
蓝色di雪球:安全扫描自动化检测平台建设(Web黑盒上)
Web扫描平台的发展
1.原始社会
在Web安全兴起的初期,国内的工具相应缺乏,笔者曾经获取一个注入点数据库的MD5需要手工注入半天时间。
于是相应的安全扫描自动化工具应运而生,其中杰出代表莫过于啊D,穿山甲,和JSKY。感谢前辈给我们创造的自动化工具。这几款工具,可以列入中国网络安全的发展历史。
2.拿来主义
国内乙方厂商,如绿盟,启明星辰当时已经有了自己的扫描器产品,但是一般的安全人员并不能拿到软件进行测试,所以纷纷把目光投向国外。
AWVS,WebInspect,AppScan等商业化扫描器经过国人的破解以后,被各路安全爱好者进行安全扫描,测试。至今这几款扫描器依然活跃在白帽子圈,用来进行初步的安全扫描与探测,宝刀未老。
3.工业革命
这个阶段互联网的高速发展,也更加推动安全人员研发出更符合需求的扫描器。由于现有的商业安全扫描器已经不能适应企业的规模和业务增长需求,于是大型互联网公司开始进行安全扫描器的自研工作。
以BAT为首的公司,开始了自己的扫描器自研之路。从无到有,从野路子式的作坊,一路走来,在经历了各种教训,交了学费,一次次的架构变动,才有了今天大型甲方安全扫描团队的正规军,拥有自己的设计,开发,运维,运营团队。
这个阶段,主要解决了大型互联网公司,由于公司架构、业务发展和开发技术提升等需求,衍生出安全工单,分布式扫描和动态爬虫模块。
4.未来世界
公司业务和人员规模的不断扩大,安全技术的持续提升等原因,产生了更多的漏洞和更多安全事件,所造成的损失越来越大。时代的进步,对于安全扫描系统提出了更大的挑战。
这个阶段出现了云安全扫描平台,更多的乙方公司也提供了安全扫描软件,对于一般的企业用户是够用了。
漏洞规则,资产管理,扫描性能,应急响应,安全流程,开发流程等等问题又给现有的扫描器出了难题。但是,对于大型甲方公司,这个阶段出现的云安全扫描平台,还远远不能满足需求。对安全扫描器的再次架构提升也成了这个阶段安全团队首要解决的问题。
 安全自动化扫描平台建设(扫描平台数据源)
1.动态爬虫
Web2.0技术在互联网大规模应用,使得原有的爬虫方式已经不能满足需求,主流的安全扫描器爬虫均为基于浏览器内核的动态爬虫。
主流的解析引擎选择有两种:
基于QtWebKit
基于PhantomJS
其中,PhantmJS是QtWebkit的封装,部署起来更加方便,接口也相对简单,但是其中的坑也是非常的多,建议使用QtWebKit作为动态爬虫的解析引擎。
对于某些DOM类漏洞检测的需求驱动,扫描器爬虫还需要具有Ajax解析,DOM树遍历,模拟交互,事件触发等功能,基于浏览器内核的爬虫的解析和模拟能力正好可以解决需求。
安全自动化扫描平台建设(扫描平台数据源)
1.动态爬虫
Web2.0技术在互联网大规模应用,使得原有的爬虫方式已经不能满足需求,主流的安全扫描器爬虫均为基于浏览器内核的动态爬虫。
主流的解析引擎选择有两种:
基于QtWebKit
基于PhantomJS
其中,PhantmJS是QtWebkit的封装,部署起来更加方便,接口也相对简单,但是其中的坑也是非常的多,建议使用QtWebKit作为动态爬虫的解析引擎。
对于某些DOM类漏洞检测的需求驱动,扫描器爬虫还需要具有Ajax解析,DOM树遍历,模拟交互,事件触发等功能,基于浏览器内核的爬虫的解析和模拟能力正好可以解决需求。
 并由此可以检测线上扫描无法覆盖的存储型XSS和文件上传漏洞等。该方案依然活跃在某些大型互联网公司中,缺点在于浏览器覆盖范围不全(如只覆盖Chrome),对于某些测试类型无法获取流量(如移动端)
