务相比,行人再识别的数据规模也是非常小的。比如以大规模图像识别数据集 ImageNet 来说,它的训练数据有 125 万张图片,在行人检测数据集 Caltech 上标注的行人框有 35 万个,cCOCOoco 的目标检测数据训练集是 12.3 万多张图片。而我们行人再识别当前常用的数据集仅有 3 万多张行人图片。
二是训练、数据获取比较困难。我们很难去收集到跨时间、跨气候和多场景的行人数据。另外,隐私问题也对数据获取造成了阻碍。
三是数据标注比较困难。首先是浩大的标注工作量,大家知道大规模图像分类数据集 ImageNet ,通过众包的形式前后有 4.8 万人花了近两年时间来标注。 无论从时间还是金钱上来看,标注成本都是非常大的。其次,标注本身有时也是非常困难的,比如简单把狗和猫分开比较容易,但是在视频中把两个年龄、体貌相似,穿着同样衣服的不同行人分开是比较困难的。
第二个行人视觉表观差异变化大的挑战,主要是行人呈现不同的姿态,含有复杂的背景,不同的光照条件以及不同的拍摄视角,这些都会给行人再识别带来很大的困扰。而且一个行人穿不同的衣服,戴不同的帽子或者眼镜,留不同的发型也都会带来巨大问题。

第三个主要挑战是非理想的场景,主要是行人不对齐、部分遮挡、图像质量低等问题。

行人再识别近年的进展也主要是围绕着如何解决好以上这三大挑战来展开的。
数据是解决问题的关键。我们团队一开始就致力于构建标准数据集,以推动行人再识别的发展。我们在 ICCV2015 发布了当时规模最大的基于图像的行人再识别数据集 Market-1501。这个数据集有六个摄像头,标注了 1501 个行人,共 3 万多张行人图片。该数据集目前已经成为行人再识别领域的基准数据集。从 2016 年到现在,大家已经引用了 4230 多次。今年,我们与北京大学合作,提出了更大的基于图像的行人再识别数据集——MSMT17。收集 MSMT17 数据集的时候,我们用了分别部署在教学楼室内和室外的 15 个摄像头,在不连续的四天中的上午、中午和下午三个时刻进行拍摄。最终收集了 4000 多个人,标注 12 万多张行人图片。此外,在 ECCV2016 和 CVPR2017 上,我们也发表并公开做了基于视频的行人再识别数据集 MARS,以及端到端的行人再识别的检索数据集 PRW。因此,过去这几年我们主要做了 4 个行人再识别数据集,很好地推进了行人再识别的发展。
除了从构建更大更真实数据集的角度来应对大量训练数据需求的挑战,我们还可以通过数据生成的方法,来增加训练数据量。数据生成有传统方法和深度学习方法。比如说对图像进行一些操作像翻反转、剪裁、构建金字塔输入等,这些都是被广泛采用的传统方法。近年来,深度学习的方法主要是 GAN-based 方法。生成对抗网络(GAN)在行人再识别上的第一个工作发表在 ICCV2017 上,作者他用 DCGAN 生成没有标注的行人数据,来进行数据增强。这个工作的但问题是,DCGAN 生成的行人图片质量是比较低的。针对训练集中行人姿态变化不够的情况,CVPR2018 上,上海交大的倪冰冰老师团队用条件 GAN 来生成具有不同姿态的行人图像,以丰富训练集中行人的姿态变化。只不过,同样的问题是生成的图像质量比较低。另外, CVPR2018 中有团队做相机风格的学习。比如说从第一个摄像头拍到的真实图像,转移到第六个摄像头相机下,或者是第六个相机的图像转移成具有第一个相机风格的图像。通过这种方式,我们的训练集就会更加均衡地囊括场景中各个相机的风格,在测试阶段具备更好的性能。
我们在今年 CVPR2018 提出了 PTGAN(Person Transfer GAN)。PTGAN 主要做跨场景的迁移,假设我们在北京标注的训练数据想在上海的某个场景下用,我们就可以通过 PTGAN 将已经标注好的数据迁移到上海的场景中,迁移后的图片就像在上海拍摄一样。然后我们在迁移后的数据集上训练行人再识别模型,这样会在上海的场景中得到更好的性能。PTGAN 的实现主要基于两个损失函数:风格迁移和行人保持。风格迁移的目的是我们迁移后的图片风格尽可能和目标场景一致,而行人保持的目的是迁移后的图片中行人没有发生改变。我们在不同数据集上都做了相关实验,性能都有相当大的提高。

应对行人表观信息变化大的挑战主要解决方案,集中在如何提出更好的行人特征表达上,传统方法中我们利用颜色特征、纹理特征、距离传统度量学习等。对于深度学习方法,除了利用现有的深度学习网络框架以外,主要是设计不同的损失函数来进行优化,包括 Softmax Loss、二元组、三元组、四元组的损失函数等。
最后应对非理想场景的挑战,主要解决方案是对人体部件进行检测和匹配。我们在 ICCV2017 提出了 Pose-Driven Convolution (PDC) 方法来提取人体的细粒度部件,并进行矫正。但是由于需要提取非常精细的人体的部件, PDC 对遮挡以及人体关键点检测误差比较敏感。基于此,我们在 MM17 中提出了 Global-Local Alignment Descriptor(GLAD) 的方法,仅需提取三个粗粒度部件就能得到非常好的性能。


当然最近大家也还都提出非常好的基于人体部件的方法,进一步提升行人再识别的性能,如 AlignedReID 等。
谈及行人再识别未来的方向,肯定离不开两个方面:数据和方法。在数据层面,一方面我们要构造更真实更大的数据集,另一方面也可以通过 3D Graphics 相关方法做数据生成。在方法层面,我们之前仅仅考虑视觉信息。其实现实世界中我们还可以获得大量其它信息加以利用,如 wi-fi 接入网络、步态 gait、GPSgps 等等。另外在现实应用中,行人检测和再识别其实是一体的, 应该在一个框架下统一优化。目前在这方面的工作还有所欠缺,未来我们会重点研究这一方向。

最后我介绍一下当前华为诺亚方舟实验室的情况。诺亚方舟实验室的研究工作主要是集中在五个方向,包括计算机视觉、自然语言处理、决策与推理、搜索与推荐,AI 基础理论等。在计算机视觉方面主要是做平安城市、终端视觉等方向的工作。目前实验室与十个国家超过 25 个大学有合作。诺亚方舟实验室在国内主要是深圳、北京、上海、西安,海外主要在多伦多、硅谷、伦敦、巴黎和蒙特利尔。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 七牛云
七牛云
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675