(3)测试服务器Agent,在QA的测试服务器上安装流量获取Agent,通过安全测试平台进行Agent 的自动化安装,QA只要提交任务以后进行正常的测试,Agent就可以获取全部测试数据,并可以进行方便的任务管理。
有几个笔者踩过的坑需要注意:
(1)QA的压力测试,导致Agent占用了大量的IO,影响测试数据。通过对Agent设定QPS阈值,自动暂停流量获取,仅保留心跳功能,流量低于阈值,自动重新开启获取功能。
(2)QA测试服务器上有不止一个项目进行测试,使用端口、HOST绑定等方式,进行有效区分,不对其他测试项目造成干扰。
安全扫描自动化平台(Web黑盒上)就讲到这里了,笔者难免有些疏漏或者错误,还请指出,非常感谢。
注:
1.爬虫覆盖率的测试可以使用国际爬虫标准测试项目Wivet 地址:https://github.com/bedirhan/wivet
2.流量解析可以通过PCAP文件进行存储,笔者使用Python的httpcap进行流量数据解析,地址:https://github.com/caoqianli/httpcap
建议对该程序进行修改,符合自己的实际解析场景。
转自公众号:小米安全中心
并由此可以检测线上扫描无法覆盖的存储型XSS和文件上传漏洞等。该方案依然活跃在某些大型互联网公司中,缺点在于浏览器覆盖范围不全(如只覆盖Chrome),对于某些测试类型无法获取流量(如移动端)
(3)测试服务器Agent,在QA的测试服务器上安装流量获取Agent,通过安全测试平台进行Agent 的自动化安装,QA只要提交任务以后进行正常的测试,Agent就可以获取全部测试数据,并可以进行方便的任务管理。
有几个笔者踩过的坑需要注意:
(1)QA的压力测试,导致Agent占用了大量的IO,影响测试数据。通过对Agent设定QPS阈值,自动暂停流量获取,仅保留心跳功能,流量低于阈值,自动重新开启获取功能。
(2)QA测试服务器上有不止一个项目进行测试,使用端口、HOST绑定等方式,进行有效区分,不对其他测试项目造成干扰。
安全扫描自动化平台(Web黑盒上)就讲到这里了,笔者难免有些疏漏或者错误,还请指出,非常感谢。
注:
1.爬虫覆盖率的测试可以使用国际爬虫标准测试项目Wivet 地址:https://github.com/bedirhan/wivet
2.流量解析可以通过PCAP文件进行存储,笔者使用Python的httpcap进行流量数据解析,地址:https://github.com/caoqianli/httpcap
建议对该程序进行修改,符合自己的实际解析场景。
转自公众号:小米安全中心
安全自动化扫描平台建设(扫描平台数据源)
1.动态爬虫
Web2.0技术在互联网大规模应用,使得原有的爬虫方式已经不能满足需求,主流的安全扫描器爬虫均为基于浏览器内核的动态爬虫。
主流的解析引擎选择有两种:
基于QtWebKit
基于PhantomJS
其中,PhantmJS是QtWebkit的封装,部署起来更加方便,接口也相对简单,但是其中的坑也是非常的多,建议使用QtWebKit作为动态爬虫的解析引擎。
对于某些DOM类漏洞检测的需求驱动,扫描器爬虫还需要具有Ajax解析,DOM树遍历,模拟交互,事件触发等功能,基于浏览器内核的爬虫的解析和模拟能力正好可以解决需求。
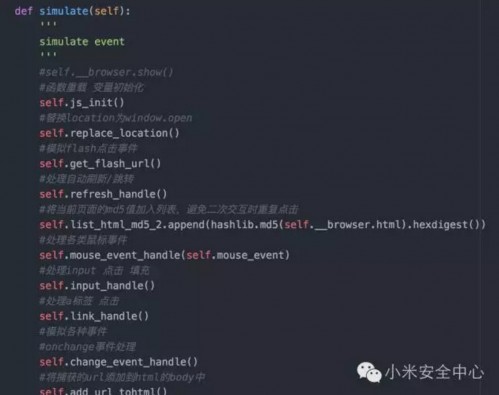
代码中模拟事件部分代码
同时,安全扫描器爬虫也需要具有伪静态解析,表单自动化填写提交等功能。 安全扫描平台爬虫模拟正常用户对目标站点进行数据爬取,但是,无法避免的会对业务产生风险,尤其是内网业务。 仅仅是进行爬取,就有可能引起以下风险 (1)写入脏数据、造成页面扭曲(尤其带cookie情况下扫描) (2)扫描请求会造成服务器额外的性能压力。 (3)如果目标站点容错性不够(如没有进行异常捕获、边界判断、空值判断等),那么爬虫请求可能会引起服务器上的程序出现异常,导致服务中断。 (4)关键业务逻辑行为是GET操作,且不需要认证(如删除数据,付款等功能)。 (5)可能会引起目标站点监控报警。 (6)扫描过程中有目录和文件猜解环节,会引起服务器大量404错误,造成大量额外日志。 以上问题都是笔者在实际设计、使用过程中遇到的问题,甚至由于安全扫描造成了严重的业务事故,由此,对扫描器爬虫提出了新的挑战。 主要提升思路是,宁可缺失少部分数据,坚决不造成业务额外的负担和风险。(注1) (1)我是自己人:使用安全爬虫专用Cookie池、请求Header,便于业务服务器辨认内部扫描爬虫,外网业务甚至可以考虑去掉登录爬虫功能。 (2)扫描限速:扫描压力控制,默认发包速率为50QPS/S,并可以根据不同的模式进行调节。 (3)内网业务扫描模式:阉割部分功能,如登录扫描、模拟交互等,原因是内网业务普遍采用CAS的方式进行登录,极少数业务有自己的用户认证系统。如果CAS用户被破解,第一波就攻击的内网业务的概率相对小,与可能造成风险相比,损失部分URL数据可以接受。 (4)去掉目录猜解功能,爬虫爬取策略向搜索引擎爬虫靠拢。 2.流量镜像 另一个非常好的数据源是主交换机,IDC交换机等网络设备流量镜像,直接将全流量镜像至安全扫描平台的流量解析节点进行分析,一般全流量镜像为GET请求,由于存储/用户隐私需求,POST请求该类型数据源不进行获取。(注2) 3.安全测试 QA测试是几乎每个互联网公司的上线前的标配,安全测试通常也会在这个环节进行,以往的该环节的自动化安全测试经过了几次发展: (1)fiddler抓取测试产生的请求数据,并发送至安全扫描器进行扫描,至今仍有部分公司使用这种方式进行安全测试。问题在于QA的学习与使用有一定的成本,部门墙比较严重的情况下,这种方式的成本有点高。 (2)浏览器插件的方式,通过在QA的浏览器安装插件,获取测试产生的流量,可以安全的获取所有测试数据。
并由此可以检测线上扫描无法覆盖的存储型XSS和文件上传漏洞等。该方案依然活跃在某些大型互联网公司中,缺点在于浏览器覆盖范围不全(如只覆盖Chrome),对于某些测试类型无法获取流量(如移动端)
(3)测试服务器Agent,在QA的测试服务器上安装流量获取Agent,通过安全测试平台进行Agent 的自动化安装,QA只要提交任务以后进行正常的测试,Agent就可以获取全部测试数据,并可以进行方便的任务管理。
有几个笔者踩过的坑需要注意:
(1)QA的压力测试,导致Agent占用了大量的IO,影响测试数据。通过对Agent设定QPS阈值,自动暂停流量获取,仅保留心跳功能,流量低于阈值,自动重新开启获取功能。
(2)QA测试服务器上有不止一个项目进行测试,使用端口、HOST绑定等方式,进行有效区分,不对其他测试项目造成干扰。
安全扫描自动化平台(Web黑盒上)就讲到这里了,笔者难免有些疏漏或者错误,还请指出,非常感谢。
注:
1.爬虫覆盖率的测试可以使用国际爬虫标准测试项目Wivet 地址:https://github.com/bedirhan/wivet
2.流量解析可以通过PCAP文件进行存储,笔者使用Python的httpcap进行流量数据解析,地址:https://github.com/caoqianli/httpcap
建议对该程序进行修改,符合自己的实际解析场景。
转自公众号:小米安全中心关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 程序猿
程序猿
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675